4.1 Multimedia Indexing
|
| < Day Day Up > |
|
4.1 Multimedia Indexing
Keywords are by far the predominant features used to index multimedia data; [2], [3], [4] that is, an indexer using keywords or a textual abstract describes the content of the media. This is state of the art as far as most conventional DBMSs are concerned.
Another method, content-based indexing, refers to the actual contents of the multimedia data. Intensive research [5], [6], [7], [8], [9], [10], [11], [12], [13], [14] has focused on content-based indexing in recent years, with the goal of indexing the multimedia data using certain features derived directly from the data.
These features are also referred to as low-level features. Examples of low-level visual features are color, shape, texture, motion, spatial information, and symbolic strings. Extracting such features may be done by an automatic analysis of the multimedia data. Section 2.5.3 explained extraction and representation methods for color in MPEG-7. Low-level features for audio are waveform and power (basic ones), spectral content, and timbre.
Indexing high-level features of audiovisual content is an active research area. Different detection mechanisms have been proposed for segmenting the multimedia material into regions of interest (moving regions for videos, parts of audio segments) and for attributing semantic meaningful annotation to each region and their relationships. In addition to this, and related to the previous issues, ongoing research concentrates on multimedia classification; for example, is this video a sport video? and more specifically, is this sport video a basketball video? The recognition of a video as basketball video facilitates the semantic annotation process, as we know what kind of objects and persons might appear.
Exhibit 4.2 gives an overview of different detection methods applied and points out their relationships. Multimedia classification is used for both visual and audio material. For videos, first the genre of interest is detected, for example, news, commercial, cartoon, tennis, and car racing (coarse grain), and then, in a fine-grain classification, one may divide sports videos into basketball, football, and so forth. [15] For audio, classification by genre, such as pop, rock, and so on, is of interest.
Exhibit 4.2: Overview of high-level multimedia indexing.
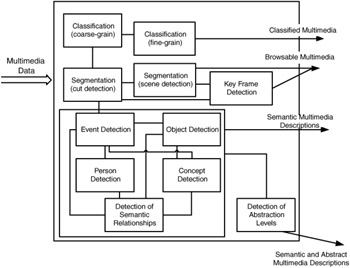
Effective multimedia classification needs the help of a knowledge base that details the possible meaning of the low-level and high-level features extracted. Multimedia classification is used for browsing and prefiltering in searching applications and may also serve as an input to multimedia segmentation, which tries to identify meaningful segments. This can be done by detecting abrupt changes in time or space (called cut detection for continuous streams) or by detecting scenes (segment boundaries are separated by different semantic content). The core of the high-level indexing process is the detection of events, objects, persons, concepts, and their relationships. The detection tools depicted in Exhibit 4.2 are in strong relationship to the entities defined in the MPEG-7 semantic description scheme (DS), as described in section 2.5.3. Finally, abstraction layers may classify the semantic content. For instance, one describes in the lowest abstraction that a person is present in an image, in the higher abstraction one says that she is a woman, and finally in the highest abstraction one gives her a name.
It is clear that the process of high-level indexing is not an automatic process but has, in general, to be supported by manual annotation. The following paragraphs review current work in high-level multimedia indexing. We will see that for special applications, the automatic extraction methods give quite accurate indexing results.
Video classification [16] is based on different low-level characteristics performed conjointly on the audio and visual tracks of a video. Color is a good discriminator for both fine- and coarse-grain classification (e.g., football will reveal many green areas). These low-level results have to be interpreted by using a knowledge database and have to be usefully combined with results of more elaborated analysis tools; for example, caption detection with text recognition. Audio classification [17] focuses mainly on speech and music discrimination. Typical features for audio classification include cepstral coefficients, timbre, characteristics of the melody, and so on.
Multimedia segmentation is a well-known research area, and many good tools are available for both video and audio material. For video data, the video sequence is first divided into its constituent shots, using shot cut and change detection methods. [18], [19] Then, representative abstractions, mainly key frames [20], [21] are selected to represent each shot. Shot boundary detection deals with the detection of physical shot boundaries indicated by shot transitions. Most shot boundary detection techniques [22], [23], [24], [25], [26], [27] define a measure of dissimilarity between successive frames that is then compared with a given threshold. Some other techniques transform the video before applying boundary detection. For instance, in the SMOOTH implementation, [28] we applied a shape analysis before comparing successive frames. Dissimilarity values exceeding the threshold value identify shot transitions, which are characterized by camera transitions. Recently, some important contributions concentrated on shot cut and change detection on compressed videos. [29], [30] Such indexing methods are of great interest if resource availability for the indexing process is low. Once a video has been segmented, further indexing can be done on a key frame selection; for example, to generate a table of contents, [31] a video abstract, [32] or a hierarchical three-dimensional representation relying on ranked key frames. [33] Recently, in addition to key frame extraction, mosaicking of video clips has been used; [34] that is, the combination of subsequent frames to show a complete scene. In this case, frames that do not contribute to the motion of objects in the scene are discarded. For instance, Exhibit 2.7 shows the mosaic image for a 10-second short video on Pisa using an affine motion model. The mosaic has been created with the help of the MPEG-7 reference software (see Section 2.8).
For audio data, basic algorithms detect the segment boundaries by looking for abrupt changes in the trajectory of features. For instance, Tzanetakis and Cook [35] segment audio sources using spectral centroid, spectral skewness, audio flux, zero-crossing, and energy and do a peak detection on the derivative of the features with an absolute threshold. Rossignol et al. [36] use a measure of the in-harmonicity of the audio to segment transients and vibrato. Labeling the segment (as key frames in video) is done usually by attributing a note, a timbre, and a phrase to a segment.
Interesting to mention in this context is the yearly TREC (Text REtrieval Conferences) video evaluation series organized by the retrieval group of the NIST (U.S. National Institute of Standards and Technology). They call for novel video segmentation tools, which have to prove their efficiency and effectiveness on more than 120 hours of news videos. The homepage of TREC video is http://www-nlpir.nist.gov/projects/trecvid/. TREC also includes an audio segmentation track.
More precise image and video content retrieval is performed if regions of interest are extracted and indexed. The extraction process is called object segmentation and means (for images) identifying a group of pixels that have common low-level features (e.g., color and texture), and (for videos) identifying a group of pixels that move together into an object and track the object's motion. [37], [38], [39], [40] For instance, Carson et al. [41] developed an image indexing and retrieval system that relies on the notion of "blobs." Each image is segmented into blobs by fitting a mixture of Gaussians to the pixel distribution in a joint color-texture-position feature space. Each blob is then associated with color and texture descriptors. Querying is based on the user specifying attributes of one or two regions of interest. Retrieval precision is improved, compared with methods relying on the description of the entire image.
In general, object segmentation is hard to perform. Exhibit 4.3 shows a typical example using the Blobworld algorithms for object segmentation. In the first line of Exhibit 4.3, the segmentation results for a simple image, offering clear discrimination between the foreground person and the background, are shown. In the second line, the result is shown for an image in which the regions of interest overlap and no clear discrimination of the persons and the background can be detected without human interaction.
Exhibit 4.3: Examples of automatic object segmentation using the Blobworld algorithms. [42]

Audiovisual indexing can efficiently be supported by common analysis of the visual and audio content. For instance, Chang et al. [43] have developed a demonstration video database that recognizes key sporting events from the accompanying commentary. Their work is based on spotting predeterzmined keywords. The recognition of captions in a video might enhance the video indexing efficiency as well. The difficulty here is to detect the place of the captions within the video frames and to transform the caption information into semantically meaningful information; for example, names, location, and so on. For instance, Assfalg et al. [44] propose for sport videos a method for detecting captions with a shape analysis followed by noise removal. The position of the captions is detected by a knowledge-based system for the sport domain.
The effectiveness of an automatic extraction process is determined to a great extent by the amount of a priori information available in the application domain. For some specific applications, it is possible to find a set of analysis tools that perform segmentation and feature extraction automatically as described in Okada and von der Malsburg [45] and Ide et al. [46] For instance, Correia and Pereira [47] discussed an analysis system for surveillance application in which the precise contours may be detected automatically by combining the partial results from tools based on the homogeneity of both motion and texture. However, there are many cases where fully automatic segmentation and feature extraction tools do not provide acceptable results. For example, a video classification in indoor or outdoor clips is, in general, not as good for pure automatic processing. Thus, guidance from the user must be incorporated into the indexing process to achieve valuable results.
Extracting high-level semantic content is influenced by at least two issues: [48] first, semantic content of multimedia data could mean different things to different users, and second, users typically have diverse information needs. Thus, it is evident that a single feature may not be sufficient to completely index a given multimedia data. To relate low-level features (or groups of them) to high-level content types, more research on additional domain-specific knowledge has to be done. In this sense, the process of semantic indexing must be in most cases a semiautomatic one; that is, a combined use of automatic analysis tools and of user interaction and domain knowledge. [49] For instance, in the domain of Web mining, WebSEEK [50] introduces a semiautomatic system for retrieving, analyzing, categorizing, and indexing visual images from the World Wide Web.
In this context, Jorgensen et al. [51] proposed a very compact model—the indexing pyramid for classifying levels of indexing. The pyramid, as shown in Exhibit 4.4, distinguishes between syntactic (first four levels) and semantic levels (next six levels). The syntactic levels hold attributes that describe the way in which the content is organized, but not their meanings. In images, for example, type could be "color image." Global distribution holds attributes that are global to the image (e.g., color histogram), whereas local structure deals with local components (e.g., lines and circles), and global composition relates to the way in which those local components are arranged in the image (e.g., symmetry). The semantic levels, however, deal with the meaning of the elements. Objects can be described at three levels: generic, representing everyday objects (e.g., person); specific, representing individually named objects (e.g., Roger Moore); and abstract, representing emotions (e.g., power). In a similar way, a scene can be described at these three levels.
Exhibit 4.4: Indexing pyramid. [52]
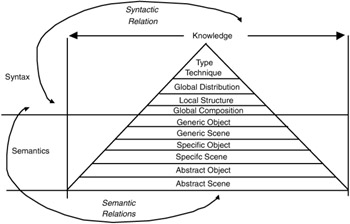
Elements within each level are related according to two types of relations: syntactic and semantic. For example: two circles (local structure) can be related spatially (e.g., next to), temporally (e.g., before), or visually (e.g., darker than). Elements at the semantic levels (e.g., objects) can have syntactic and semantic relations (e.g., two people are next to each other, and they are friends). In addition, each relation can be described at different levels (generic, specific, and abstract).
The authors of the indexing pyramid also propose a retrieval system [53] that allows a search specific to the levels of the pyramid. For instance, if a user enters "soccer" for image search at the syntactical level, one retrieves images with a description containing the keyword soccer (which does not yet mean we have really a soccer game shown in the image). If a user enters soccer at the semantic level, only those images are retained in which the event, "soccer," took place. An online demo is available at http://www.ctr.columbia.edu/~ana/MPEG7/PyramidCE/search.html/.
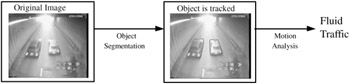
Recently, several projects have aimed at coping better with multimedia indexing. Many of these projects rely on MPEG-7 as a description standard. A first project was MODEST, or multimedia object descriptors extraction from surveillance tapes, which belonged to the ACTS[54] program in the domain of Interactive Digital Multimedia Services. MODEST[55] was supported by a consortium of different universities and Philips Company. They defined and developed a framework for the analysis of video sequences from surveillance tapes to extract high-level semantic scene interpretation. Exhibit 4.5 shows an application case of a road-monitoring scene. Detailed information about the composition of the scene is obtained from object segmentation and tracking mechanisms. For instance, in the scenario shown in Exhibit 4.5, fluid traffic is concluded from the composition information.
Exhibit 4.5: Indexing process in the ACTS project MODEST (multimedia object descriptors extraction from surveillance tapes) for road monitoring.
A second interesting project is the IST[56] project ASSAVID,[57] supported by Sony and several European universities. This project aims to develop techniques for automatic segmentation and semantic annotation of sports videos. It is a straightforward continuation of the projects concentrating on simple surveillance scenarios, like MODEST, to complex "live" scenarios. In this project, algorithms to segment sport videos into shots, and to group and classify the shots into semantic categories, for example, type of sport, are being developed. [58] To do this, the system extracts information from each shot, based on speech and text recognition, and uses MPEG-7 descriptors where relevant; that is, where more complex (than keyword) indexing is required.
To continue on projects supported by the EU (European Union) Framework, one has to announce the initiatives in the 6th EU Framework in the field of multimedia systems, issued in 2003. Among others, the EU calls for projects in the thematic: full multimedia everywhere. Points of interest are networked audiovisual systems and home platforms with a strong emphasis on technologies for interoperability. This is obviously related to MPEG-21 (see Chapters 3 and 5). More information on the call for proposals in the 6th EU Framework may be found at http://www.cordis.lu/ist/.
Other industry-supported research consortia focus on meaningful multimedia indexing. For instance, the Digital Video Multimedia Group at Columbia University[59] developed several techniques for identifying semantic content in sport videos. The applied strategy is to find a systematic methodology combining effective generic computational approaches with domain knowledge available in sport domains. Structures in sports video are characterized by repetitive transition patterns and unique views. For example, baseball videos normally consist of recurrent structures at different levels, such as innings, players, or pitches. A finite number of unique views are used because of the actual setup of cameras in the field. Therefore, the events at different levels can be characterized by their canonical visual views or the unique transition patterns between views. In this project, [60] a multistage detection system including adaptive model matching at the global level and detailed verification at the object level is introduced. The system demonstrates a high accuracy (>90 percent) for video segmentation with a real-time processing speed.
In addition, a personalized sports video streaming system based on the above results has been developed. [61] The system detects and filters the important events in live broadcast video programs and adapts the incoming streams to variable rate according to the content importance and user preference. Such application scenarios are powerful for streaming and filtering broadcast video to match the interest of users using pervasive computing devices. The techniques are also helpful for building personalized summarization or navigation systems, in which users can navigate efficiently through the video program at multiple levels of abstraction.
Singingfish.com uses MPEG-7 description schemes to describe the metadata characteristics of Internet streaming media. In particular, Rehm [62] demonstrated on Synchronized Multimedia Integration Language—Active Streaming Extensible Markup Language Format, or MPEG Audio Layer-3 URL (M3U)—specified presentations that the MPEG-7 Segment DS and Segment Decomposition DS allow one to model any currently available hierarchical playlist format. In addition to this observation, the author [63] also discusses MPEG-7 Multimedia Description Scheme (MDS) deficiencies. He mainly suggested an extension to the MediaInformation DSs to cope with scalable multimedia material. Detailed information on the MDS descriptors may be found in Chapter 2. These three projects are only a small portion of what is actually going on in the domain of semantic multimedia indexing and in MPEG-7 applications in general.
4.1.1 Use Case Study: Semantic Indexing of Images Supported by Object Recognition
Object recognition is a well-recognized technique for recognizing and classifying objects and thus attributing a semantic to them. The best-known work is probably that of Forsyth and Fleck. [64] Forsyth attracted much attention for his work on detecting naked human beings within images. His approach has been extended to a wider range of objects, including animals. Let us concentrate on their method for identifying a horse in an image (see also http://www.cs.berkeley.edu/~daf/horsedetails.html).
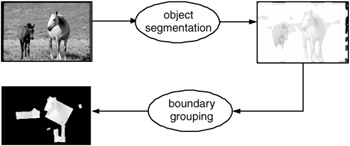
Exhibit 4.6 describes the indexing process. Images are first checked for pixels that have the right color and little texture. Second, a boundary detection is applied that splits the regions of interest into curves. Groups of boundaries that could be views of cylindrical segments are then assembled (boundaries should be roughly parallel). These groups are then checked to see whether they are acceptably large and contain sufficient pixels, leading to a set of segments. They are then tested to see whether they could come from a view of a horse. The criteria are learned from images of horses and consist of a sequence of classification steps whose structure follows from the topology of the horse assembly. This process leads to a set of segments that could have come from a horse. The recognition technique works not as well if significant overlapping of fore- and background objects occurs in the image. Thus, the precision of the horse detection on real test data showing not exclusively horses did not exceed 66 percent. [65]
Exhibit 4.6: Identifying horses in image collection: sample detection.
A promising technique to support the recognition process is to allow the system to learn associations between semantic concepts and the recognized objects through user feedback. These systems invite the user to annotate further regions of interest previously detected by object-recognition methods and then proceed to apply similar semantic labels to areas with similar characteristics. The pioneering system was FourEyes, [66] a learning system to assist users with the processes of segmentation, retrieval, and annotation. FourEyes extrapolates the semantic label of a selected region to other regions on the image and in the database by a selected model; for instance, by a Gaussian model of the label in that feature space. Moreover, FourEyes has a "society of models," from among which it selects and combines models to produce a labeling. This selection process is guided by the examples given by the user. More information on FourEyes may be obtained at http://web.media.mit.edu/~tpminka/photo-book/foureyes/.
More recently, Wang et al. [67] proposed A-LIP, an automatic linguistic indexing system for images. This system learns automatically from already categorized images based on statistical modeling. To measure the association between an image and the textual description of a category of images, the likelihood of the occurrence of the image based on the stochastic process (a two-dimensional multiresolution hidden Markov model [2-D MHMM] is used) derived from the category is computed. An online demonstration of the system may be found at http://wang.ist.psu.edu/IMAGE/alip.html.
[2]Lu, G., Multimedia Database Management Systems, Artech House, 1999.
[3]Subrahmanian, V.S., Principles of Multimedia Database Systems, Morgan Kaufman Press, 1998.
[4]Ono, A., Amano, M., and Hakaridani, M., A flexible content-based image retrieval system with combined scene description keywords, in Proceedings of the IEEE Conference on Multimedia Computing and Systems, Hiroshima, Japan, June 1996, pp. 201–208.
[5]Sebe, N. and Lew, M.S., Color-based retrieval, Pattern Recog. Lett., 22, 223–230, 2001.
[6]Deng, Y., Manjunath, B.S., Kenney, C., Moore, M.S., and Shin, H., An efficient color representation for image retrieval, IEEE Trans. Image Process., 10, 140–147, 2001.
[7]Adjeroh, D.A. and Lee, M.C., On ratio-based color indexing, IEEE Trans. Image Process., 10, 36–48, 2001.
[8]Berens, J., Finlayson, G.D., and Qiu, G., Image indexing using compressed colour histograms, IEEE Vision Image Signal Process., 147, 349–355, 2000.
[9]Chahir, Y. and Chen, L., Searching images on the basis of color homogeneous objects and their spatial relationship, J. Visual Comm. Image Representation, 11, 302–326, 2000.
[10]Syeda-Mahmood, T. and Petkovic, D., On describing color and shape information in images, Signal Process. Image Comm., 16, 15–31, 2000.
[11]Berretti, S., del Bimbo, A., and Pala, P., Indexed retrieval by shape appearance, IEEE Vision Image Signal Process., 147, 356–362, 2000.
[12]Huet, B. and Hancock, E.R., Shape recognition from large image libraries by inexact graph matching, Pattern Recogn. Lett., 20, 1259–1269, 1999.
[13]Wu, P., Manjunath, B.S., Newsam, S.D., and Shin, H.D., A texture descriptor for browsing and similarity retrieval, Signal Process. Image Comm. , 16, 33–43, 2000.
[14]Tao, B. and Dickinson, B.W., Texture recognition and image retrieval using gradient indexing, J. Visual Comm. Image Representation, 11, 327–342, 2000.
[15]Zhong, D., Kumar, R., and Chang, S.-F., Personalized video: real-time personalized sports video filtering and summarization, in Proc. of ACM Multimedia 2001, AMC Press, Ottowa, 2001, pp. 623–625.
[16]Snoek, C.G.M. and Worring, M., Multimodal Video Indexing: A Review of the State-of-the-Art. Multimedia Tools and Applications, to appear; also available as ISIS TR, Vol. 2001-20, December 2001.
[17]Zhang, T. and Kuo, C.C. Jay, Content-Based Audio Classification and Retrieval for Audiovisual Data Parsing, Kluwer, Dordrecht.
[18]Hampapur, A., Semantic video indexing: approach and issues, ACM Sigmod Rec., 28, 32–39, 1999.
[19]Lee, M.S., Yang, Y.M., and Lee, S.W., Automatic video parsing using shot boundary detection and camera operation analysis, Pattern Recog., 34, 711–719, 2001.
[20]Dimitrova, N., McGee, T., and Elenbaas, H., Video keyframe extraction and filtering: a keyframe is not a keyframe to everyone, in Proceedings of the 6th International Conference on Information and Knowledge Management (CIKM-97), Las Vegas, NV, November 1997, ACM Press, pp. 113–120.
[21]Dufaux, F., Key frame selection to represent a video, in Proceedings of the IEEE International Conference on Image Processing, Vancouver, Canada, September 2000.
[22]Lee, M.S., Yang, Y.M., and Lee, S.W., Automatic video parsing using shot boundary detection and camera operation analysis, Pattern Recog., 34, 711–719, 2001.
[23]Zhang, H.J., Kankanhalli, A., and Smoliar, S.W., Automatic partitioning of full-motion video, ACM Multimedia Syst., 1, 10–28, 1993.
[24]Boreczsky, J.S. and Rowe, L.A., A comparison of video shot boundary detection techniques, J. Electron. Imaging, 5, 122–128, 1996.
[25]Ahanger, G. and Little, T.D.C., A survey of technologies for parsing and indexing digital video, J. Visual Comm. Image Representation, 7, 28–43, 1996.
[26]Patel, N.V. and Sethi, I., Video segmentation for video data management, in The Handbook of Multimedia Information Management, Grosky, W.I., Jain, R., and Mehrotra, R., Eds., Prentice-Hall, Englewood Cliffs, NJ, 1997.
[27]Yu, H.H. and Wolf, W., A hierarchical multiresolution video shot transition detection scheme, Comp. Vision Image Understanding, 75, 196–213, 1999.
[28]Kosch, H., Tusch, R., Böszörményi, L., Bachlechner, A., Dörflinger, B., Hofbauer, C., Riedler, C., Lang, M., and Hanin, C., SMOOTH—a distributed multimedia database system, in Proceedings of the International VLDB Conference, Rome, Italy, September 2001, pp. 713–714.
[29]Schonfeld, D. and Lelescu, D., Vortex: video retrieval and tracking from compressed multimedia databases—multiple object tracking from MPEG-2 bit stream, J. Visual Comm. Image Representation, 11, 154–182, 2000.
[30]Milanese, R., Deguillaume, F., and Jacot-Descombes, A., Efficient segmentation and camera motion indexing of compressed video, Real-Time Imaging, 5, 231–241, 1999.
[31]Rui, Y., Huang, T.S., and Mehrotra, S., Exploring video structure beyond the shots, in Proceedings of the IEEE International Conference on Multimedia Computing and Systems, Austin, Texas, June 1998, pp. 237–240.
[32]Toklu, C., Liou, S.P., and Das, M., Video abstract: a hybrid approach to generate semantically meaningful video summaries, in Proceedings of the IEEE International Conference on Multimedia and Exposition, New York, July 2000, pp. 57–61.
[33]Manske, K., Mühlhäuser, M., Vogel, S., and Goldberg, M., OBVI: hierarchical 3D video-browsing, in Proceedings of the 6th ACM International Conference on Multimedia (Multimedia-98), New York, September 1998, ACM Press, pp. 369–374.
[34]Sawhney, H., Ayer, A., and Gorkani, M., Model based 2D and 3D dominant motion estimation for mosaicing and video representation, in Proceedings of the International Conference on Computer Vision, Cambridge, MA, 1995, IEEE CS Press, pp. 583–590.
[35]Tzanetakis, G. and Cook, P., Multifeature audio segmentation for browsing and annotation, IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, New York, October 1999.
[36]Rossignol, S., Rodet, X., Soumagne, J., Collette, J.-L., and Depalle, P., Feature extraction and temporal segmentation of acoustic signals, in Proceedings of the International ICMC: International Computer Music Conference, Ann Arbor, MI, October 1998.
[37]Schonfeld, D. and Lelescu, D., Vortex: video retrieval and tracking from compressed multimedia databases—multiple object tracking from MPEG-2 bit stream, J. Visual Comm. Image Representation, 11, 154–182, 2000.
[38]Eren, P.E. and Tekal, A.M., Keyframe-based bi-directional 2-d mesh representation for video object tracking and manipulation, in Proceedings of the IEEE International Conference on Image Processing, Kobe, Japan, 1999, IEEE CS Press, pp. 968–972.
[39]Eng, H.L. and Ma, K.K., Spatio-temporal segmentation of moving video objects over mpeg compressed domain, in Proceedings of the IEEE International Conference on Multimedia and Exposition, New York, July 2000, pp. 1531–1534.
[40]Jang, D.S., Kim, G.Y., and Choi, H.I., Model-based tracking of moving object, Pattern Recog., 30, 999–1008, 1997.
[41]Carson, C. et al., Blobworld: image segmentation using expectation-maximization and its application to image querying, IEEE Trans. Pattern Anal. Machine Intell., 24, 1026–1038, 2002.
[42]Carson, C. et al., Blobworld: image segmentation using expectation-maximization and its application to image querying, IEEE Trans. Pattern Anal. Machine Intell., 24, 1026–1038, 2002.
[43]Chang, Y.L., Kamel, W., and Alfonso, R., Integrated image and speech analysis for content-based video indexing, in Proceedings of the 3rd IEEE International Conference on Multimedia Computing and Systems, Hiroshima, Japan, 1996, pp. 306–313.
[44]Assfalg, J., Bertini, M., Colombo, C., and Del Bimbo, A., Semantic characterization of visual content for sports videos annotation, in Proc. of Multimedia Databases and Image Communication, Amalfi, September 2001, Springer-Verlag, Heidelberg, LNCS 2184, pp. 179–191.
[45]Okada, K. and von der Malsburg, C., Automatic video indexing with incremental gallery creation: integration of recognition and knowledge acquisition, in Proceedings of the Third International Conference on Knowledge-Based Intelligent Information Engineering Systems, Adelaide, August 31, 1999, pp. 431–434.
[46]Ide, I., Yamamoto, K., and Tanaka, H., Automatic video indexing based on shot classification, in Proceedings of the International Conference on Advanced Multimedia Content Processing, Osaka, 1999, Springer-Verlag, Heidelberg, LNCS 1554, pp. 87–102.
[47]Correia, P. and Pereira, F., The role of analysis in content based video coding and indexing, Signal Process., 66, 125–142, 1998.
[48]Chen, S.-C., Kashyap, R.L., and Ghafoor, A., Semantic Models for Multimedia Database Searching and Browsing, Kluwer, Dordrecht, 2000.
[49]Correia, P. and Pereira, F., The role of analysis in content based video coding and indexing, Signal Process., 66, 125–142, 1998.
[50]Smith, J. and Chang, S.F., Visually searching the web for content, IEEE MultiMedia, 4, 12–20, 1997.
[51]Jorgensen, C., Jaimes, A., Benitez, A.B., and Chang, S.-F., A conceptual framework and research for classifying visual descriptors, J. Am. Soc. Info. Sci., 52(11), 938–947, 2001.
[52]Benitez, B., Chang, S.-F., and Smith, J.R., IMKA: a multimedia organization system combining perceptual and semantic knowledge, Proceeding of the 9th ACM International Conference on Multimedia (ACM MM-2001), Ottawa, September 30–October 5, 2001, pp. 630–631.
[53]Benitez, B., Chang, S.-F., and Smith, J.R., IMKA: a multimedia organization system combining perceptual and semantic knowledge, Proceeding of the 9th ACM International Conference on Multimedia (ACM MM-2001), Ottawa, September 30–October 5, 2001, pp. 630–631.
[54]ACTS is an acronym for Advanced Communications Technology and Services Project supported by the EU 4th Framework.
[55]http://www.cordis.lu/infowin/acts/ienm/bulletin/01-1998/domain1/modest.html.
[56]Information Society Technologies Program of the EU 5th Framework.
[57]ASSAVID is an acronym for Automatic Segmentation and Semantic Annotation of Sports Videos. More information on ASSAVID may be found at http://www.viplab.dsi.unifi.it/ASSAVID/.
[58]Assfalg, J., Bertini, M., Colombo, C., and Del Bimbo, A., Semantic characterization of visual content for sports videos annotation, in Proc. of Multimedia Databases and Image Communication, Amalfi, September 2001, Springer-Verlag, Heidelberg, LNCS 2184, pp. 179–191.
[59]http://www.ctr.columbia.edu/dvmm/.
[60]Zhong, D. and Chang, S.-F., Structure analysis of sports video using domain models, IEEE Conference on Multimedia and Exhibition, Tokyo, August 22–25, 2001.
[61]Zhong, D., Kumar, R., and Chang, S.-F., Personalized video: real-time personalized sports video filtering and summarization, in Proc. of ACM Multimedia 2001, AMC Press, Ottowa, 2001, pp. 623–625.
[62]Rehm, E., Representing Internet streaming media with MPEG-7, in Proceedings of the ACM Multimedia 2000 Workshop Standards, Interoperability and Practice: Who Needs Standards Anyway?, New York, November 4, 2000, ACMPress, pp. 93–106.
[63]Rehm, E., Representing Internet streaming media with MPEG-7, in Proceedings of the ACM Multimedia 2000 Workshop Standards, Interoperability and Practice: Who Needs Standards Anyway?, New York, November 4, 2000, ACMPress, pp. 93–106.
[64]Forsyth, D. and Fleck, M., Automatic detection of human nudes, Int. J. Comput. Vision, 32, 63–77, 1999.
[65]Forsyth, D. and Fleck, M., Automatic detection of human nudes, Int. J. Comput. Vision, 32, 63–77, 1999.
[66]Minka, T.P. and Picard, R.W., Interactive learning using a "Society of Models," Pattern Recognition, 30, 1997.
[67]Wang et al., Automatic linguistic indexing of pictures by a statistical modeling approach, IEEE Trans. Pattern Anal. Machine Intelligence, 25(10), 14–20, 2003.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 77