2.5 Itanium Information Units and Data Types
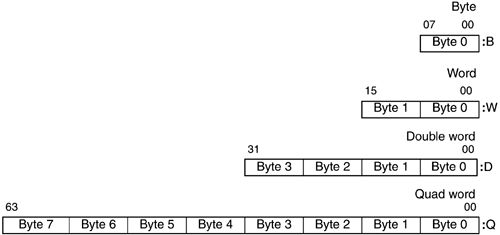
| The basic information unit for the Itanium architecture is the 8-bit byte. Individual bytes are given 64-bit addresses, but it is also important to understand that groups of adjacent bytes have addresses, as shown in Figure 2-5. These multibyte units include the 16-bit word (2 bytes), the 32-bit double word (4 bytes), and the 64-bit quad word (8 bytes). For little-endian systems, such units are addressed by the low-order byte of the group. Similarly, the addresses of the higher-order bytes within the larger information units take on successive values beyond the address of the lowest-order byte. Figure 2-5. Itanium information units
In the convention that has been used by Intel and Digital Equipment Corporation, the individual bits within any information unit are numbered from the least significant bit on the right, bit 0. The most significant bit is then bit 7 for a byte, bit 15 for a word, bit 31 for a double word, and bit 63 for a quad word. Some other machine designers, including Hewlett-Packard Company, have adopted the opposite numbering convention of naming the most significant bit on the left as bit 0. Note that the convention for the Itanium architecture does have the convenience of corresponding directly to the positional weighting scheme for evaluating binary values presented in Chapter 1. That is, the weight of bit i is 2i. The corresponding convention for ordering the bytes within words, double words, and quad words is to store the lowest order byte of the group at the lowest address. This is the little-endian convention. The opposite convention, where the highest order byte of a group is stored at the lowest address, is called big-endian, which has historically been followed by Hewlett-Packard and Motorola. When character string data are transmitted between systems, the bytes travel in the same order as letters in words and words in sentences in Western languages. But when little-endian and big-endian systems attempt to break up, say, a 32-bit binary number into four 8-bit binary bytes for sequential transmission, what one system views as WXYZ will be perceived by the other as ZYXW when reassembled. This problem affects only the byte ordering; all systems agree on the ordering (but not the numbering!) of the bits within bytes. Let us consider, as a specific example of little-endian data storage, that the quad word quantity 0x0F0E0D0C0B0A0908 is stored at address Q. Location Q is then also the address of the double word whose value is 0x0B0A0908, the word whose value is 0x0908, and the byte whose value is 0x08. In similar fashion, location Q+1 is the address of the byte whose value is 0x09, the unaligned word whose value is 0x0A09, and so forth. The Itanium instruction set uses separate opcodes (ld1, ld2, ld4, ld8) and (st1, st2, st4, st8), in order to specify what type of information unit (byte, word, double word, quad word) is to be loaded or stored in a data transfer between memory and a register. Itanium integer registers are 64 bits wide and can thus accommodate any of these four information units. The hardware design specifies precisely how to widen or narrow information of other sizes when it is placed into or retrieved from a 64-bit register. What interpretations can be made from the bit patterns stored in these information units? The fundamental data types supported by the instruction set of the Itanium architecture are integers and floating-point numbers. In some contexts, an integer will represent an address instead of a data value. In addition, a compiler program or an assembly language programmer can impart further purposes to integers for example, to represent characters or Boolean variables. 2.5.1 IntegersWe reviewed the concepts of binary representation of integers in Chapter 1. A span of N bits can be used in one of two ways: to represent a range of unsigned integers, 0 to 2N 1, or to represent a range of signed integers, 2N 1 through 0 to +2N 1 1. Table 2-1 shows the numeric ranges for the various integer sizes that are pertinent to Itanium contexts. The Itanium architecture has integer arithmetic instructions only for data of quad word width, even though the detailed operation of Itanium load and store instructions facilitates packing and unpacking information units of smaller widths. Itanium logical instructions work only with quad word data, but these instructions provide some capability for access to data packed at the bit or group-of-bits level. 2.5.2 Floating-Point NumbersSince integers may lack the dynamic range necessary for certain scientific applications, most computer architectures provide for floating-point numbers, which correspond to scientific notation. Whereas hand-held calculators display numbers as a decimal number that is multiplied by some positive or negative power of 10, computers typically represent non-integer data as a significand that is multiplied by some power of 2. The exponent and sign of a number can be bit-packed with the significand into an information unit in several ways.
In the past, various computer manufacturers represented floating-point data in ways that were not fully compatible across architectures. Accordingly, concerns arose about inaccuracies that might compound in repeated mathematical operations. Some of these difficulties fell away as the computer industry began to consolidate, but a satisfactory solution came about only through participation in the agreed-upon standards documented in ANSI/IEEE 754, IEEE Standard for Binary Floating-Point Arithmetic. Two fundamental formats have been supported by nearly every new architecture introduced since the standard emerged: single and double, requiring respectively 32 bits (4 bytes) and 64 bits (8 bytes) for storage. Two additional IEEE formats, extended single and extended double, provided some leeway within which certain older formats could be retained e.g., an Intel format requiring 80 bits (10 bytes) for storage. In this book, we shall discuss only the widely supported IEEE single and double formats for floating-point data, whose characteristics are summarized in Table 2-2. The IEEE representations not only facilitate direct interchange of data between computer systems with different architectures, but also provide for special values that could not be represented in some of the older proprietary formats. For example, special bit patterns are assigned to represent positive infinity and negative infinity. These obey standard algebraic rules, ensuring, for example, that positive infinity plus a valid finite number yields positive infinity as the sum. Other special bit patterns are called NaN, not a number. These can be used when a computed result is algebraically indeterminate, such as infinity minus infinity. Double precisionAn IEEE double-precision datum occupies 8 adjacent bytes in memory. In order to minimize the time required to load and store the datum, it should start on an address boundary that is evenly divisible by 8; that is, the datum should be naturally aligned, which is along quad word boundaries for the Itanium architecture. In a little-endian representation the bits are labeled from right to left, 0 through 63, as follows, where D denotes the lowest byte address of the information units storing the datum:
Bit 63 is the sign bit, bits <62:52> represent the exponent of 2 biased by addition of 1023 to the true value, and bits <51:0> represent a 52-bit fraction. If all the bits in the representation are zero, the number represented is zero by convention.
The significand is adjusted so that it consists of a leading bit of 1 to the left of an implied binary point; that is, it is scaled into the range from 1 up to (but not including) 2. For storage in the information units of memory, this logically known bit to the left of the implied binary point is not represented physically. The precision of the significand is thus one part in 253 even though only 52 bits store the fraction physically. Except for special cases, the value of the number is
where S is the sign of the number (0 for positive, 1 for negative), F is the binary fraction, 1.F is the significand, E is the true exponent, and B is the bias (equal to 1023 for double precision). In order to facilitate certain IEEE constraints on accuracy when rounding computed results, as well as to accommodate the 80-bit (10-byte) extended double-precision format brought forward from Intel's IA-32 architecture, the datapath for floating-point manipulations in an Itanium processor (including 128 floating-point registers) has a total width of 82 bits. When the various bit regions of a double-precision datum are retrieved from memory into an Itanium floating-point register, their arrangement is as follows:
The "hidden bit" that is suppressed for economy of storage in memory is thus made explicit in the representation of a floating-point number in a processor register. We defer discussion of the expansion of space for the exponent to a later chapter. Single precisionAn IEEE single-precision datum occupies 4 adjacent bytes in memory. In order to minimize the time required for loading and storing the datum, it should start on an address boundary that is evenly divisible by 4; that is, the datum should be naturally aligned (i.e., double word aligned). In a little-endian representation the bits are labeled from right to left, 0 through 31, as follows, where S denotes the lowest byte address of the information units storing the datum:
Bit 31 is the sign bit, bits <30:23> represent the exponent of 2 biased by addition of 127 to the true value, and bits <22:0> represent a 23-bit fraction. If all the bits in the representation are zero, the number represented is zero by convention. The significand is adjusted so that it consists of a leading bit of 1 to the left of an implied binary point; that is, it is scaled into the range from 1 up to (but not including) 2. For storage in the information units of memory, this logically known bit to the left of the implied binary point is not represented physically. The precision of the significand is thus one part in 224 even though only 23 bits store the fraction physically. Except for special cases, the value of the number is
where S is the sign of the number (0 for positive, 1 for negative), F is the binary fraction, 1.F is the significand, E is the true exponent, and B is the bias (equal to 127 for single precision). When the various bit regions of a single-precision datum are retrieved from memory into an Itanium floating-point register, their arrangement is as follows:
Again, the "hidden bit" that is suppressed for economy of storage in memory is thus made explicit in the representation of a floating-point number in a processor register. We defer discussion of the expansion of space for the exponent to a later chapter. The Itanium processor hardware can thus work with the same 82-bit register representation of floating-point quantities, while the memory representation takes different amounts of storage space depending on the precision required for an application. As one example, the IEEE single-precision representation for the decimal number 4.25 as it would be stored in memory can be constructed using the following steps:
After the "hidden bit" is suppressed, the binary fraction is F = 00010000000000000000000 (23 bits in all). The true exponent is 2, but with the bias of 12710 this becomes 12910 or E = 100000012. The sign is S = 0, since the number is positive. Putting all those pieces together in the order S-E-F, we have
By reclustering 4 bits at a time, we can deduce what this would look like if it were to be printed as an unsigned hexadecimal number:
Note that only a real number whose fractional part can be represented exactly as a sum of inverse powers of 2 can be stored exactly. Common decimal fractions like 0.1 or 0.7 cannot be stored exactly. As another example, the 32-bit pattern 4126000016 for a single-precision number stored in memory can be interpreted by reversing the steps just illustrated:
Conversions for double-precision numbers would proceed in a similar fashion. 2.5.3 Alphanumeric CharactersBinary numbers can encode any information, including alphanumeric characters (letters and numerals) and punctuation marks. The development of coded character sets is an old and continuing story. Morse code for telegraphy in the nineteenth century, the use of punch cards for tabulating the US census in the early twentieth century, the later spread of computer applications into business and commerce, and present requirements for encoding the character sets of all the world's written human languages all require compact and consistent encoding schemes. Providing enough codes while facilitating efficient storage and convenient sorting algorithms has led to many different systems, incompatibilities, and compromises. As a consensus, Unicode® provides methods for accommodating about a million different historical and currently used character symbols, requiring 21 bits for encoding. Several Unicode transformation formats (UTF) have been defined:
To ensure unambiguous transmission, both big-endian (default) and little-endian variants are defined for UTF-16 and UTF-32. Linux® and other contemporary programming environments support UTF-8, which can handle the full generality of Unicode definitions, while still taking advantage of the efficiency of a single-byte coding scheme when possible. The programming language Java includes Unicode support. The American Standard Code for Information Interchange (ASCII) character set includes both uppercase and lowercase alphabetic characters (A through Z, and a through z), the decimal digits (0 through 9), punctuation marks, and special control characters. The ASCII code was accepted by the American National Standards Institute (ANSI) to standardize the exchange of textual information between computers and peripherals of different manufacturers. This code exists in 7-bit and 8-bit forms; for simplicity we show the 7-bit chart that is compatible with UTF-8 as Table 2-3. Anyone even slightly familiar with world languages and cultures will perceive at a glance the inadequacy of 7-bit ASCII. There are no diacritically marked letters as used in most Western languages. The symbol $ is not universally used for currency, and the symbol ¢ is not included. Some of these needs for Western languages can be accommodated with extensions of ASCII character representations to 8 bits, but a truly global solution obviously requires Unicode.
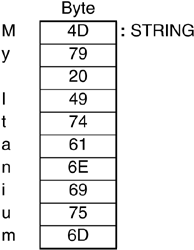
Any ASCII character-oriented peripheral device, such as a printer, will output an A when the ASCII code for A (0x41) is sent to it. Similarly, such devices should provide a horizontal space in response to the SP nonprinting character (0x20). The ASCII encoding of the string My Itanium would be as follows:
Note that each character uses one byte of storage, shown here as two hex digits. The entire string can be referenced by the address of its first byte containing the representation of the character M at the address symbolized by STRING. The arrangement of Table 2-3 makes evident the convenient feature of ASCII coding that corresponding uppercase and lowercase letters differ by only a single bit. Uppercase A is 0x41 (0100 0001), and lowercase a is 0x61 (0110 0001). This relationship simplifies case conversion or collapsing of the two cases to facilitate certain alphabetic sorting operations. About one-fourth of the 7-bit ASCII codes designate control characters intended for device control. The presence of these extra codes has given the ASCII code its versatility in such areas as the control of laboratory instrumentation through relatively simple interfaces attached to the serial communication ports of inexpensive microcomputers. Viewed as a data structure, any string has two attributes: an address and a length in bytes (or number of characters). The VAX architecture and a few others have machine instructions intended specifically for manipulating strings as a special data type. The Itanium architecture and most others typically ensure that the features of machine instructions that handle small information units (e.g., byte, word, and double word) can also handle string manipulations. Therefore, the programmer or compiler must take responsibility for managing strings as data structures. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
EAN: N/A
Pages: 223