Section 3.5. Indexes and Foreign Keys
3.5. Indexes and Foreign KeysIt is quite customary to systematically index the foreign keys of a table; and it is widely acknowledged to be common wisdom to do so. In fact, some design tools automatically generate indexes on these keys, and so do some DBMS. However, I urge caution in this respect. Given the overall cost of indexes, unnecessarily indexing foreign keys may prove a mistake, especially for a table that has many foreign keys.
The rule of indexing the foreign keys comes from what happens when (for example) a foreign key in table A references the primary key in table B, and then both tables are concurrently modified. The simple model in Figure 3-7 illustrates this point. Figure 3-7. The simple, Master-Detail example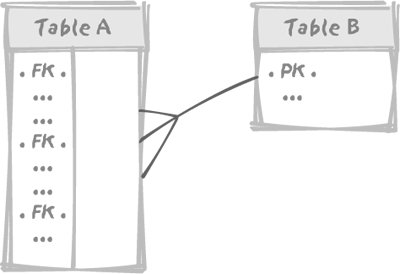 Imagine that table A is very large. If user U1 wants to remove a row from table B, since the primary key for B is referenced by a foreign key in A, the DBMS must check that removal of the row will not lead to inconsistencies in the intertable dependencies, and must therefore see whether there is any child row in A referencing the row about to be deleted from B. If there does happen to be a row in A that references our row in B, then the deletion must fail, because otherwise we would end up with an orphaned row and inconsistent data. If the foreign key in A is indexed, it can be checked very quickly. If it is not indexed, it will take a significant period of time since the session of user U1 will have to scan all of table A. Another problem is that we are not supposed to be alone on this database, and lots of things can happen while we scan A. For instance, just after user U1 has started the hunt in table A for an hypothetical child row, somebody else, say user U2, may want to insert a new row into table A which references that very same row we want to delete from table B. This situation is described in Figure 3-8, with user U1 first accessing table B to check the identifier of the row it wants to delete (1), and then searching for a child in table A (2). Meanwhile, U2 will have to check that the parent row exists in table B. But we have a primary key index on B, which means that unlike user U1, who is condemned to a slow sequential scan of the foreign key values of table A, user U2 will get the answer immediately from table B. If U2 quietly inserts the new row in table A (3), U2 may commit the change at such a point that user U1 finishes checking and wrongly concludes, having found no row, that the path is clear for the delete. Figure 3-8. Fight for the primary key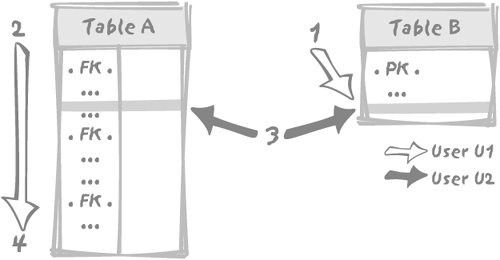 Locking is required to prevent such a case, which would otherwise irremediably lead to inconsistent data. Data integrity is, as it should be, one of the prime concerns of an enterprise-grade DBMS. It will take no chance. Whenever we want to delete a row from table B, we must prevent insertion into any table that references B of a row referencing that particular one while we look for child rows. We have two ways to prevent insertions into referencing tables (there may be several ones) such as table A:
In any case, if foreign keys are not indexed, checking for child rows will be slow, and we will hold locks for a very long time, potentially blocking many changes. In the worst case of the heavy-handed approach we can even encounter deadlocks, with two processes holding locks and stubbornly refusing to release them as long as the other process doesn't release its lock first. In such a case, the DBMS usually solves the dispute by killing one of the processes (hasta la vista, baby...) to let the other one proceed. The case of concurrent updates therefore truly requires indexing foreign keys to prevent sessions from locking objects much longer than necessary. Hence the oft heard rule that "foreign keys should always be indexed." The benefit of indexing the foreign key is that the elapsed time for each process can be drastically reduced, and in turn locking is reduced to the minimum level required for ensuring data integrity. What people often forget is that "always index foreign keys" is a rule associated with a special case. Interestingly, that special case often arises from design quirks, such as the maintenance of summary or aggregate denormalized columns in the master table of a master/detail relationship. There may be excellent reasons for updating concurrently two tables linked by referential integrity constraints. But there are also many cases with transactional databases where the referenced table is a "true" reference table (e.g., a dictionary, or "look-up" table that is very rarely updated, or it's updated in the middle of the night when there is no other activity). In such a case, the only justification for the creation of an index on the foreign key columns should be whether such an index would be of any benefit from a strictly performance standpoint. We mustn't forget the heavy penalty performance imposed by index maintenance. There are many cases when an index on a foreign key is not required. There must be a reason behind indexing; this is as true of foreign keys as of other columns. |

EAN: 2147483647
Pages: 143