Section 4.3. Case Study: Usability Involvement in the Development of a Privacy Policy Management Tool
4.3. Case Study: Usability Involvement in the Development of a Privacy Policy Management ToolIn 2002, we became involved in a research project concerned with the development of approaches for helping organizations protect the personal information (PI) that they used and stored about their customers, constituents, patients, and/or employees. Most organizations store PI in heterogeneous server system environments. In our initial review of the literature and interview research, we found that organizations do not currently have a unified way of defining or implementing privacy policies that encompass data collected and used across different server platforms.[10] This makes it difficult for the organizations to put in place proper management and control of PI that allows the data users to access and work with the PI inline with organizational privacy policies. Our task was to collect data to help us understand the problem and propose solutions that would meet the needs of organizations for privacy policy management.
This work involved a wide range of user-centered techniques (discussed earlier in the chapter). This project differs from the security application presented earlier in at least three important ways; it therefore highlights the application of different usability and evaluation techniques to the creation of a privacy application:
To create technology to support all aspects of organizational development and use of privacy policies, we needed to understand the concerns of a large and diverse user group. The research included four steps:
We briefly describe these activities in the following sections, and provide a reference to a more complete description of this ongoing work. 4.3.1. Step One: Identifying Privacy NeedsOur initial work involved gathering data from people about their needs related to privacy-enabling technology. Interviews and surveys are generally appropriate methods for this stage of a project. We completed the initial interview research in two steps:
The goal of both of these activities was to create an initial draft of the requirements definition and the user profile definition. For the first step, we recruited participants from industry and government organizations who were identified as being concerned with privacy issues. These participants and their organizations represent early technology adopters concerning privacy, and we welcomed their assistance in the early identification of issues and requirements for product development. They were recruited through a variety of mechanisms including follow-ups on attendance at privacy breakout sessions at professional conferences and referrals from members of the emerging international professional privacy community. The email survey was designed to give us an initial view of the privacy-related problems and concerns that are faced by organizations. We recognized that our target user group was made up of people with highly responsible jobs and very busy schedules, so our email survey consisted of three questions carefully chosen to help us understand their perceptions of how their organizations handled privacy issues. These were:
Participants were asked to rank-order their top three choices on questions 1 and 2 from a list of choices provided, and were also allowed to fill in and rank "Other" choices if their concern was not represented in the list. For question 3, they could choose as many options as were appropriate, or choose "Other" and explain the approaches to privacy their organizations were currently using. From these questions, we learned that there were considerable similarities in organizations across the different geographies. We also learned that privacy protection of information held by organizations was crucial for both industry and government, although their concerns were slightly different. Both segments were concerned about misuse of PI data by internal employees, as well as by external users (hackers), the protection of PI data in legacy applications, and, for industry, the economic harm that a publicized privacy breach could have on their brand.[11] The top-ranked privacy functionality desired included:
The survey also gave us a picture of activities underway in organizations to address their needs. All of this data helped give us a picture of where to focus our efforts so that they might have the biggest impact in meeting user needs. 4.3.2. Step Two: Performing In-Depth Interview ResearchOur second step was to conduct in-depth interviews with target users. The goals of the interviews were to build a deeper understanding of the participants' and their organizations' views regarding privacy, their privacy concerns, and the value they perceived in the desired privacy technology they spoke of in the context of scenarios of use involving PI in their organizations. We find that having users develop and describe scenarios of use is highly effective at this stage. The majority of the interview sessions were centered on discussion of such a scenario provided by the respondent describing PI information flows in their organization. We wanted to identify and understand examples of how PI flowed through business processes in the organization, the strengths and weaknesses of these processes involving PI, the manual and automated processes to address privacy, and the additional privacy functionality they need in the context of these scenarios. We used these to create the set of core task scenarios used for the rest of the project. As in Step One, we chose the participants so that they represented a range of industries, geographies, and roles. All of the interviews were completed by telephone and lasted about an hour. The team transcribed their interview notes and discussed and annotated them to create one unified view of each session. The interviews produced large amounts of qualitative data that was analyzed using contextual analysis.[12]
In their scenarios about the flow of PI through the organizational business processes, the interviewees shared a view that privacy protection of PI depends on the people, the business processes, and the technology to support them. As the interviewees looked to develop or acquire technology to automate the creation, enforcement, and auditing of privacy policies, they noted a number of concerns at different points in the scenariofrom authoring policies to finding and deleting PI data. We noted that there are large gaps between needs and the ability of technology to meet them, particularly concerning the ability to perform privacy compliance checking. Using the information from the interviews, we created a set of core task scenarios for key domains (banking/finance, health care, and government) and updated the user profile definition and user requirements definition. We reviewed these scenarios with a subset of our participants as well as a new set of target users to confirm that the scenarios correctly captured the requirements that we had identified. We used the user requirements definitions, user profile definitions, and core task scenarios that resulted from the survey and interview research in these two steps to guide the development of the privacy management prototype in Step Three. 4.3.3. Step Three: Designing and Evaluating a Privacy Policy PrototypeUsing the completed survey and interview research, the team defined and prioritized a set of requirements for privacy-enabling tools. There were many needs that customers identified, and we decided to focus our work on providing tools to assist in several aspects of privacy policy management. We call our prototype of a privacy policy management tool SPARCLE (Server Privacy ARchitecture and CapabiLity Enablement). The overall goal in designing SPARCLE was to provide organizations with tools to help them create understandable privacy policies, link their written privacy policies with the implementation of the policy across their IT configurations, and then help them to monitor the enforcement of the policy through internal audits. The project goals at this point were to determine if the privacy functionality that had been identified for inclusion in SPARCLE from Steps 1 and 2 met the users' needs, identify any new requirements, determine the effectiveness of the interaction methods for the targeted user community, and gain contextual information to inform the lower-level design of the tool. We started with design sketches and iterated through low-fidelity to medium-fidelity prototypes, which we evaluated first with internal stakeholders and then with target customers. The first step was to sketch a set of task-based screens on paper and to discuss the flow and possible functionality associated with the task and how that should be represented in the screens. Once the team came to an agreement on these rough drawings, we proceeded to create a low-level prototype that consisted of a set of HTML screens that illustrated the steps in the user scenarios. The prototype described how two fictional privacy and compliance officers within a health care organization, Pat User and Terry Specialist, used the prototype to author and implement the privacy policies and to audit the privacy policies logs. This version of the prototype was reviewed by the team and by other HCI and security researchers internally in our organization. Based on their comments, the prototype design was updated, and it was upgraded to a medium-fidelity-level prototype by the inclusion of dynamic HTML. The prototype has many aspects that we will not try to describe here. To illustrate one the use of natural language parsing to author privacy policieswe briefly describe here how it became a part of our design. During the survey and interview research, many of the participants indicated that privacy policies in their organizations were created by committees made up of business process specialists, lawyers, security specialists, and information technologists. Based on the range of skills generally possessed by people with these varied roles, we hypothesized that different methods of defining privacy policies would be necessary. SPARCLE was designed to support users with a variety of skills by allowing individuals responsible for the creation of privacy policies to define the policies using natural language with a template to describe privacy rules (shown in Figure 4-4) or to use a structured format to define the elements and rule relationships that will be directly used in the machine-readable policy (shown in Figure 4-5). We designed SPARCLE to keep the two formats synchronized. For users who prefer authoring with natural language, SPARCLE transforms the policy into a structured form so that the author can review it, and then translates it into a machine-readable format such as XA/CML, EPAL,[13] or P3P.[14] SPARCLE translates the policies of organizational users who prefer to author rules using a structured format into both a natural language format and the machine-readable version. During the entire privacy policy authoring phase, users can switch between the natural language and structured views of the policy for viewing and editing purposes.
Once the machine-readable policy is created, SPARCLE provides a series of mapping steps to allow the user to identify where in the organization's data stores the elements of the privacy policy are stored. This series of tasks will most likely be completed by different roles in the information technology (IT) area with input from the business process experts for different lines within the organization. Finally, SPARCLE provides internal compliance or auditing officers with the ability to create reports based on logs of accesses to PI. At the same time that our iterative design was occurring, the team worked to recrui representatives from the three selected domains of health care, banking/finance, and government who would be willing to participate in design feedback sessions to evaluate the design. Our target user group was representatives from organizations in Canada, the U.S., and Europe who are responsible for creating, implementing, and auditing the privacy policies for their organizations. Note that it is a significant effort to recruit study participants, especially when the target user group is very specialized and has very limited time. We identified these individuals using a combination of methods including issuing a call for participation at a privacy session held at an industry conference, contacting and getting Figure 4-4. SPARCLE natural language privacy policy creation screen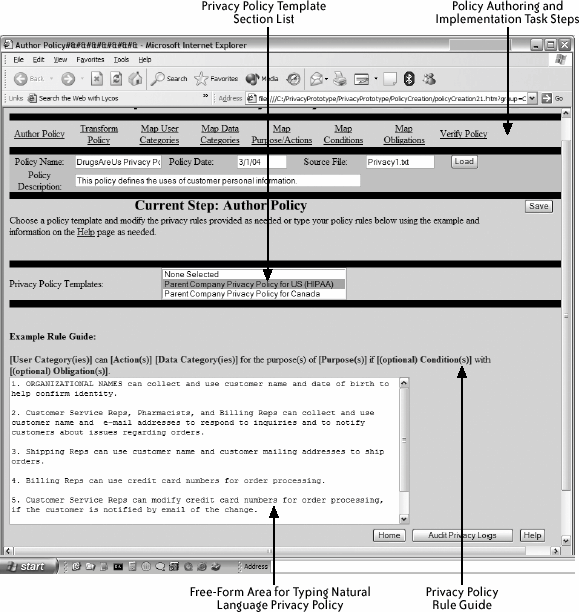 referrals from participants from the earlier studies, and employing professional and personal contacts within our department to identify potential participants. For the review sessions, we scheduled 90-minute privacy walkthrough sessions onsite at the participants' work locations. For the first iteration of the prototype, walkthrough participants (seven participants in five sessions) rated the prototype positively (an average rating of 2.6 on a 7-point scale, with 1 indicating "highest value" and 7 indicating "no value"). During the second iteration of walkthrough sessions in which we added a capability of importing organizational or domain-specific policy templates, the participants (15 participants in 6 sessions) also rated the revised prototype very positively (an average rating of 2.5 on the same scale). We present this summary result because it communicates the overall response to the prototype. However, the primary purpose for the sessions was to gather more qualitative responses from the participants about the value of the system to their task of managing privacy: what worked well, what was missing, and how they would like features designed. Figure 4-5. Expanded view of the SPARCLE structured privacy policy rule creation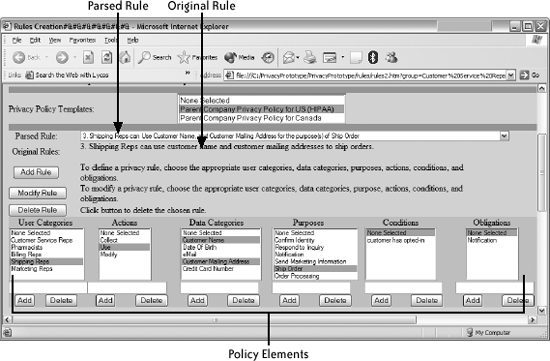 The qualitative comments were invaluable in helping us to better understand the needs of organizational users for privacy functionality and how to update the design of the prototype to better meet those needs. Based on the comments we received, we also decided to conduct an empirical laboratory usability test of the two authoring methods described in Step Four based on the feedback. 4.3.4. Step Four: Evaluating Policy AuthoringWhile formal studies have become less central to usability work than they once were, they are still an important technique for investigating specific issues. We ran an empirical usability laboratory study to compare the two privacy policy authoring methods employed in the prototype. In order to provide a baseline comparison for the two methods (Natural Language with a Guide, and Structured Entry from Element Lists), we included a control condition that allowed users to enter privacy policies in any format that they were satisfied with (Unconstrained Natural Language). We ran this study internally in our organization employing a user profile describing people experienced with computers but novices in terms of creating privacy policy rules. The results will need to be validated with the target users; however, we believed that because the crux of the study was the usability of three different methods for authoring privacy rules, the use of the novice users was appropriate. It was also an extremely practical, efficient, and cost-effective strategy, as the policy experts are a rare resource, and it would be difficult or prohibitively expensive to collect this data in a laboratory setting with them. Thirty-six employees were recruited through email to participate in the study. The participants had no previous experience in privacy policy authoring or implementation. Each participant completed one task in each of the three conditions. All participants started with a privacy rule task in the Unguided Natural Language control condition (Unguided NL). Then, half of the participants completed a similar task in the Natural Language with a Guide condition (NL with Guide), followed by a third task in the Structured Entry from Element Lists condition (Structured List). The other half of the participants completed the Structured List condition followed by the NL with Guide condition. In each task, we instructed participants to compose a number of privacy rules for a predefined task scenario. Participants worked on three different scenarios in the three tasks. We developed the scenarios in the context of health care, government, and banking. Each scenario contained five or six privacy rules, including one condition and one obligation. The order of the scenarios was balanced across all participants. We recorded the time that the participants took to complete each task and the privacy rules that participants composed. We also collected, through questionnaires, participants' perceived satisfaction with the task completion time, the quality of rules created, and the overall experience after participants completed each task. At the end of the session, participants completed a debrief questionnaire about their experiences with the three rule authoring methods. To compare the quality of the rules participants created under different conditions and scenarios, we developed a standard metric for scoring the rules. Figure 4-6 shows the quality of the rules created using each method. We counted each element of a rule as one point. Therefore, a basic rule of four compulsory elements had a score of 4, and a scenario that consisted of five rules, including one condition and one obligation, had a total score of 22. We counted the number of correct elements that participants specified in their rules, and divided that number by the total score of the specific scenario. This provided a standardized score of the percentage of elements correctly identified that was compared across conditions. The NL with Guide method and the Structured List method helped users create rules of significantly higher quality than did the Unguided NL method. There was no significant difference between the NL with Guide method and the Structured List method. Using the Unguided NL method, participants correctly identified about 42% of the elements in the scenarios, while the NL with Guide method and the Structured List method helped users to correctly identify 75% and 80% of the elements, respectively. The results of the experiment confirmed that both the NL with Guide method and the Structured List method were easy to learn and use, and they enabled participants to create rules with higher quality than did the Unguided NL method. The participants' satisfaction with both the NL with Guide method and the Structured List method provided some indication that there is value in allowing users to choose between the two methods and switch between them for different parts of the task, depending on their own preferences and skills. Other feedback from the study gave us additional guidance on where to focus on our future iterations of design. Given these results, we believe that SPARCLE is now ready to be transformed into a high-fidelity end-to-end prototype so that we can test its functionality more completely with Figure 4-6. Quality of privacy policy rules created using each method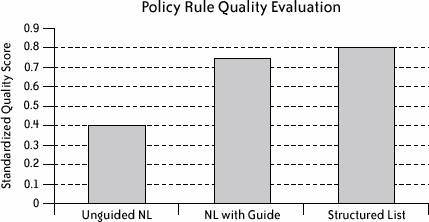 privacy professionals. While we have used predefined scenarios with predefined policies for our evaluations so far, a prototype that has been integrated with a fully functional natural language parser and a privacy enforcement engine will enable us to conduct richer and more complete tests of functionality with the participants' organizational privacy policies before moving to product-level code. |
EAN: 2147483647
Pages: 295
- Chapter III Two Models of Online Patronage: Why Do Consumers Shop on the Internet?
- Chapter XI User Satisfaction with Web Portals: An Empirical Study
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment
- Chapter XV Customer Trust in Online Commerce
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior