File Security
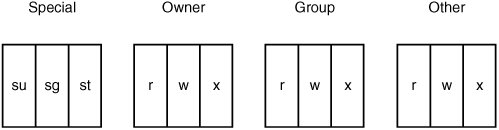
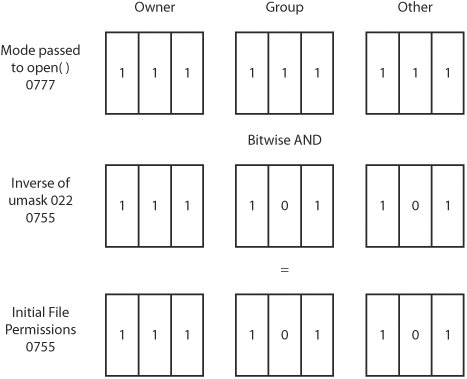
| Every file on a UNIX system has a set of attributes stored in the file system alongside the file's content. These attributes describe properties of the file, such as file size, file owner, security permissions, and access and modification timestamps. When a process attempts to act on a file, the kernel consults these file attributes to determine whether the process is permitted to proceed. The following sections describe these file attributes and explain how the kernel uses them to make access control decisions, and what kind of mistakes might be made in applications that interact with the file system. File IDsAs mentioned previously, every file in a UNIX system has an owner, who is a system user with responsibility for the file and extended control over it. Every file also belongs to a single group on the system so that the members of that group can be granted certain privileges on the file. Files have two integer attributes representing this ownership information: owner ID and group ID. The kernel sets the file's owner and group when the file is first created. The owner is always set to the effective user ID of the process that created the file. The initial group membership is a little trickier, as there are two common schemes by which the group ID can be initialized. BSD-based systems tend to set the initial group ID to the group ID of the file's parent directory. The System V and Linux approach is to set the group ID to the effective group ID of the creating process. On systems that favor effective group IDs, you can usually use the BSD-style directory inheritance approach for whole file systems via mount options or for specific directories by using special permission flags. File IDs can be changed after file creation by using the system calls chown(), lchown(), and fchown(), which permit the caller to specify a new owner ID and a new group ID. On BSD and Linux systems, only the superuser can change a file's owner. However, System V systems have historically allowed file owners to give away ownership to another user. This option is configurable system-wide in most System V derivatives, and it's disabled by default in Solaris. On most systems, the superuser and file owner can change group memberships. File owners can change a file's group only to a group of which they are a member. Again, System V derivatives, excluding Solaris, tend to allow arbitrary group changes by the file owner, but overall, this behavior is uncommon. File PermissionsFile permissions are represented by a small, fixed-width set of bits stored as a file attribute on the file system. Figure 9-1 shows the permission bitmask. It's divided into four components, each composed of three bits. Because each section is a 3-bit value with a possible range of 0 to 7, octal notation lends itself quite naturally to describing file permissions. Figure 9-1. Permission bitmasks The four components of the permission bitmask are owner permissions, group permissions, other permissions, and a set of special flags. The owner permissions apply to only one user: the owner of the file. The group permissions apply to members of the file's group, but they don't apply to the file's owner if he or she is a member of that group. The "other" permissions (sometimes known as "world permissions") apply to any other user on the system. The special component of the bitmask is a little different; it doesn't contain permissions that apply to a particular set of users; instead, it has flags indicating special file properties the kernel will honor. These special bits are discussed in more detail momentarily. Each component has three bits. For the owner, group, and other components, the three bits indicate read, write, and execute permissions. These three bits are interpreted in different ways depending on the type of the file. For a normal file, the read permission generally refers to the user's ability to open the file for reading with the open() system call. The write permission refers to the user's ability to open a file for writing with the open() system call. The execute permission refers to the user's ability to run a file as a program with the execve() system call. If a permission bit is set, it indicates that the associated privilege is granted to the associated set of users. So a file with a permission bit-string of octal 0645 (binary 000 110 100 101) indicates that none of the special bits are set, the file owner has read and write permission, members of the file's group have read permission, and everyone else on the system has read and execute permission. The kernel looks only at the most specific set of permissions relevant to a given user. This can lead to confusing situations, such as a member of the file's group being forbidden from performing an action that everyone else on the system is permitted to do or the file owner being forbidden to do something that other system users are allowed to do. For example, a file with a permission string of octal 0606 (binary 000 110 000 110) specifies that the file owner and everyone else on the system have read and write access to the file, except members of the file's group, who have no access to the file. Auditing Tip It's a common misunderstanding to think that the less specific permission bits are consulted if the more specific permissions prevent an action. The three special permission bits are the setuid bit, the setgid bit, and the sticky (or tacky) bit. If the setuid bit is set on an executable file, the program runs with the privileges of the file's owner, which means the effective user ID and saved set-user-ID of the new process are set to the file's owner ID. The setgid bit is similar: A program with the setgid bit set runs with the effective group privileges of the file's group. This means the effective group ID and saved set-group-ID of the process are set to the file's group ID. The sticky bit isn't widely used or supported for normal files, but it usually indicates that the file is heavily used and the system should act accordingly, which might entail keeping it resident in memory for longer periods. File permissions can be changed on an existing file by using the chmod() system call, which takes a filename, or the fchmod() system call, which operates on a file the process has already opened. The only two users who can change permissions on a file are the file owner and the superuser. UmaskEach process has a umask, which is a 9-bit mask used when creating files. Most file creation system calls take a mode parameter; users set this parameter to specify the 12-bit permission string they want the file to have when it's created. The kernel takes these mode permissions and uses the umask value to further restrict which privilege bits are set. So if a process tries to create a file with read and write access for all users, but the umask prohibits it, the file is created without the access bits. To calculate the initial permission bits for a new file, the permission argument of the file creation system call is calculated with a bitwise AND operation with the complement of the umask value. This process is shown in Figure 9-2. The process has a umask value of 022, which tells the kernel to turn off group write and world write permissions on any file this process creates. With the 022 umask, an open() call with a permission argument of octal 0777 results in a file being created with permissions of octal 0755. Figure 9-2. Permission bitmasks and umask A process may manually set its umask with the umask() system function. It has the following prototype: mode_t umask(mode_t mask); The umask() function will set the process umask to the 9-bit permissions string indicated by mask. This function always succeeds. A process's umask is inherited when a new program is run. You will learn more about attribute inheritance in Chapter 10, "UNIX II: Processes." If a process doesn't manually set its umask, it will likely inherit a default umask (022 in most cases). Directory PermissionsAs mentioned, directories are a special type of file for containing other files. They have a set of permissions like any file on the file system, but the kernel interprets the permission flags a little differently. If users have read permissions to a directory, they can view the list of files the directory contains. To do this, they open the directory with the open() system call, and then use a special system call to read the directory entries, such as geTDents(), readdir(), or getdirentries(). If users have write permissions to a directory, they are allowed to alter the directory's contents. This means users can create new files in the directory through several system calls, such as creat(), open(), and mkdir(). Write permissions allow users to delete files in a directory by using unlink() or rmdir() and rename files in a directory by using the rename() system call. Note that the actual permissions and ownership of the files being deleted or renamed don't matter; it's the directory file that is being altered. Execute permissions, also called search permissions, allow users to enter the directory and access files in it. Basically, you need search permissions to enter a directory and access the files it contains. If you don't have search permissions, you can't access any files in the directory; consequently, any subdirectories of that directory are also closed to you. You need search permissions on a directory to enter it with the chdir() system call. Generally, if you have write permissions on a directory, you also need search permissions on it to be able to do anything. Read permissions, however, work without search permissions. The setuid bit typically has no meaning for directories on modern UNIX systems. The setgid bit is used on some Linux and System V systems to indicate that a directory has BSD semantics. For these systems, if a directory is marked with the setgid bit, any file created in that directory automatically inherits the directory's group ID. Any directory created in one of these special setgid directories is also marked setgid. If the sticky bit is set on a directory, the directory effectively becomes "append-only." If users have write permissions on a directory, they can rename and delete files in the directory at will, regardless of the actual file's permissions and ownership. A sticky directory, however, lets users delete and rename only files they own. This permission bit is used to implement public temporary directories, such as /tmp. Because /tmp is sticky, if one user creates a temporary file in there, another random user can't come along and rename or delete it. Directory permissions are initially set just as normal file permissions are. The mkdir() system call takes the mode argument into account and further restricts permissions based on the process's current umask. Directory permissions are changed by using the same API calls used for file permissions. Privilege Management with File OperationsA process can attempt numerous actions that cause the kernel to perform a security check. Generally, creating or opening a file is subject to an access control check as well as operations that alter the directory a file resides in and operations that change file attributes. File opening is typically done with the open(), creat(), mknod(), mkdir(), or socket() system calls; a file's directory is altered with calls such as unlink() and rename(); and file attributes are changed with calls such as chmod(), chown(), or utimes(). All these privilege checks consider a file's permission bitmask, ownership, and group membership along with the effective user ID, effective group ID, and supplemental groups of the process attempting the action. The effective permissions of a process are critical for file system interaction because they determine which actions the kernel allows on certain files and affect the initial ownership and group membership of any files or directories created by the process. You've already seen how UNIX processes manage their privileges and the pitfalls these programs can encounter. Naturally, applications running with privilege have to be extremely careful about how they interact with the file system. Privilege RecklessnessThe most straightforward type of file system interaction vulnerability is one that's already been discusseda privileged process that simply doesn't take any precautions before interacting with the file system. This recklessness usually has serious consequences, such as allowing unprivileged users to read or modify critical system files. You saw an example of this in Listing 9-1, which was a vulnerability in the XFree86 server. LibrariesSometimes a program is diligent about managing its elevated privileges but can run into trouble when it relies on third-party libraries to achieve some desired functionality. Shared libraries can often be the source of potential vulnerabilities, since users of the library don't know how the library functions internally; they only know the API that the library exports. Therefore, it is quite dangerous for libraries to access file system resources haphazardly, because if the library is used in a privileged application, the library functionality could be used as a vehicle for privilege escalation. If developers aren't made aware of the potential side effects of using a particular library, they might inadvertently introduce a vulnerability into an otherwise secure application. As an example, consider the bug related to the login class capability database in FreeBSD that Przemyslaw Frasunek discovered (documented at www.osvdb.org/displayvuln.php?osvdb_id=6073). This researcher noted that both the portable OpenSSH program and the login program call various functions in libutil to read entries from the login capabilities database before they drop privileges. This behavior is dangerous because if libutil is called in a certain way, it looks in a user's home directory for a .login.conf file, which contains user-specific login capability database entries. This code is encapsulated in the libutil library, so the problem wasn't immediately obvious. Here's one of the vulnerable code excerpts from OpenSSH: if (newcommand == NULL && !quiet_login && !options.use_login) { fname = login_getcapstr(lc, "copyright", NULL, NULL); if (fname != NULL && (f = fopen(fname, "r")) != NULL) { while (fgets(buf, sizeof(buf), f) != NULL) fputs(buf, stdout); fclose(f);The intent of this code is to print a copyright message defined by the system when users log in. The name of the copyright file, if one is defined, is obtained by calling login_getcapstr(). The login_getcapstr() function, defined in libutil, pulls an entry from the login capabilities database by using the libc function cgetstr(). The database it uses is referenced in the lc argument set by a previous call to login_getpwclass(), which essentially looks in a user's home directory for the user-specific class file. Say a user creates a ~/login.conf file containing these lines: default:\ :copyright=/etc/master.passwd: If the user logs in to the system, the preceding OpenSSH code returns /etc/master.passwd as the copyright string, and the ssh daemon proceeds to open the password file as root and print its contents. File CreationApplications that create new files and directories in the file system need to be careful to select appropriate initial permissions and file ownership. Even if the process is working within a fairly safe part of the file system, it can get into trouble by leaving newly created files and directories exposed to attackers. The UNIX open() interfaceThe primary interface on a UNIX system for creating and opening files is the open() system call. The open() function has the following semantics: int open(char *pathname, int flags, mode_t mask); As you can see, open () has three parameters. The pathname and mask parameters specify the name of the file to create or open and the 12-bit permission mask to apply to the file if one is being created. (If a file is being opened rather than created, the permissions mask is ignored.) The flags parameter specifies how open() should behave. This parameter is composed of 0 or more special flag values that are OR'd together to create a bitmask. You will be introduced to these flags throughout the rest of this chapter. PermissionsWhen reviewing a UNIX application, you should ensure that reasonable permission bits are initially chosen when a file or directory is created. If the file is created with open(), creat(), or a special function such as mknod(), programmers will likely specify an explicit file creation mode, which should be easy to spot-check. Keep in mind that the creation mode specified will silently be combined with the process's umask value which was discussed previously. Although the functions mentioned here use explicit file creation modes, you will see later on in "The Stdio File Interface" that the standard C libraries provide file I/O APIs that implicitly determine permissionsa much more dangerous programming model. Forgetting O_EXCLCreating a new file is easy to get wrong. Often when a developer writes code that is intended to open a file, the same code can inadvertently open an existing file. This kind of attack is possible because the open() function is responsible for both creating new files and opening existing ones. It will do one or the other depending on which flags are present in the flags parameter. The O_CREAT flag indicates that open() should create a new file if the requested file name doesn't already exist. Therefore, any invocation of open() that has the O_CREAT flag passed to it will potentially create a new file, but also might just open an existing one if it is already there (and the calling program has sufficient access to open it). When the O_EXCL flag is used in conjunction with O_CREAT, the open() function will exclusively create a new file. If the specified file name already exists, the open() function will fail. So, if open() is called with O_CREAT but not O_EXCL, the system might open an existing file instead of creating a new one. To see how this might be a problem, consider the following example: if ((fd=open("/tmp/tmpfile.out", O_RDWR|O_CREAT, 0600)) < 0) die("open"); ...The code presented in the example creates a temporary file named /tmp/tmpfile.out. However, because the O_EXCL flag isn't specified, it is also possible that this code opens a pre-existing file if /tmp/tmpfile.out already exists. You see in "Race Conditions" later on in this chapter that attackers can use file sym-links to exploit a problem like this to force an application to open sensitive system files. Also keep in mind that if a file is opened rather than created, the permissions mask passed to open() is completely ignored. Returning to the previous code snippet, if an application created the file /tmp/tmpfile.out with restrictive permissions as shown because it was going to store sensitive data in the file, any user could access that data by creating a file of the same name first. Unprivileged OwnerApplications that run with special privileges often relinquish some or all of their privileges when performing potentially dangerous operations, such as creating or opening files. In general, this approach is reasonable, but there are definitely some pitfalls to watch out for. If the process creates a file or directory, it's created as the lesser privileged user. If it's a setuid root program, and the attacker is the lesser privileged user, this can have some serious consequences. Remember that if you own a file, you can change its group ownership and permission bitmask. Because you control the permissions, you can read, write, and truncate the file at will. Consider this code: drop_privs(); if ((fd=open("/usr/safe/account3/resultfile", O_RDWR | O_CREAT, 0600))<0) die("open"); regain_privs(); ...This code is simple, but it shows what a file creation might look like in a privilege-savvy setuid program. There may or may not be a security issue with this program; it depends on what the program does with the file later. As it's written, if the file isn't already on the file system, it's created by the call to open(). It would be owned by the attacker, who could then manipulate the file's contents and permissions at will. These actions could include changing file contents out from under the program as it worked with the file, changing permissions to prevent the program from reopening the file later, or just reading the content in the file. Directory SafetyAs discussed, a process that creates files needs to make sure it chooses an appropriate set of permissions and an appropriate owner and group for the file. This is not an application's only concern, as directories containing the file are also key to the file's overall security. If the new files are created in a directory that's writeable by an unprivileged user, the program needs to be capable of dealing with attackers doing things such as deleting files it creates, creating files with names that conflict with names the program is using, and renaming files after the program creates them. You see some examples of these attacks in "Links" and "Race Conditions" later in this chapter. If the directory is writeable by an attacker but is a sticky directory, the program is still in dangerous territory, but it doesn't need to worry about attackers renaming or deleting its files after it successfully creates them. However, it can run into plenty of trouble when creating these files, which you'll also see in "Race Conditions" later in this chapter. If the containing directory is actually owned by the attacker, the program has a different, yet equally serious, set of problems to worry about. An attacker who owns the directory can change the file permissions and group ownership of the directory to lock the process out or prevent it from doing certain actions at certain times. Parent DirectoriesFor a file to be safe, it isn't enough for it to be created securely and be in a secure directory. Every directory referenced in the filename has to be equally safe. For example, say a program works with a file in this location: /tmp/mydir/safedir/safefile. If safedir and safefile are secure and impervious to attack, but unprivileged users have ownership or write access to mydir, they can simply rename or remove the safedir enTRy and provide their own version of safedir and safefile. If the program uses this pathname later, it refers to a completely different file. This is why it's important for every directory to be secure, starting at the file's parent directory and going all the way up to the root directory. Filenames and PathsYou already know about pathnames, but in this section you revisit them, focusing on security-relevant details. A pathname is a sequence of one or more directory components separated by the directory separator character, /. The pathname, like any other C string, is terminated with the NUL character (\x00). A pathname tells the kernel how to follow a path from a known directory location to a file or directory by traversing through the directory tree. For example, a pathname of /home/jm/test tells the kernel it should start at the root directory (/), then go to the home directory, then go to the jm directory, and then open the test file. The terminology for files and paths isn't set in stone. Some sources separate a pathname into two parts: a path and a filename. In this context, the path is every directory component in the pathname except the last one, and it tells the kernel how to get to the directory containing the requested file. The filename is the last directory component, which is the name of the file in that directory. So the file referenced by the /home/jm/test pathname has a path of /home/jm/ and a filename of test. In practice, however, most people use the terms "pathname" and "filename" interchangeably. Usually, the term "path" indicates the directory containing a file, but it's also used when talking about any pathname that refers to a directory. There are two kinds of paths: absolute and relative. Absolute paths always start with the / character, and they describe how to get from the root directory, which has the name /, to another file or directory on the file system. Relative paths start with any character other than / or NUL, and they tell the kernel how to get from the process's current working directory to the target. Every directory has two special entries: the . enTRy, which refers to the directory itself, and the .. enTRy, which points to its parent directory. The root directory, which has a name of /, has a special .. entry that points back to itself. Files can't contain the / character in their names, nor can they contain the NUL character, but every other character is permitted. More than one slash character in a row in a pathname is treated as just one slash, so the path /////usr////bin//// is the same as /usr/bin. If the pathname refers to a directory, generally it can have any number of trailing slashes because they're effectively ignored. Say you have the pathname /usr/bin/find. Because it begins with a /, you know that it's an absolute path that tells the kernel how to get to the find program from the root directory. /./////././usr/bin/../share/../bin/find is also an absolute path that references the same file, although it does so in a more circuitous fashion. If the currently running process has its current working directory set to the /usr/bin directory, perhaps as a result of using chdir("/usr/bin"), the relative pathname find references the program, as does ./find or ../../../../../../usr/bin/find. It might seem strange, but every time you use a system call that takes a pathname, the kernel goes through the process of stepping through each directory to locate the file. For the kernel to follow a path, you must have search permissions on every directory in that path. A lot of caching goes on to avoid a performance hit, but it's worth keeping that behavior in mind when you look at some of the attack vectors later in this section. Pathname TricksMany privileged applications construct pathnames dynamically, often incorporating user-malleable data. These applications often do sanity checking on constructed filenames to ensure that they're in a safe location or don't contain any malicious components. For example, imagine you have a privileged program that can be used to parse special data files, but these data files can be located in only two directories. The program contains the following code: if (!strncmp(filename, "/usr/lib/safefiles/", 19)) { debug("data file is in /usr/lib/safefiles/"); process_libfile(filename, NEW_FORMAT); } else if (!strncmp(filename, "/usr/lib/oldfiles/", 18)) { debug("data file is in /usr/lib/oldfiles/"); process_libfile(filename, OLD_FORMAT); } else { debug("invalid data file location"); app_abort(); }Suppose this program takes the filename argument from users. The code tries to ensure that the pathname points to a safe location by checking the filename's prefix to make sure it points to an appropriate directory in /usr/lib, for which users shouldn't have write access. Users could potentially bypass these checks by providing a filename such as the following: /usr/lib/safefiles/../../../../../../../../etc/shadow This filename would pass the filename check, yet still make the privileged application open the shadow password file as its data file, which is likely to have exploitable consequences. An old Linux version of tftpd had a vulnerability of this nature that a researcher named Alex Belits discovered. The following code from tftpd is supposed to validate a filename (taken from his original bugtraq post, archived at http://insecure.org/sploits/linux.tftpd.dotdotbug.html): syslog(LOG_ERR, "tftpd: trying to get file: %s\n", filename); if (*filename != '/') { syslog(LOG_ERR, "tftpd: serving file from %s\n", dirs[0]); chdir(dirs[0]); } else { for (dirp = dirs; *dirp; dirp++) if (strncmp(filename, *dirp, strlen(*dirp)) == 0) break; if (*dirp==0 && dirp!=dirs) return (EACCESS); } /* * prevent tricksters from getting around the directory restrictions */ for (cp = filename + 1; *cp; cp++) if(*cp == '.' && strncmp(cp-1, "/../", 4) == 0) return(EACCESS);If the filename's first character is a slash, tftpd assumes the directory is an absolute path and checks to make sure the initial directory matches up with one it knows about. If the filename's first character isn't a slash, ttfpd assumes it's a relative pathname, referring to a file in the first predefined directory. The code then checks that the filename doesn't contain any /../ sequences; if it does, the filename is rejected as being an attack attempt. The problem is that if the filename starts with the characters ../, it isn't caught by the check, and remote users can retrieve arbitrary files from the system by recursing out of the tftp directory, which is usually /tftpd. Embedded NULThe NUL character terminates a pathname, as a pathname is just a C string. When higher-level languages interact with the file system, however, they mostly use counted strings and don't use a NUL character to indicate string termination. Java, PHP, Visual Basic, and Perl programs can often be manipulated by passing filenames containing embedded NUL characters. The programming language views these characters as part of the pathname, but the underlying OS views them as a terminator. You delve into this pathname-related issue in Chapter 8, "Strings and Metacharacters." Dangerous PlacesThe file system of a multiuser UNIX machine is much like a modern metropolis; most neighborhoods are safe, assuming you don't do anything stupid, but in a few parts of town, even the police warn you not to stop at traffic lights. On a UNIX machine, the "safe neighborhoods" are like gated communities: directories and files that only you and your trusted friends have control over. "Doing something stupid" would include creating new files and directories with insufficient permissions, the digital equivalent of not locking your doors. It would also include asking potentially malicious users for input on which files to process, which is akin to asking a thief to help you find a good place to hide your money. The dangerous parts of town would correspond to public directories that can be a bit scary on large multiuser boxes, such as /tmp, /var/tmp/, and the mail spool directory. In general, an application can be fairly insulated from file-related vulnerabilities if it stays within the safer parts of the file system. For example, if a program interacts with the file system just to read static files owned by privileged users, such as configuration files in /etc, it's likely to be immune to tampering from malicious third parties. If an application has to do more involved file system interaction, but it works with files in a safe location and makes sure to create and manipulate new files and directories safely, it's still likely to be safe. Any time a program has to go beyond these simple use cases, it runs into potential problems with malicious third parties manipulating the file system out from under it. From this perspective, potentially vulnerable programs are those that have to interact with files and directories in hostile locations on the file system. A hostile location is a place where other users and programs can interfere with, manipulate, interrupt, or hijack the use of files. The following locations are potentially hostile:
Interesting FilesA typical UNIX system has several files and directories that are interesting to code auditors because they contain secret information or configuration or control data for privileged programs, encapsulate hardware or kernel objects, or have behaviors or attributes that could be leveraged in an attack. When you're auditing code, having a general knowledge of what exists on a typical UNIX system is useful because this information can help you brainstorm potential attacks. The files covered in the following section are by no means an exhaustive list of potentially risky files, but they address some of the more interesting places in the file system. System Configuration FilesConfiguration files in /etc/ are generally a good target for attackers. Certain daemons, such as radius, OpenSSH, VPN daemons, and ntpd, might use shared secrets or private keys to encrypt network communication. Attackers who can read the configuration files containing these secrets might be able to launch an attack against the service or its clients. In general, being able to write to configuration files often leads to security exposures, and being able to corrupt or delete them often disables a system. The following list describes some commonly targeted files and explains the advantages attackers might gain from accessing them:
Personal User FilesPersonal user files might also be of interest to attackers, because there are not only sensitive files in a typical user's directory, but also configuration files that are used by various applications on the system. This list is a brief summary of some interesting personal user files:
Program Configuration Files and DataProgram-specific configuration files and data can also be useful to attackers. Reading configuration files might enable them to find weaknesses or sensitive information that can be used to achieve a higher level of compromise. Modifying file data usually has more immediate and drastic consequences, such as gaining privileges of the application using the configuration file. The following list describes some configuration and data files that would be of interest to an attacker:
Log FilesLogs sometimes contain sensitive information, such as users' passwords if they mistakenly enter them at a username prompt. Editing logs allows attackers to cover up evidence of any attack behavior. Log files are often in subdirectories of /var, such as /var/log. Program Files and LibrariesBeing able to write over a program file or library can almost certainly lead to a privilege escalation. For example, in a BSD system, the pwdb_mkdb program runs as root when users modify their account information entry in the password file. Users who can overwrite this binary could run arbitrary code in the context of the root user. Similarly, if attackers can write over shared libraries, they can potentially insert code that's run by multiple programs across the machine. Kernel and Boot FilesIf attackers can write to the kernel file or files used in the booting process, they can potentially insert or modify code that's used the next time the machine is rebooted. Device FilesAs mentioned, device files look just like regular files available to users on the file system, except they access devices rather than regular files. The device files present on a UNIX system vary widely depending on the UNIX variant, but some common ones are listed here:
Named PipesProviding named pipes instead of regular files could be of interest to attackers, particularly for timing-based attacks (discussed in the IPC section in Chapter 10, "UNIX II: Processes"). In addition, if an application opens a named pipe, it allows the owner of the pipe to deliver the SIGPIPE signal, which could be used to perform a signal-based attack. Signals are covered in depth in Chapter 13. The Proc File SystemSome UNIX OSs provide other interesting files in /proc that could be leveraged for file-based attacks. For example, a daemon running as an unprivileged user has permissions to read its own /proc/pid/mem filea virtual file that can be used to read and write to the current process's memory. If the daemon is tricked into reading this file and outputting the results, it could leak sensitive information to users. Another useful file in the proc file system is the kcore file, which could be used to read sensitive data in kernel memory. |
EAN: 2147483647
Pages: 194