Section 23.3. Cookies, Web Bugs, and User Tracking
23.3. Cookies, Web Bugs, and User TrackingBugnosis defines a reasonable notion of web surveillance and alerts users when it sees it so that users can just trust the Bugnosis analysis rather than always trying to remember and imagine what's going on behind the scenes. Now, what does it really mean to say "the Web watches you read"? It's not really that complicated, but it's very easy to get bogged down in details. When a web browser fetches a web page with an HTTP transaction, the remote web server has an opportunity to log the event. In the event log, the server generally gets only these pieces of information:
Web servers are configured to record this type of information by default. For example, a recent distribution of the popular Apache web server automatically records the first four items in the preceding list.[3] You should just assume that each web site you visit creates a record of the web pages that it delivers to you.
Conspicuously missing from the preceding list are the user's real name, email address, national identity number, political affiliations, passwords, embarrassing habits, and so onthat is, the extremely sensitive personal information that an underinformed user might imagine flowing over the wire. The actual information transmitted isn't all that immediately alarming, and there is a case to be made for all of it to be there. Now, how can a web site use this information to identify a user and not just the IP address of the user's computer? Certainly some users have stable and unique IP addressesfor these folks, it could make sense to associate the user's IP address with the actual user. But a large number of us end up with dynamically assigned addresses or shared addresses because of our network provider's policies, a nearby firewall, or a network address translator. Instead of using the incoming IP address to recognize the computer's current network address, it's far more reliable to use the cookie facility to recognize the web browser itself, and associate that with the user.[4] In the next section, we'll see how it works.
23.3.1. Tracing Alice Through the WebSuppose that Alice has just bought a new computer and starts visiting web sites. The web server's algorithm for establishing and recognizing users can be extremely simple: if the web transaction arrived with a cookie then # that cookie value is this user's ID string else # it's a new user cookie := get_currently_unused_user_ID( ) return cookie to user's web browser as its new persistent cookie value endif deliver requested page Having never visited the site before (at least through this browser), Alice will get a new ID. When she returns to the site through the same browser, she'll be recognized by that automatically transmitted ID. The ID string can be used by the server as a key into a database of other information they maintain about herfor instance, any information she types into the site, such as an email address, password, or postal code. Altogether, this cookie facility only allows a server to remember something it already knows about the user behind a particular web browser: there is no way for an evil web server to use a cookie to snatch files from a user's computer, for instance. And there are plenty of good applications for cookies. Probably the most prominent applicationthe one envisioned by Lou Montulli, who invented cookies while working at Netscapewas to make it possible to implement web shopping carts: 23.3.1.1 Visiting multiple sitesIf Alice visits multiple web sites, then each of the web servers will independently create a new ID for Alice, as pictured in Figure 23-1. Figure 23-1. Sample cookies actually assigned by various web sites; in effect, each site has a different name for Alice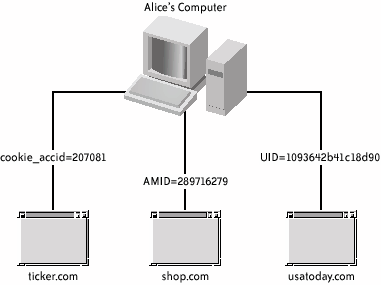 Because each web server knows Alice by a different ID, it's difficult to combine all of their records into one giant dossier of activity, even if all the servers wanted to do so. After all, if I've gathered a lot of information about Marion Morrison, and you know everything about the movie star John Wayne, would we even suspect that we could combine our information and so get a better picture of the man? We'd first have to learn that John Wayne was Morrison's stage name. Without that knowledge, we would have to treat them as two different people. This is where third-party cookies become important. 23.3.1.2 Unique identification with referrers and third-party cookiesWhenever a browser fetches web content over HTTP, it automatically sends the appropriate cookie to the destination server, even when it is getting content that wasn't explicitly requested by the user.[6] This means that when Alice loads http://www.nytimes.com/, her browser sends her nytimes.com cookie.[7] That page is delivered to her browser. Now, assuming that the page includes an instruction to fetch an image from http://m3.doubleclick.net/, her browser will go grab it automatically. But along with the request to m3.doubleclick.net, her browser will also transmit her doubleclick.net cookie along with the URL of the page whose content this transaction is part of:
Host: m3.doubleclick.net Cookie: id=80000021e26e40b Referrer: http://www.nytimes.com/ This excerpt shows that the third-party site m3.doubleclick.net receives enough information to recognize Alice by her doubleclick.net ID even though she's really just trying to visit nytimes.com, a different site altogether. Unexpectedly, a third-party image provider is actually in a better position to observe Alice's browsing than the web sites she's intentionally visiting. This is because when Alice's browser contacts the third party to obtain images, it helpfully sends them her third-party cookie ID along with the Referer line. And more to the point, every site that embeds content from doubleclick.netnot just nytimes.comwill transmit the same doubleclick.net ID. So doubleclick.net can tell that all of these transactions refer to the same person, whereas each individual site like nytimes.com could only gather data about her and file it under its own peculiar pseudonym. In other words, the third party can use a consistent name for the user, no matter what site the user is visiting. Of course, this technique allows the third party to track Alice's clickstream (the sequence of pages she visits) only on those pages that actually mention the third party. If the desired web page doesn't include any content from a third-party site, then the user's web browser has no reason to send any information at all to the third party. So, the ideal web clickstream tracker would be a third-party image provider that many different web sites use to provide their images. Two types of businesses come to mind:
23.3.2. Using Web Bugs to Enable Clickstream TrackingThe automatic transmission of third-party cookies with third-party images makes centralized clickstream tracking possible. But that doesn't mean that clickstream tracking is actually taking place. Sites contract with content delivery networks to make their sites load quickly and reliably, not necessarily to perform clickstream tracking. And third-party advertisers do provide a valuable service: they provide actual information to users and send actual customers to their clients. None of this requires them to generate or analyze user clickstream logs. For example, the DoubleClick company states in its privacy policy that it does not attempt to learn the "real-world identity" behind its cookies, and that in its role as an advertisement delivery agent, it won't use the collected information for its own business purposes. Presumably, this would include combining a user's clickstream on various unrelated client sites into one giant clickstream dossier. DoubleClick does use its cookies to remember which ads it has already shown a user, so it doesn't repeat the same one too oftenan excellent use, really. So yes, DoubleClick uses cookies, but with apparently good reason. But what if a web site doesn't care about actually displaying anything and just wants a third party to record the clickstream event? The site can still use the same cookie-laden image delivery schemeexcept that it doesn't need the image to be large or at all interesting. The standard way to do this is with a single-pixel GIF, with that pixel set to the "transparent" color. Here's an example pulled from a page at the New York Times web site: <IMG height=1 src="/books/2/176/1/html/2/http://ad.doubleclick.net/ad/N2097.nytimes.comSD6440/ B1318936.3;sz=1x1" width=1 border=0> A 1 x 1-pixel image is fairly invisible on the screen, but when it's the same color as the background, there's really no hope of seeing it. Obviously, the purpose of this image isn't really to display the invisible dot on the screen. The purpose is to inform the remote server that the user loaded the web page.[8] Otherwise, why bother with the extra work? This is a web bug. The New York Times (which placed the bug on its page) and DoubleClick (which delivered the actual invisible image) are cooperatively logging the event that the user viewed this page.
23.3.2.1 The web bug: a definitionIn Bugnosis, a web bug is an image embedded on a web page that:
This isn't quite enough: web designers often put tiny images on pages in order to force the page layout engine to invoke its image alignment rules and achieve a desired presentation effect. We've tried to exclude such images from consideration by observing that they often appear multiple times on a page with the same name each time. So, in addition to the aforementioned descriptions, a web bug also:
And, finally, Bugnosis keeps a small list of regular expressions for URLs that are known to be web bugs or known not to be web bugs (the recognized property): membership in one of these lists overrides all of the other tests.[9] Together, these properties identify images that generate a loggable event at the third-party site without delivering interesting visual material.
23.3.2.2 What about second-party transactions?We don't really need to see web bugs in order to conclude that users are being watched by the second parties (the web sites that the users intend to visit). As explained previously, web sites tend to log clickstreams by default. But this ability is fundamental to the client-server architecture of the Web. There is no easy way to programmatically determine whether a web site is interested in the tracking, or whether it actually does record it. When we see web bugs, we see evidence that a site has established a business relationship for the purpose of tracking its users' clickstreams. Although this could be explained by a business that does not have access to its own web server logfiles or that lacks the technical wherewithal to analyze them, usually it is because the organization wants more detail about its users than is possible from analyzing the logs alone. 23.3.3. Bugnosis: Theory of OperationBugnosis sniffs for web bugs according to the preceding definition. It watches a user browse the Web, and whenever it sees a web bug, it alerts the user. Bugnosis has absolutely no way of knowing what the third party does with the data it collects, but it can legitimately conclude that wherever there are web bugs, there is logging (or there used to be). Without focusing on web bugs, an observer would simply see a blur of third-party transactions and cookies go bybut that type of traffic flows normally and automatically, so it's not a reliable indicator of anything other than the possibility of logging. This is the primary insight behind Bugnosis: instead of trying to explain how clickstream tracking works in principle, and that it might be used to track your movements on the Web, Bugnosis just looks for indisputable evidence that the Web is watching you, and makes that visible. Web bugs are about the simplest such evidence we could imagine. Note: The last several pages described how user tracking can happen with cookies. Bugnosis takes a far simpler approach. By merely detecting web bugsevidence of interest in information about usersBugnosis avoids having to explain cookie tracking to its users. 23.3.3.1 One-sided errorsBy concentrating on web bugs, we're overlooking many other practical ways for web sites to watch people surfing the Web. For example, suppose that a web designer decided to use Cascading Style Sheets (CSS) stored on third-party servers to trigger a cookie transmission. Because CSS elements aren't images, Bugnosis won't consider them to be web bugs, even though they can be used to record exactly the same type of information as web bugs. This is a negative errorBugnosis fails to identify the surveillance element. And again, it doesn't even attempt to account for ordinary server logs at second-party web sites (the ones the users intend to visit). We designed Bugnosis to be conservative in its analysis, so negative errors are OK. We would much rather have Bugnosis underestimate the amount of intentional surveillance on the Web than have it make positive errorsthose in which it mistakenly indicates that an innocent web element is there for surveillance. 23.3.3.2 Detecting but not blocking web bugsWhen Bugnosis detects a web bug, it simply alerts the user: it does not try to interfere with the associated data flow. We really wanted Bugnosis to be a sensory booster: more like an extra pair of eyes on the back of the head than a can of Mace in the purse. Besides, given the large number of negative errors Bugnosis is bound to make, "protecting" the user by blocking a few web bugs is not likely to make much of a difference in the long run. 23.3.4. Presenting the AnalysisInstalling Bugnosis adds its functionality to Internet Explorer: there is no separate program to run. It makes itself minimally visible as a toolbar, as shown in Figure 23-2. From left to right, we see a drop-down menu button for configuration and help; a bug button ( Figure 23-2. Bugnosis toolbar summarizing analysis of the Froogle page, containing two images and no web bugs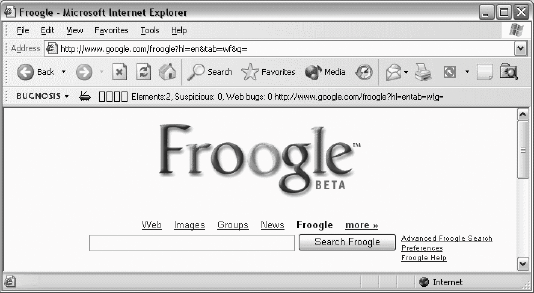 Clicking on the bug button toggles the visibility of Bugnosis's detailed analysis window. In Figure 23-3, the button is visibly depressed and the analysis is shown. Bugnosis creates its analysis as a separate HTML document consisting primarily of a table showing the analyzed web page's "interesting" elements, one per row. In this case, Bugnosis found two images. The first image was 276 x 110 pixelsdefinitely not a web bug. A reduced version of the image is also shown in the analysis window. The second image on the page is unusual: it is the result of the HTML construct <IMG height=1 alt="" width=1> which, curiously, doesn't specify a URL for the image. This image is apparently used for alignment purposes. IE considers it an incompletely downloaded 0 x 0 image, and Bugnosis considers it harmless, because it doesn't refer to a third-party site. Normally, Bugnosis wouldn't even mention these two unremarkable images, so as to avoid overwhelming the user with irrelevant detail. But in this case, we enabled the Bugnosis "List unsuspicious images" option. 23.3.5. Alerting the UserNormally, the user will browse with the analysis window closed, as in Figure 23-2. Bugnosis quietly continues to update its toolbar status line. But when it discovers a web bug on a viewed page (such as in Figure 23-4), Bugnosis:
Figure 23-3. With the bug image depressed, the Bugnosis details window takes over some browser screen space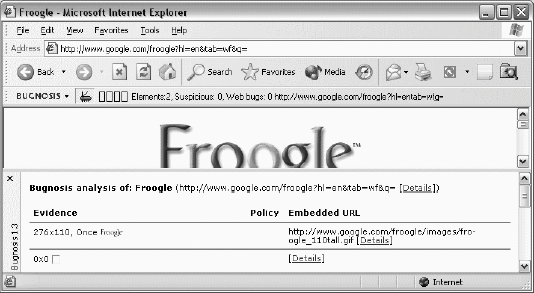 No user acknowledgment or other action is required. These are the default alerts at installation, but each of these alert methods can be configured: the sound can be changed or disabled; the automatic analysis display can be disabled; and the web bug visibility can be disabled. The toolbar can also be hidden through IE's standard View Figure 23-4 shows IE's appearance when a web bug has been found at the freedownloadscenter.com site. The severity meter on the Bugnosis toolbar is lit up with yellows and reds. The analysis window has been forced to appear, and it shows the offending image along with the names of the tests that support its conclusion. It also shows cookie information (VISID=...) in the lefthand column and the embedded image URL in the righthand column. This URL is interesting because it reveals that the freedownloadscenter.com site has grabbed the URL of its own referrer and put that into the URL of the web bug. The site is basically saying, "Someone is visiting me who came directly from www.bugnosis.org" (where there is indeed a link to the site shown). Amusingly, the third-party site is within the spylog.com domain. Now that's refreshingly transparent. Two other images with dimensions of 88 x 31 are highlighted in yellow below the web bug. They are yellow because they're merely "suspicious"because they're actually visible, they're not web bugs, even though they're able to convey just as much information as web bugs. Bugnosis presents an analysis of such images as well, but it will never alert the user without seeing an actual web bug. Note also that the web bug and the last image both contact the same third-party host, and both include an "rn=[apparently random number]" field in their embedded URL. This is probably done in order to ensure that the image transfer isn't served by a cache somewhere between the user's browser and the third-party server. A manual inspection of this page's HTML shows that all of these images were constructed by a JavaScript program that ran after the main page loaded. Figure 23-4. Bugnosis discovers a web bug and sounds an alarm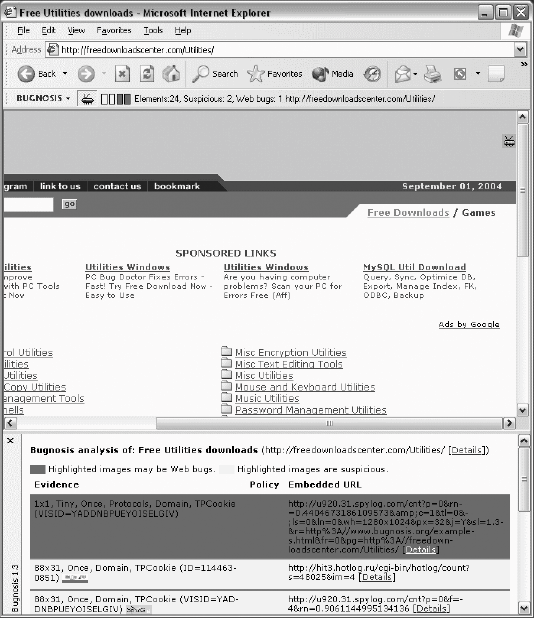 Finally, we can actually see the web bug cartoon image in the upper righthand part of the screen. When Bugnosis detected the web bug on this page, it put this image in its place. This cartoon image is an animated GIF and gallops mildly, in order to improve its own visibility. This makes the analysis seem even more real: not only is there a web bug on the page, but there it is, right there on the screen. Hovering the pointer over this image also shows some of the web bug's analysis. A lot of information is available here, but you have to drill down to see it. An ordinary user will simply hear the alarm, see a bunch of coded jargon appear, remember that he is being watched, and move on. |
 Toolbars menu.
Toolbars menu.EAN: 2147483647
Pages: 295