12.4 EJB Antipatterns
| Our final set of antipatterns deal with Enterprise JavaBeans. EJBs are a powerful technology, but can also be complicated and heavyweight. Two of our antipatterns deal with the complexity of EJBs: the Everything Is an EJB antipattern describes when EJBs are appropriate to use at all, while the Stateful When Stateless Will Do antipattern describes when stateful session EJBs should be used. The Round-Tripping antipattern covers common performance problems in client-server applications, and often turns up when you're using remote EJBs. 12.4.1 Everything Is an EJBThere is a common antipattern called the golden hammer. A golden hammer starts life as a good solution to a recurring problem the kind of solution that design patterns are made from. Eventually, however, the golden hammer starts getting used because it is the most familiar to developers, not because it's the best solution. Like a carpenter with only one saw, the golden hammer may get the job done, but it doesn't give the cleanest or easiest cut. In many cases, EJBs are just such a golden hammer. Developers especially developers with a history of database development tend to see entity EJBs as the solution to every problem. Need security? Create a username and password bean. Need an address? Create an address bean. Unfortunately, EJBs are not the solution to every problem. Like any other technology (and EJBs are a complex technology, at that), EJBs have both costs and benefits. EJBs should only be used when their benefits outweigh the costs in solving the problem at hand. This is an important concept, so let's look at each aspect separately. The first part of applying this concept is to understand the benefits of EJBs. The central idea behind Enterprise JavaBeans, particularly entity beans, is to create an "abstract persistence mechanism." EJBs provide a generic, object-oriented way to manage data without worrying about the details of what's underneath. So we describe the data we want to store, along with transaction characteristics, security mechanisms, and so on, and the EJB container worries about translating it into whatever database or other storage mechanism we happen to use. On top of that, the container makes the beans available remotely, enforces the security constraints, and optimizes access to the beans using pools and other mechanisms. It seems like a pretty good deal. The other significant aspect of the benefit/cost concept involves understanding that there are also substantial costs to using EJBs. EJBs add significant complexity to an application. EJBs must be created, looked up, and referenced using JNDI, and a dizzying array of home, remote, and local interfaces. While containers use caching and pooling to help, EJBs are often a memory and performance bottleneck. And, of course, you often need to negotiate with the purchasing department to buy the container. Choosing whether to use EJBs comes down to one key issue: solving the problem at hand. EJBs are a great solution when their benefits line up with the features you need. If you don't need to use an existing database, using container-managed persistence can be quite efficient.[2] If you need to add transactions to otherwise transactionless storage, or add secure remote access to your data, EJBs are also a good idea. Too frequently, however, EJBs are used when none of these features are needed.
For example, let's go back to our web-based address book application based on an LDAP database. At the under-designed extreme, we have the magic servlet we saw earlier. While the magic servlet is not robust or extensible enough, solving the problem with entity EJBs is overkill. Figure 12-2 shows a sketch of the EJB solution: an address command in the presentation tier uses an address EJB, which in turn communicates with the underlying LDAP directory. Figure 12-2. A poor use of entity beans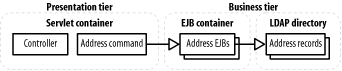 What are the EJBs adding? Chances are, the LDAP directory already provides some of the basic EJB features, such as remote access to the data, security, and maybe even transactions. If the AddressCommand is well defined, it will provide a level of abstraction between the controller and the underlying LDAP. Since we're stuck with the existing LDAP database anyway, the EJBs are not really protecting us from changes to the underlying storage. In the end, there are no real advantages to using EJBs in this case, and the costs in terms of development and performance outweigh the benefits. 12.4.1.1 Escaping EJBsWhat are our options, if EJBs are out of the picture? If it's entity beans we gave up, usually the answer is just plain JavaBeans. A command interface looks a whole lot like an EJB, anyway: there are usually setter methods to describe the arguments to the command, business methods to perform the actual command, and getter methods to read the results. We simply build a Command like we would a BMP entity bean, by communicating directly with a database. Since the fundamental bean structure is preserved, it's usually a simple task to switch back to EJBs if we need the features later. There are, of course, other alternatives. For instance, storing data in XML files or as serialized objects works for simple applications. In more complex cases, Java Data Objects (JDO) provide a simple way to persist arbitrary Java objects without many of the complexities of EJBs.[3] A flexible but more complicated option is to use a variation of the Service Locator pattern (described in Chapter 9) in conjunction with façades to hide whether beans are local or remote at all.
On the system logic side, consider turning stateful session beans to stateless session beans (see Section 12.4.3") and evaluate your stateless session beans to determine whether they should be EJBs. If not, think about replacing them with business delegates. The following criteria can help determine whether you can safely convert your session beans into business delegates:
If most or all of these conditions are true, there won't necessarily be much of a benefit to using session beans. Transaction management, in particular, is often a simpler problem than it is sometimes portrayed as: EJBs make it easy to distribute transactions across multiple resources, including databases and MOM middleware, but if all your transaction management needs are focused on simple database calls (or invoking DAOs), a transaction wrapper is often sufficient. If your session bean is acting as a session façade (see Chapter 9), look carefully at what it is providing access to. One of the prime advantages of a façade is that you can run a lot of your code much closer to the entity beans it acts on. If you aren't using entity beans, you lose this benefit. The same applies if the session façade spends most of its time dealing with resources that are themselves remote: if all the façade does is forward requests to a database, you might as well have the presentation tier connect to the database directly. Clustering is frequently cited as a reason for using both session and entity EJBs, but you'll often find in these cases that it's either entirely unnecessary or can be done more cheaply. Pointing multiple instances of a web app at the same data store might be frowned upon, but is often the easiest solution. This is particularly true if the number of total clients is small: you don't need to worry about creating infrastructure that can handle 10,000 connections at once if all you really need is to provide business services to a couple of web servers. 12.4.2 Round-TrippingCompared to the speed of local execution, using a network is extremely slow. That may sound like the sales-pitch for huge SMP servers, but it's not. Distributed architectures are essential to providing applications that scale to Internet demands. But even within a distributed architecture, performance can be dramatically improved by doing work locally. The communication between the presentation and business tiers is a common source of performance problems within distributed architectures. Whether it's remote EJBs, directories, or databases, the cost of maintaining and using remote data is easy to lose track of, especially when development takes place on a single machine. The Round-Tripping antipattern is a common misuse of network resources. It occurs when a large amount of data, like the results of a database lookup, needs to be transferred. Instead of sending back one large chunk of data, each individual result is requested and sent individually. The overhead involved can be astonishing. Each call requires at least the following steps:
Round-tripping occurs when this sequence is repeated separately for each result in a large set. The Round-Tripping antipattern is most often seen with remote entity EJBs. One of the features of EJBs is that they can be moved to a remote server, more or less transparently.[4] This power, however, is easy to abuse. Example 12-7 shows a command that reads addresses from a set of entity EJBs and stores the results locally.
Example 12-7. A PersonBean clientimport java.util.*; import javax.ejb.*; import javax.rmi.*; import javax.naming.*; import javax.servlet.http.*; public class EJBPersonCommand implements PersonCommand { private List people; private EJBPersonHome personHome; public void initialize(HttpSession session) throws NamingException { InitialContext ic = new InitialContext( ); Object personRef = ic.lookup("ejb/EJBPerson"); personHome = (EJBPersonHome) PortableRemoteObject.narrow(personRef, EJBPersonHome.class); people = new Vector( ); } // read all entries in the database and store them in a local // list public void runCommand( ) throws NamingException { try { Collection ejbpeople = personHome.findAll( ); for(Iterator i = ejbpeople.iterator(); i.hasNext( );) { EJBPerson ejbPerson = (EJBPerson)i.next( ); people.add(new Person(ejbPerson.getFirstName( ), ejbPerson.getLastName( ), ejbPerson.getPhoneNumber( ))); } } catch(Exception ex) { ... return; } } public List getPeople( ) { return people; } } The code looks innocuous enough. The PersonHome interface is used to find all people in the database, which are returned as instances of the EJBPerson EJB. We then loop through all the people, reading their various attributes and storing them in a local List. The problem is that when this client and the Person EJB are not on the same machine, each call to EJBPerson.getXXX( ) requires a call across the network. This requirement means that, in this example, we're making 3n round trips, where n is the number of people in the database. For each trip, we incur the costs of data marshalling, the actual transfer, and unmarshalling, at the very least. 12.4.2.1 Reducing round-trippingFortunately, round-tripping is not hard to recognize. If you suddenly find performance problems when you move an application onto multiple servers, or find your intranet saturated, chances are round-tripping is to blame. To reduce round-tripping, we need to combine multiple requests into one. Our options are to modify the client or modify the server. On the client side, we can implement caches to make sure we only request data once, not hundreds of times. Obviously, this will only benefit us if the data is read more often than it is changed. A more robust solution is to modify the server, letting it make many local calls before returning data over the network. In the EJB case, this involves two patterns we have already seen, the Data Transfer Object and the Façade. We replace our many remote calls to EJBPerson.getXXX( ) with a single call to a façade, which returns the data in a custom data transfer object. If it sounds complicated, don't worry, it's actually quite simple, as you can see in Figure 12-3. Figure 12-3. Reducing round-tripping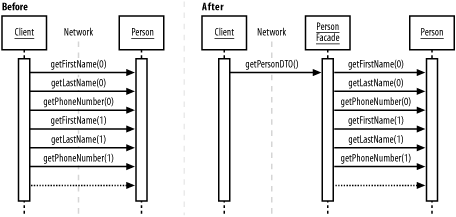 The first step is to define a DTO that encapsulates our data: public class PeopleDTO implements Serializable { private List people; public PeopleDTO( ) { people = new Vector( ); } public List getPeople( ) { return people; } public void addPerson(Person person) { people.add(person); } } The next step is our façade. The façade in this case is a full-fledged, stateless session bean. The business methods of the façade match the finder methods of the original bean. Since we got the list of people in the original bean using the findAll( ) method, we will create a matching findAll( ) method in our session bean, which is shown in Example 12-8. Example 12-8. A façade for EJBPersonimport javax.ejb.*; import java.util.*; import javax.naming.*; public class PersonFacadeBean implements SessionBean { private SessionContext context; private LocalEJBPersonHome personHome; public void setSessionContext(SessionContext aContext) { context=aContext; } public void ejbActivate( ) {} public void ejbPassivate( ) {} public void ejbRemove( ) {} // find the local bean public void ejbCreate( ) { try { String beanName = "java:comp/env/ejb/local/Person"; InitialContext ic = new InitialContext( ); personHome = (LocalEJBPersonHome) ic.lookup(beanName); } catch(Exception ex) { throw new EJBException("Error looking up PersonHome", ex); } } // find all entries and store them in a local DTO public PeopleDTO findAll( ) throws FinderException { Collection c = personHome.findAll( ); PeopleDTO dto = new PeopleDTO( ); for (Iterator i = people.iterator(); i.hasNext( );) { LocalEJBPerson ejbPerson = (LocalEJBPerson)i.next( ); dto.addPerson(new Person(ejbPerson.getFirstName( ), ejbPerson.getLastName( ), ejbPerson.getPhoneNumber( ))); } return dto; } } The session bean basically performs the same loop as we did in our original client. Notice how the session bean uses the LocalEJBPerson interface instead of the EJBPerson interface. The local interface is a feature of EJB 2.0 that allows far more efficient operation for EJBs that are known to be in the same container. Using the LocalEJBPerson interface guarantees that round-tripping will not occur while we build the DTO. The final step is the replace the original client with one using the DTO. As with the other steps, this is quite straightforward. We just replace the previous loop with a call to the façade: public void runCommand( ) throws NamingException { try { PersonFacade facade = personFacadeHome.create( ); PeopleDTO peopleDto = facade.findAll( ); people = peopleDto.getPeople( ); } catch(Exception ex) { ex.printStackTrace( ); ... } } This method traverses the network just once, no matter how big the database is. The performance improvements from reduced round-tripping can be substantial. In one unscientific test of the example above, the time to transfer 1,000 addresses was reduced from over 4 minutes to 14 seconds. In addition to the DTO pattern, you should also consider using a data transfer row set (see Chapter 7) to address these issues. 12.4.3 Stateful When Stateless Will DoIt is a common misconception that stateful and stateless session EJBs are basically the same thing. It makes sense: they're both types of session EJBs. As their name implies, stateful EJBs maintain a conversational state with clients, like a normal Java object, while stateless beans must be given all their state data each time they are called. The major difference between stateful and stateless beans, however, is how they are managed by the container. A stateless bean is relatively simple to manage. Since operations on the bean do not change the bean itself, the container can create as many or as few beans as it needs. All the copies of a stateless bean are essentially equal. Not so with stateful beans. Every time a client makes a request, it must contact the same bean. That means that every client gets its own bean, which must be kept in memory somehow, whether the client is using it or not. The necessary management and storage makes a stateful session bean far more expensive for the container to manage than a stateless one. Since stateful EJBs work more like normal objects, it's a common mistake to use them when stateless beans could be used to achieve the same effect at a much lower cost. For example, we could build an AddressBookEntry entity EJB with local home interface: public interface AddressBookEntryHome extends EJBLocalHome { // required method public AddressBookEntry findByPrimaryKey(AddressBookEntryKey aKey) throws FinderException; // find all entries in owner's address book public Collection findAll(String owner) throws FinderException; // add a new entry to owner's address book public AddressBookEntry create(String owner, String firstName, String lastName, String phoneNumber) throws CreateException; } To access this bean, we might decide to use a session bean as a façade, much like in the previous example. Unlike our previous example, however, this new façade must store the owner's name so that only entries in that user's personal address book are retrieved. We might therefore choose to build a stateful session bean, like the one shown in Example 12-9. Example 12-9. A stateful façadeimport javax.ejb.*; import java.util.*; import javax.naming.*; public class AddressBookBean implements SessionBean { private SessionContext context; private String userName; private LocalAddressBookEntryHome abeHome; public void setSessionContext(SessionContext aContext) { context=aContext; } public void ejbActivate( ) { init( ); } public void ejbPassivate( ) { abeHome = null; } public void ejbRemove( ) { abeHome = null;} public void ejbCreate(String userName) throws CreateException { this.userName = userName; init( ); } public PeopleDTO findAll(String firstName, String lastName) throws FinderException { Collection c = abeHome.findAll(userName); PeopleDTO dto = new PeopleDTO( ); for (Iterator i = people.iterator(); i.hasNext( );) { LocalAddressBookEntry entry = (LocalAddressBookEntry) i.next( ); dto.addPerson(new Person(entry.getFirstName( ), entry.getLastName( ), entry.getPhoneNumber( ))); } return dto; } private void init( ) throws EJBException { try { String name = "java:comp/env/ejb/local/Address"; InitialContext ic = new InitialContext( ); abeHome = (LocalAddressBookEntryHome) ic.lookup(name); } catch(Exception ex) { throw new EJBException("Error activating", ex); } } } As it stands, this façade must be stateful, because the userName variable is set by the initial call to create( ). If it were stateless, each call to findAll( ) could potentially be dispatched to a bean that had been created with a different username, and chaos would ensue. Unfortunately, because this bean is stateful, it requires more container resources to maintain and manage than a stateless version of the same thing. As with any stateful session bean, we have to wonder if there is a stateless bean that could do the same thing. 12.4.3.1 Turning stateful into statelessOur example is admittedly trivial, so it should be pretty obvious that a slight change to the façade's interface could allow it to be stateless. If the username was passed into each call to findAll( ), instead of the create method, this bean could be made stateless. For simple cases, it usually suffices to simply pass in all the relevant state data with each call. On more complex objects, however, this method becomes prohibitively expensive in terms of managing all the arguments and sending them over the network with each call. For these complex scenarios, there are a number of different solutions, depending on the nature of the data:
If you've considered all these solutions and stateful beans still seem most appropriate, go ahead and use them. Stateful beans can provide a big performance boost when the beginning of a multiple-request session involves creating expensive resources that would otherwise have to be reacquired with each method call. There are a whole slew of problems that stateful session beans solve. They can be a powerful tool when used properly. In this chapter, we have seen a number of common mistakes in application architecture, the presentation tier, and the business tier. While the specifics might differ, the same few principals apply to every case. Know your enemy: recognize and fix antipatterns as early as possible in the design process. Know your tools: understand how the costs and benefits of technologies relate to the problem at hand don't use them just because they are new and cool. And of course, document, document, document. |
EAN: 2147483647
Pages: 113