File Internals
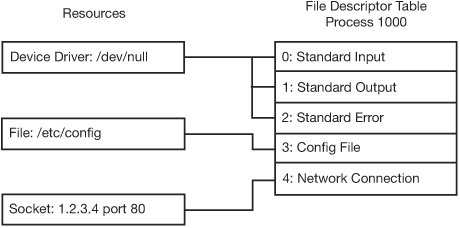
| When you're studying complex file vulnerabilities, such as race conditions and linking attacks, having a basic grasp of UNIX file internals is useful. Naturally, UNIX implementations differ quite a bit under the hood, but this explanation takes a general approach that should encompass the major features of all implementations. This discussion doesn't line up 100% with a particular UNIX implementation, but it should cover the concepts that are useful for analyzing file system code. File DescriptorsUNIX provides a consistent, file-based interface that processes can use to work with a fairly disparate set of system resources. These resources include files, hardware devices, special virtual devices, network sockets, and IPC mechanisms. The uniformity of this file-based interface and the means by which it's supported in the kernel provide a flexible and interoperable system. For example, the code used to talk with a peer over a named pipe could be used to interact with a network socket or interact with a program file, and retargeting would involve little to no modification. For every process, the UNIX kernel keeps a list of its open files, known as the file descriptor table. This table contains pointers to data structures (discussed in more detail in Chapter 10) in the kernel that encapsulate these system resources. A process generally opens a normal, disk-backed file by calling open() and passing a pathname to open. The kernel resolves the pathname into a specific file on the disk and then loads the necessary file data structures into memory, reading some information from disk. The file is added to the file descriptor table, and the position, or index, of the new entry in the file descriptor table is handed back to the process. This index is the file descriptor, which serves as a unique numeric token the process can use to refer to the file in future system calls. Figure 9-3 shows a file descriptor table for a simple daemon. File descriptors 0, 1, and 2, which correspond to standard input, standard output, and standard error, respectively, are backed by the device driver for the /dev/null file, which simply discards anything it receives. File descriptor 3 refers to a configuration file the program opened, named /etc/config. File descriptor 4 is a TCP network connection to the 1.2.3.4 machine's Web server. Figure 9-3. Simplified view of a file descriptor table File descriptors are typically closed when a process exits or calls close() on a file descriptor. A process can mark certain file descriptors as close-on-exec, which means they are automatically closed if the process executes another program. Descriptors that aren't marked close-on-exec persist when the new program runs, which has some security-related consequences addressed in Chapter 10. File descriptors are duplicated automatically when a process uses a fork(), and a process can explicitly duplicate them with a dup2() or fcntl() system call. InodesThe details of how file attributes are stored are up to the file system code, but UNIX has a data structure it expects the file system to be able to fill out from its backing data store. For each file, UNIX expects an information node (inode) that the file system can present. In the more straightforward, classic UNIX file systems, inodes are actual data structures existing in physical blocks on the disk. In modern file systems, they aren't quite as straightforward, but the kernel still uses the concept of an inode to track all information for a file, regardless of how that information is ultimately stored. So what's in an inode? Inodes have an inode number, which is unique in the file system. Every file system mounted on a UNIX machine has a unique device number. Therefore, every file on a UNIX system can be uniquely identified by the combination of its device number and its inode number. Inodes contain a file type field that can indicate the file is an ordinary file, a character device, a block device, a UNIX domain socket, a named pipe, or a symbolic link. Inodes also contain the owner ID, group ID, and file permission bits for the file as well as the file size in bytes; access, modification, and inode timestamps; and the number of links to the file. The term "inode" can be confusing, because it refers to two different things: an inode data structure stored on a disk and an inode data structure the kernel keeps in memory. The inode data structure on the disk contains the aforementioned file attributes as well as pointers to data blocks for the file on the disk. The inode data structure in kernel memory contains all the disk inode information as well as additional attributes and data and pointers to associated kernel functions for working with the file. When the kernel opens a file, it creates an inode data structure and asks the underlying file system driver to fill it out. The file system code might read in an inode from the disk and fill out the kernel's inode data structure with the retrieved information, or it could do something completely different. The important thing is that for the kernel, each file is manipulated, tracked, and maintained through an inode. Inodes are organized and cached so that the kernel and file system can access them quickly. The kernel primarily deals with files using inodes rather than filenames. When a process makes a system call that has a pathname argument, the kernel resolves the pathname into an inode, and then performs the requested operation on the inode. This explanation is a bit oversimplified, but it's enough for the purposes of this discussion. Anyway, when a file is opened and stored in the file descriptor table, what's placed there is a pointer to a chain of data structures that eventually leads to the inode data structure associated with the file. Note Chapter 10 explains the data structures involved in associating the file descriptor table with an inode data structure. These constructs are important for understanding how files and file descriptors are shared among processes, but you can set them aside for now. DirectoriesA directory's contents are simply the list of files the directory contains. Each item in the list is called a directory entry, and each entry contains two things: a name and an inode number. You might have noticed that the filename isn't stored in the file inode, so it's not kept on the file system as a file attribute. This is because filenames are only instructions that tell the kernel how to walk through directory entries to retrieve an inode number for a file. For example, specifying the filename /tmp/testing/test.txt tells the kernel to start with the root directory inode, open it, and read the directory entry with the name tmp. This information gives the kernel an inode number that corresponds to the tmp directory. The kernel opens that inode and reads the entry with the name testing. This information gives the kernel an inode number for the testing directory. The kernel then opens this inode and reads the directory entry with the name test.txt. The inode number the kernel gets is the inode of the file, which is all that the kernel needs for operating on the file. Figure 9-4 shows a simple directory hierarchy. Each box represents an inode. The directory inodes have a list of directory entries below them, and each ordinary file inode contains its file contents below its attributes. The figure shows the following simple directory hierarchy: fred.txt jim/ bob.txt Figure 9-4. Directories at play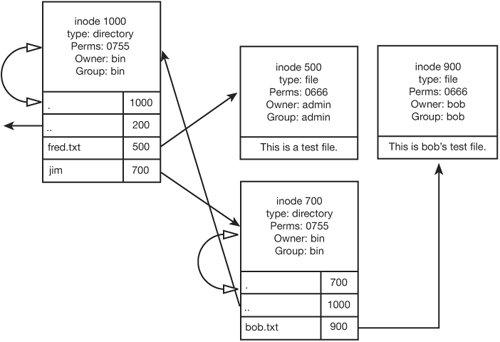 The leftmost inode is a directory containing the fred.txt file and the jim directory. You don't know this directory's name because you have to see its parent directory to learn that. It has an inode number of 1000. The jim directory has an inode of 700, and you can see that it has only one file, bob.txt. If a process has a current directory of the directory in inode 1000, and you call open("jim/bob.txt", O_RDWR), the kernel translates the pathname by reading the directory entries. First, the directory at inode 1000 is opened, and the directory entry for jim is read. The kernel then opens the jim directory at inode 700 and reads the directory entry for bob.txt, which is 900. The kernel then opens bob.txt at inode 900, loads it into memory, and associates it with an entry in the file descriptor table. |
EAN: 2147483647
Pages: 194