Section 10.2. Characters in MIME
10.2. Characters in MIMEMIME is a protocol that makes it possible to send text data by email using different encodings, not just ASCII, which is the original encoding for Internet email. MIME has other purposes and applications as well, such as sending nontextual data by email. An email message that uses MIME has special headers as illustrated in the preceding section. The headers are used to specify the general data format of the message as well as its character encoding. It may also specify the transfer encoding (see Chapter 6) used for the data. 10.2.1. Media TypesInternet media types, often called MIME types, can be used to specify a major media type ("top level media type," such as text), a subtype (such as html), and an encoding (such as iso-8859-1). They were originally developed to allow the use of email for sending formats other than plain ASCII data. They can be (and should be) also used for specifying the encoding when character data is sent over a networke.g., by email or using the HTTP protocol on the World Wide Web. Originally, "MIME" was short for Multipurpose Internet Mail Extensions. The idea was to extend the capabilities of Internet email from the original content format, which is plain text with ASCII as the implied encoding. Thus, MIME was developed both to let you include characters other than ASCII into the message body and to specify methods for including nontext data, such as images, as attachments. The currently defined major media types are the following:
The media type concept is defined in RFC 2046. The procedure for registering types in specified in RFC 2048. The site http://www.oac.uci.edu/indiv/ehood/MIME/toc.html contains a collection of interrelated RFCs (20452049) in hypertext format. The official registry of media types is maintained by the Internet Assigned Numbers Authority (IANA) at http://www.iana.org/assignments/mediatypes/. Unregistered types are often used, though, especially for data related to new technologies. In principle, an unregistered media type should have a subtype that begins with x- (letter "x" and hyphen-minus)e.g., text/x-cooltext, but this requirement is often violated. 10.2.2. Character Encoding ("charset") InformationThe technical term used to denote a character encoding in the Internet media type context is charset, abbreviated from "character set." This has caused a lot of confusion, since "set" can easily be understood as repertoire. Normally, subtypes of message and text need a parameter that specifies the character encoding used, though this parameter can be omitted (defaulted) in some cases. The parameter is called charset, and it is written like the following example of an email message header: Content-Type: text/plain; charset=iso-8859-1 This specifies, in addition to saying that the media type is text and subtype is plain, that the character encoding is ISO-8859-1. Encoding names are case insensitive, and they must not contain spaces. The spaces after : and ; above are optional and used for clarity only. The official registry of charset (i.e., character encoding) names is kept by IANA at http://www.iana.org/assignments/character-sets. This plain text file also contains some references to documents that define encodings. There is also an unofficial tabular presentation of the registry, ordered alphabetically by charset name and augmented with some references: http://www.cs.tut.fi/~jkorpela/chars/sorted.html. Several character encodings have alternate (alias) names in the registry. For example, the ASCII encoding can be called ASCII, ANSI_X3.4-1968, or cp367 (plus a few other names). Its preferred name in MIME context is, according to the registry, US-ASCII. Similarly, ISO 8859-1 has several names; its preferred MIME name is ISO-8859-1. 10.2.3. MIME HeadersThe Content-Type information in the preceding section is an example of information in a message header, or header for short. Headers relate to some data, describing its presentation and other things, but are passed as logically separate from it. MIME headers are a special case of Internet message headers, often called RFC 822 headers, although the classical RFC 822 has now been replaced by RFC 2822, "Internet Message Format," available as hypertext at http://www.rfc-ref.org/RFC-TEXTS/2822/. In the specifications, "header line" is used instead of "header," but a header may be divided into several physical lines. Adequate headers should normally be generated automatically by the software that sends the data (such as a program for sending email, or a web server) and interpreted automatically by receiving software (such as a program for reading email, or a web browser). In email messages, headers precede the message body. It depends on the email program whether and how it displays the headers. Typically, just a few commonly used headers are displayed by default. The header names themselves, such as Content-Type and Date, are fixed by the email protocol, but the information content of headers might be shown to the user in a localized and customized way. For example, the content type is usually not shown to the user, since it is technical information for interpreting the data, whereas the timestamp in the Date header might be shown with any suitable name in a language understood by the user. 10.2.3.1. Internet message format and MIMEThe Internet message format was originally developed for simple ASCII-based email. It has been extended in content and scope so that, for example, Usenet messages and HTTP messages use the same fundamental format, though partly with different types of headers. The general approach of MIME and several essential headers are described in the basic MIME specification, RFC 2045, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies." There are additional definitions in RFC 3864, "Registration Procedures for Message Header Fields," and RFC 4021, "Registration of Mail and MIME Header Fields." Internet message headers have a common general syntax (see the example in Figure 10-3):
Within this simple framework, Internet message headers of different kinds can be used for a multitude of purposes, public and private. In theory, you are supposed to use a header name that starts with X- (capital "X" and hyphen-minus), if you use a header that is not defined in a published specification. In practice, people have used "private" or experimental headers without sticking to such conventions. Attempts have been made to describe the actual usage, but it has been very varying. For example, many email programs have used headers of their own in a proprietary manner, so that the same information is often expressed in different headers by different programs. RFC 3864 establishes a registry, which might clarify the situation: http://www.iana.org/assignments/message-headers/message-header-index.html. It does not directly define the headers but cites the defining documents, many of which just cite other documents for the real definitions. 10.2.3.2. Headers related to charactersThe most important headers that we need for character-related issues have already been mentioned. They are summarized in Table 10-1 along with some other headers. Not all of them relate directly to representation characters. In particular, the Subject header is mentioned here because it should contain the subject of the message in a suitable natural language, and this raises the question how we can represent non-ASCII data there.
10.2.3.3. Headers for transfer encodingAs you can see from Table 10-1, there are several headers that may specify a "content encoding," which means an additional encoding such as compression. Those headers differ in their scope of use. For example, Content-Encoding: gzip might be used by web servers when they send a document as compressed with the gzip algorithm, for efficiency. Web server software might allow the server administration to configure the server to automatically use such compression when sending to browsers that can handle it. This could remove much of the inefficiency involved in some character encodings. In MIME email, the Content-Transfer-Encoding header is used to specify the encoding (if any) applied to octets (as used in some primary encoding, such as UTF-8 or ISO-8859-1) in order to transmit them in an environment where "raw" 8-bit data might cause problems. The possible values for it are specified in Table 10-2.
The header Content-Transfer-Encoding: 7bit promises that the message content consists of relatively short (maximum: 998 characters) lines of text, with CR LF between lines. The characters CR and LF appear in such pairs only. All octets are in the range 1 to 7F hexadecimali.e., correspond to ASCII characters excluding NUL. The header Content-Transfer-Encoding: 8bit makes a similar promise, but octets larger than 7F may appear. NUL is excluded here, too. Thus, all octets in the range 1 to FF may appear, though CR and LF appear only in CR LF pairs. 10.2.3.4. The Quoted-Printable (QP) transfer encodingThe MIME specification defines, among many other things, the general purpose "Quoted-Printable" (QP) encoding, which we described in Chapter 6. Some of the basic points are repeated here, partly to explain them a bit differently, partly to help readers who skipped Chapter 6 because it was too technical. QP can be used to represent any sequence of octets as a sequence of such octets that correspond to ASCII characters. This implies that the sequence of octets becomes longer, and if it is read as an ASCII string, it can be incomprehensible to human readers. What is gained is robustness in data transfer, since the encoding uses only "safe" ASCII characters, which will most probably get unmodified through any component in the data transfer. Basically, QP encoding means that most octets up to 7F (hexadecimal) are used as such, whereas octets with higher values and some other octets are presented as follows: octet n is presented as a sequence of three octets, corresponding to (ASCII codes for) the equals sign, =, and the two digits of the hexadecimal notation of n. If QP encoding is applied to a sequence of octets presenting character data according to ISO 8859-1 character code, then effectively this means that most ASCII characters (including all ASCII letters) are preserved as such, whereas, for example, the ISO 8859-1 character ä (code position E4 in hexadecimal) is encoded as =E4. For obvious reasons, the equals sign = itself is among the few ASCII characters that are encoded. Being in code position 3D in hexadecimal, it is encoded as =3D. Encoding, for example, ISO 8859-1 data this way means that the character code is the one specified by the ISO 8859-1 standard, whereas the character encoding is different from the one specified (or at least suggested) in that standard. Since QP only specifies the mapping of a sequence of octets to another sequence of octets, it is a pure encoding and can be applied to any character data, or to any data for that matter. Naturally, QP needs to be processed (decoded) by a program that knows it and can convert it to human-readable form. It looks rather confusing when displayed as such. Roughly speaking, one can expect most email programs to be able to handle QP, but the same does not apply to newsreaders (or web browsers). Therefore, you should normally use QP in email only. 10.2.3.5. How MIME should workBasically, MIME should let people communicate smoothly without hindrances caused by character code and encoding differences. MIME should handle the necessary conversions automatically and invisibly. For example, when person A sends email to person B, the following should happen:
Thus, it is by no means necessary that the computers and email programs used by A and B use the same character code. Conversion (transcoding) to B's code, when needed, could be performed automatically in phase 4 or in phase 5. Moreover, A's program might in some situations be able to know what the recipient software wants. In particular, when responding to an email message, your email program might send (at least optionally) your reply in the same encoding in which the original message was received. This is however just extra courtesy; the encoding should still be specified in the headers. Moreover, if there are multiple recipients, you cannot expect all of them to be able to deal with the encoding that the original sender used. For example, if B is using a Macintosh computer, B's program would automatically convert the message into Mac's internal character encoding, Mac Roman, and only then display it. Thus, if the message was ISO-8859-1 encoded and contained the Ä (uppercase "A" with dieresis) character, encoded as octet C4 (hexadecimal), the email program used on the Mac should use a conversion table to map this to octet 80, which is the encoding for Ä on Mac. If the program fails to do such a conversion, strange things will happen. ASCII characters would be displayed correctly, since they have the same codes in both encodings, but instead of Ä, the character corresponding to octet 196 in Mac encoding would appear, namely, the symbol 10.2.4. Troubleshooting ExamplesUnfortunately, there are deficiencies and errors in software so that users often have to struggle with character code conversion problems, perhaps correcting the actions taken by programs. It takes two to tango, and some more participants to get characters right. This section demonstrates different things that may happen, and do happen, when just one component is faultyi.e., when MIME is not used or it is inadequately supported by some "partner" (software involved in entering, storing, transferring, and displaying character data). Typical problems that occur in communication in Western European languages other than English creates situations in which most characters get interpreted and displayed correctly, but some "national letters" don't. For example, the character repertoire needed in German, Swedish, and Finnish is essentially ASCII plus a few letters like ä from the rest of ISO Latin 1. If a text in such a language is processed so that a necessary conversion is not applied, or an incorrect conversion is applied, the result might be that, for example, the word "später" becomes "spter" or "spÌter" or "spdter" or "sp=E4ter." Much of the text will be quite readable, but words containing accented letters look odd. If the data is in an Internet message, such as an email message, that has appropriate MIME headers, it is straightforward to interpret the data. You may need to use a special program that can decode the encoding used, or you may even need to consult a definition or a mapping table for an encoding or code. Things get worse if there are no headers, or if the headers contain wrong informationi.e., the data does not make sense even technically when interpreted according to it. You might still be able to deduce or guess what has happened, and perhaps to determine which code conversion should be applied, and apply it more or less "by hand." In the following examples, we assume that you have received (or found) some text data that is expected to be, say, in German, Swedish, or Finnish and that indeed appears to be such text, but with some characters replaced by oddities in a somewhat systematic way. We will consider some situations where you can guess, with reasonable certainty, what has happened. Depending on the case, you may need information about encodings as presented in Chapters 3 and 6 as well as in documents cited there.
We will consider the particular letter ä ("a" with umlaut), which is common in all the languages mentioned. We could try to identify some words that should contain the letter ä but have something strange in place of it (as in the examples for "später"). Let us now assume that such identification has been madei.e., we know (or at least have guessed intelligently) what character or string appears where ä (U+00E4) should appear. In the following, some common cases are analyzed, largely under the assumption that your program interprets the data in ISO-8859-1 or in Windows Latin 1 encoding:
The encodings involved in the examples are largely old encodings that are not used much in modern computers. The reason is that problems with encodings arise mostly when old systems and old software are involved. 10.2.5. Character Encoding on the WebIn Chapter 1, we discussed the character encoding problems of web pages from a user's point of view. Sometimes you need to change your browser settings in order to view a web page correctly, telling the browser to try a different encoding. Here we discuss the authoring side of the matter. This explains the background of the problems that users experience, and this is also important to people who wish to publish something on the Web. The principles are simple:
The use of HTML forms and processing of data posted via forms raises some difficult additional problems, which will not be discussed here but in Chapter 11. 10.2.5.1. Headers in HTTPHTTP is the transport protocol of the Web, as well as in intranets and extranets. Contrary to what the name expansion "HyperText Transfer Protocol" suggests, HTTP is not limited to hypertext. It can also transport plain text files, pictures, audio files, executable binaries, etc. The HTTP technology is based on the client/server model: a client (browser) sends a request to a server, and the server responds to it, typically by sending the requested data and some headers that describe the data. The request normally specifies the requested resource by its URL. A web server is supposed to specify the media type of the data that it sends to a browser, using a Content-Type header as in email. Normally a browser sends a request without specifying the media type of the requested resource. A browser can actually specify its media type preferences using an Accept header, but that header usually plays no role. Instead, the server sends the requested resource, along with information about its media type. Usually a browser does not show this information, just uses it. (Later in this section, we describe tools for viewing the headers.) For example, when the requested resource is a photograph in JPEG format, the server might send: Content-Type: image/jpeg The general idea is that upon receiving such information, the browser immediately knows what to expect. It can select an appropriate action, possibly affected by user settings that specify how different data formats are to be handled. In particular, if the header specifies plain text as the media type, the browser can simply display it as-is. It could also pass the plain text to another program, such as a simple editor, but browsers normally just show the data in the browser window. The user may then save it locally, if desired. Sometimes the server response does not contain such a header, and the browser needs to make a guess, or report an error. Some browsers make their guesses even in the presence of a Content-Type header. This mainly applies to Internet Explorer, which uses a relatively complicated scheme to decide how to interpret a server response, possibly using the suffix of the URL (such as .gif) or an analysis of the (start of) the content of the resource. Microsoft's own documentation of the mechanism is available at the address http://msdn.microsoft.com/workshop/networking/moniker/overview/appendix_a.asp. Usually this does not cause harm, if the filename suffix matches common conventions and if the file content is of more or less normal kind. However, if you, for example, wish to make a document available on the Web as a plain text resource, you will run into problems if its content looks like HTML markup to IE. Moreover, authors who rely on IE's guessing might fail to check that correct HTTP headers are sent, and this may imply that the file is not correctly processed by other browsers. 10.2.5.2. Specifying the encoding in HTTP headersIn HTTP, the Content-Type header can be used for specifying both the media type and (optionally) the character encoding. For an HTML document in particular, a typical header is: Content-Type: text/html; charset=iso-8859-1 Thus, the encoding is specified in a charset parameter of the media type. The parameter can also be specified for plain text (text/plain) as well as for other subtypes of text. This sounds very simple, and it is, but there are several complications. For various reasons, servers often do not include a charset parameter. We will later in this section discuss what should happen then. What actually happens is that a browser uses some default encoding. If that is not the right encoding and the user realizes this, she may try to tell the browser to use another one, as explained in Chapter 1. Even when a browser normally honors HTTP headers, you might be able to tell the browser to override the charset parameter. One reason for this is that servers sometimes send wrong information about encoding, and users might be able to fix this. On Internet Explorer for example, if you simply select View The choice of encoding does not affect characters that have been represented using entity or character references, since they do not depend on the encoding. For example, if an ISO-8859-1 encoded document contains ï as such (octet EF), then the rendering often changes to another character when the encoding setting is changed. If the character has been written in HTML as ï or ï or ï, it remains as ï. 10.2.5.3. Which encodings can be used?In principle, any registered character encoding can be used for documents on the Web. Many encodings are used, and browsers generally support a few dozen different encodings. However, the safest encodings are ASCII, ISO-8859-1, and UTF-8. The windows-1252 encoding is rather safe in practice, too. Other encodings commonly supported by browsers include several 8-bit encodings in the ISO 8859 and Windows encoding families. However, especially the newest of such encodings might not be recognized by browsers or by important search engines or other software used for automated processing of web pages. ISO-8859-2 is probably supported, but ISO-8859-3 or ISO-8859-13 might be a different matter. Although many search engines can process such encodings, their methods of recognizing the encoding might be faulty. Although UTF-8 is fairly safe as far as browsers and search engines are concerned, with few exceptions, there are problems with authoring software . You can surely find an authoring tool that lets you create UTF-8 encoded documents, either directly in an authoring program or via some conversion to UTF-8 format. However, if your documents will be maintained or edited by other people, you cannot always assume that they have or they can get and learn to use a UTF-8 capable tool. There is also a psychological factor involved. If you have a tool that lets you type any Unicode character comfortably, you will be tempted to use the full Unicode repertoire. You would easily use characters that many, if not most, users will not see properly. Thus, if you expect to need just a few characters outside ASCII, you might consider a simple approach that uses ASCII as the encoding and expresses all other characters using entity or character references (see Chapter 2). That way, anyone could edit the documents in any environment, though the references might look somewhat obscure. For understandability, it would be best to use entity references (like é) for all characters that have one and hexadecimal character references (like ♀) rather than decimal character references (like ♀) for other characters. Hexadecimal numbers are somewhat more comfortable than decimal if you need to interpret character references, since Unicode-related information usually uses hexadecimal. (Some old browsers do not understand hexadecimal references or all entity references, but the impact of such considerations is rather small these days.) Although browsers usually support UTF-16 as well as UTF-8, some important search engines apparently do not process UTF-16 correctly. Thus, it is not practical to use UTF-16 on the Web. This may change if UTF-16 becomes more common on the Web, but there are little signs of such a development. See also the section "Choosing an Encoding" in Chapter 6. Opinions differ on the acceptability of windows-1252 (Windows Latin 1). It is widely supported, since due to its common use, even software on non-Windows platforms has to recognize and interpret it, in order to work well on the Internet. It is also an officially registered encoding. On the other hand, it is not an international standard but a proprietary encoding. In HTML authoring, you do not win much by using windows-1252 instead of ISO-8859-1. The extra characters like dashes and "smart" quotation marks (see Chapter 3 for details) can be relatively well written using entity references like –. However, if your data comes from a document produced using a word processor and containing such punctuation characters, it might be simplest to leave it windows-1252 encoded, if that was the format when you received the data. 10.2.5.4. HTTP versus HTMLAccording to the HTTP 1.1 specification (RFC 2626), any subtype of text (such as text/plain and text/html) has ISO-8859-1 as its default encoding. The HTML 4.01 specification, on the other hand, says that no default encoding shall be implied. This effectively means that when the encoding has not been specified, the browser should do its best to guess the encoding from the content, instead of simply assuming ISO-8859-1. For further confusion, RFC 3023 (XML Media Types), "XML Media Types," specifies the media type text/xml so that for it, the default encoding is US-ASCII. That is, if an XML document is sent with a MIME or HTTP header specifying that media type and without a charset parameter, the recipient must imply that the encoding is US-ASCII. In practice, the default encoding that a browser uses for a page (when the server or the page itself does not specify the encoding) depends on the browser. The default has often been selected to suit the cultural environment where the browser is used. In any case, if the user has selected the encoding manually, this setting will usually stay in effect as a default. The moral is, of course, that an author should try to make the web server send a header that specifies the encoding, even if it is ISO-8859-1. If the encoding is UTF-8, there is an even greater reason for specifying it in an HTTP header, of course. 10.2.5.5. Checking the HTTP headersIn order to check the HTTP headers sent by a server, you can use a Telnet program or some similar software. Unfortunately, the Telnet program included in Windows is very simple, but there is, for example, the free PuTTY program, which is distributed as a binary executable via http://www.putty.nl/. Using PuTTY (or Telnet), connect to the server using the applicable port, which is normally 80 for HTTP and can be obtained from the URL if not. (If the server name in the URL is followed by a colon and a number, the number is the port number to be used.) Then you issue a HEAD command and a HOST command and an empty line (i.e., hit Enter twice), and wait for an answer. In the HEAD command, the first argument is the relative URL, starting from the solidus character / that follows the server name in the absolute URL. The second argument specifies the HTTP protocol version. The HOST command is required (in HTTP/1.1) and repeats the server name. Figure 10-4 shows a dialog in which the user, after invoking PuTTY so that it is instructed to connect to www.cs.tut.fi at port 80, requests the HTTP headers for the URL http://www.cs.tut.fi/~jkorpela/chars/. Alternatively, you can check the headers using Lynx, the text-based browser available for several environments and often installed on Linux and Unix systems. You would use a command of the form lynx -head -dump address. As an author of web pages, you need not check the headers of all of your documents, of course. The headers are normally constructed by the web server by some general rules. Thus, it mostly suffices to check things when you start using a server, or when problems appear that might be related to the character encoding or other things expressed in headers. Figure 10-4. Requesting HTTP headers in a simple dialog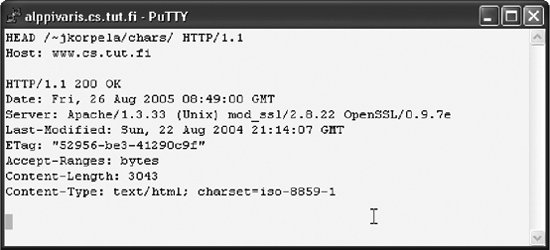 This, by the way, is one of the reasons why you should try to specify the URL of your page, rather than just send the contents of a document, when you ask for help with a page. Other people might find problems that you didn't noticein the headers. In some situations, you need to check the HTTP headers sent by a browser (to a server). In particular, so-called content negotiation may involve such headers for the purpose of agreeing (between a browser and a server) on an encoding to be used. There are services for echoing back the headerse.g., http://www.cs.tut.fi/cgibin/~jkorpela/headers.cgi and http://www.tipjar.com/cgi-bin/test. Such services differ in the way they display the headers. Often the header names are preceded by the string HTTP_, which is not part of the headers; it is added by software like CGI. The service at http://web-sniffer.net has a particularly detailed and configurable output, and it can show both the headers sent by the browser in the request and the response headers sent by the server. 10.2.5.6. Server configurationIt depends on the web server software and its configuration whether and how an author can affect the HTTP headers. In typical server software, Apache, the tools for that are simple, though a bit coarse. For example, to specify that files with names ending with .html in a directory (folder) be sent with a header that indicates UTF-8, you would create, in that directory, a plain text file with the name .htaccess(note the period at the start) and with the following line as its content: AddType text/html;charset=utf-8 html Thus, for example, if you have some HTML documents that are ISO-8859-1 encoded and some that are UTF-8 encoded, you have two simple options:
As another example, suppose that you need to put plain text files into one directory on a web server, and some of them are UTF-16 encoded and some are windows-1252 encoded. You could name them so that they have .u16 and .wtx suffixes, respectively. (These are just suffixes invented for this purpose; you can use any suffix that has no conventional meaning.) Then you would add the following lines into the .htaccess file: AddType text/plain;charset=utf-16 u16 AddType text/plain;charset=windows-1252 wtx The Apache documentation at http://httpd.apache.org/docs/ explains additional possibilities. For other server software, different approaches might be needed, though many servers imitate Apache principles. Links to documentation on other server software can be found via http://www.serverwatch.com/stypes/. In practice, many authors have no knowledge about this, and they might even be unwilling to learn about it. It sounds like programming to many, and words like "server configuration" or being asked to do something at the "HTTP level" can be intimidating. In any case, it's quite different from HTML or CSS or the use of a web page editor. Moreover, a server might have been configured by its maintenance to ignore the settings of individual authors. Server administration might regard per-directory .htaccess files as a security threat, and indeed, there are some risky things that authors could do with them to override system-wide settings. An Internet Service Provider might even disable .htaccess files on normal accounts in order to charge more for special accounts where they are enabled. If the server software or administration prevents authors from affecting HTTP headers (e.g., by disabling the use of .htaccess on Apache), the server should be configured to send HTML documents with a header that has no charset parameter. Authors should be told how to use meta tags to specify the encoding. Beware that such tags cannot override the charset parameter specified in HTTP headers. There are also other server technologies that can be used to specify the encoding in HTTP headers. For example, when using PHP, you can write a statement like the following into your document. The PHP processor, running on your server, will recognize it and send actual HTTP headers for the document as specified (and will remove this statement from the document that is sent to the browser): <?php header("Content-type: text/html; charset=UTF-8"); ?>10.2.5.7. Using a meta tagIt is possible that a server sends HTML files in a fixed manner with a Content-Type header that specifies just text/html with no charset indication. In that case, authors can use the workaround of HTML meta tags, which can be regarded as simulating HTTP headers. For example, the following tag, inside the head part of an HTML document, would ask browsers to behave as if the HTML document had been sent with the header Content-Type: text/html;charset=utf-8: <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> If the HTML used is some version of XHTML, you need to terminate the tag with / > instead of just >. Technically, such meta tags are ignored according to XHTML specifications, but they may be used as a method that works on older browsers that process XHTML documents by old HTML rules. Experts disagree on whether you should use such a meta tag even when the character encoding is specified in a real HTTP header. On one hand, it is a bad idea to hard-wire information about the encoding into the file itself. After all, the encoding could be changed later, without noticing that the tag should be changed too. In principle, the document might be transcoded (i.e., its encoding changed) on the fly as it passes through a network, though is not likely. On the other hand, the meta tag is a small insurance against eventual changes in the server. Moreover, if a user saves an HTML document locally on his disk and later accesses it locally, there will be no HTTP headers to tell the encoding. Browsers might (and indeed they should) store the information upon saving the file, in a manner that lets them check it upon any subsequent access. However, browsers do not always behave that way. This is perhaps the most important point here, so in practice, it's usually safest to use the meta tag, even if it is redundant. When using a meta tag to declare the encoding, it is safest to put it before any occurrence of a non-ASCII character. By HTML rules, you can always ensure this by writing the meta tag as the first tag inside a document. The tag should apply to the document as a whole, and browsers usually treat it so. However, some browser might start applying it only after encountering the tag in the sequential processing of a document. For example: <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> <title>Liberté, égalité, fraternité</title> You cannot use meta tags in plain text files, of course. Thus, if you wish to make, for example, a UTF-8 encoded plain text file available on the Web, you really need to find a way to make the server send it with Content-Type: text/plain;charset=utf-8. 10.2.5.8. Resolution of conflictsAccording to the HTML 4.01 specification, the character encoding of an HTML document can be specified in the following ways, in priority order:
Browsers have ignored the third alternative, but they implement the two other ways correctly, in general. This means that if the server sends a charset parameter in an HTTP header, there is no way to override this in the document itself. Thus, if you configure a web server and do not want to let authors affect the HTTP headers (e.g., with their .htaccess files), you should configure the server to send a Content-Type header without a charset parameter. It would then be appropriate to tell authors to use meta tags to specify the encoding, in all HTML files. 10.2.5.9. The effect of XHTMLXHTML, the XML-based formulation of HTML, introduces additional ways of specifying the encoding. For XML in general, the rules of the game (explained in more detail in the XML specification http://www.w3.org/TR/REC-xml/) are as follows:
If your XML document is in ASCII encoding, you need not specify the encoding. The reason is that an ASCII file will be correctly interpreted when it is treated as UTF-8. For ISO-8859-1, however, things are quite different, and the encoding must be specified, either in an XML declaration, or in an HTTP header. In the special case of XHTML, the same principles are applied. There's actually no room for using a meta tag to specify the encoding. Both an XML declaration and actual HTTP headers are supposed to override any meta tag, and if neither of them is used, then the file is recognized as UTF-8 or UTF-16. This is what seems to happen, too. Yet the XHTML 1.0 specification describes, in Appendix C:
The explanation is that although the meta tag is ignored by XHTML rules, it acts as a backup for browserse.g., Internet Explorer (IE) 6'that do not understand XHTML. Such browsers treat the data as HTML, ignoring the XML declaration. For further confusion, there is strong practical reason to avoid using an XML declaration in XHTML documents on the Web: the XML declaration makes IE 6 go into "quirks mode." This means that IE 6 intentionally simulates previous versions of the browser in the processing of some HTML and CSS constructs, in a manner that violates their specifications. See http://www.quirksmode.org/ for more explanations. The bottom line is that if you wish to serve an XHTML document on the Web, it is best to make it UTF-8 encoded (so that you can omit the XML declaration). If that is not possible, you should use actual HTTP headers to specify the encoding. 10.2.5.10. Heuristics of detecting encodingWhen none of the methods just described has been used to specify the character encoding, the browser has to make a guess or give up. Browsers generally try to apply heuristic reasoning rules to deduce the encoding. At http://www.i18nfaq.com/chardet.html, you can find a Java version of the heuristic code used in Mozilla. Remarkably often, browsers make a right guess. It is in principle impossible to determine the encoding of text from the text alone, but in practice, you can often guess right even using automated tools. Different encodings have special properties and known areas of application. More important, a browser knows what to expect. HTML documents can be expected to start (aside from a possible BOM) with a coded representation of characters from the ASCII repertoire, even if they then go on to present a document body containing a wide range of Unicode. Moreover, there are specific constructs (like a document type declaration and HTML tags) to be expected. There aren't too many different ways of representing the ASCII repertoire, in encodings actually used, so a heuristic has a good chance of recognizing what's going on. Yet, browsers may guess wrong. The principle that either the server or the document itself should always specify the encoding is not just academic. Browsers have been reported to infer, for a document sent with no indication of encoding, that the encoding is GB2312, a Chinese encoding, when it is in fact ISO-8859-1 encoded and contains almost exclusively ASCII characters. If there are just a few octets with the most significant bit set, the browser might thus think they are part of ideographs and display them all wrong. Heuristics that are oriented toward distinguishing between Asian encodings might thus fail miserably for, for example, English text with a few non-ASCII characters in names. 10.2.5.11. Which encoding should I use?Here we are primarily interested in HTML documents, though the principles can be applied to plain text documents as well, with some obvious modifications. In particular, you cannot use character or entity references in plain text. With regards to CSS files, for example, it is usually best to use ASCII only in them. In the rare cases where you need non-ASCII characters in CSS (mainly in generated content), use the CSS escape mechanisms (e.., \201C for U+201C) mentioned in Chapter 2. The choice of an encoding for documents on the Web is a matter of compromises between different conflicting needs and limitations. A suggested general policy is presented in Table 10-3. In all cases, the first column describes the characters that are likely to appear frequently in data. Remember that other characters can be expressed using character or entity references, no matter what encoding is used. "Correct punctuation" mainly refers to "smart" quotes, typographers' apostrophes, and dashes like "" and "'". Potentially suitable 8-bit encodings were discussed in Chapter 3.
There is a similar but more detailed "decision table" at "Checklist for HTML character encoding," http://ppewww.ph.gla.ac.uk/~flavell/charset/checklist.html, by Alan Flavell. The document suggests that if you use ASCII encoding and represent all non-ASCII characters using entity or character references, you declare the encoding as UTF-8. This is technically correct (an ASCII file is trivially UTF-8 encoded, too), and it helps some old browsers render the references correctly. 10.2.5.12. Avoiding the encoding problemThe method of using entity or character references is in principle unnecessary when UTF-8 is used, except for the few markup-significant characters (<, &, and quotation marks inside attribute values). However, it is still often a practical approach. Suppose that you have a document that is ASCII or ISO-8859-1 encoded, containing just English for example. If you would like to add a paragraph in Polish, what would you do? Switching to ISO-8859-2 would let you use all the accented Polish letters directly, but you might then have problems with some French letters, if you have used them. Using UTF-8 might require tools and arrangements that aren't available now. Using character references avoids problems and lets you keep using the encoding you are using now. If you need just a few of them, you could simply look them up from some handy reference. If you have a long paragraph, you would like to use something more automatic. Several conversion programs can do that. For example, using MS Word, you can proceed as follows: Figure 10-5. One version of the Unicode Encoded logo
For example, suppose that the text is just "This is a Polish name: Wa <p class=MsoNormal>This is a Polish name: <span lang=PL>Wałęsa.</span></p> This can be inserted into an HTML document, irrespectively of its character encoding. (You can remove the attribute class=MsoNormal, which is only used by Microsoft Office software internally, but on the other hand, you might as well leave it there.) 10.2.5.13. The "Unicode Encoded" logoSome web pages that are Unicode encoded display an image with the text "Unicode Encoded," as in Figure 10-5. The value of such a logo is, however, probably negative on most pages. Visitors are interested in your content, and perhaps your visual design, and the logo is mostly distracting on both accounts. The logo might be useful, though, on pages that specifically sell, demonstrate, or promote Unicode-related products, services, or principles, so that users can be expected to be (or to become) interested in Unicode itself. Should you wish to use a "Unicode Encoded" logo, note that there are several alternatives available. At http://www.unicode.org/consortium/uniencoded.html, you can find specific rules on using them. The basic principles are:
The markup for the logo as suggested on the Unicode site does not quite conform to good web authoring practices. The following uses more suitable alt and title attributes: <div><a href="http://www.unicode.org/" title="The Unicode Consortium (main page)"> <img src="/books/1/536/1/html/2/unicode-aqua-onwhite.png" width="100" height="16" alt="This page is Unicode encoded." border="0"></a></div> |
 . (This example intentionally refers to the old Mac Roman to make a point. New Mac software can usually interpret ISO-8859-1 and Unicode encodings more directly.)
. (This example intentionally refers to the old Mac Roman to make a point. New Mac software can usually interpret ISO-8859-1 and Unicode encodings more directly.)


 Encoding and then pick up some encoding, you will make the browser use that encoding only if the server has not announced the encoding. But if you first uncheck the first item in the encoding menu, "Automatic selection," you make the browser override any encoding that the server has specified. Try it; visit, say, some page in French and change the encoding to some Cyrillic encoding, and you see the accented letters turn to Cyrillic letters. Remember to check "Automatic selection back again after this test, since otherwise you will need to select it manually on every page.
Encoding and then pick up some encoding, you will make the browser use that encoding only if the server has not announced the encoding. But if you first uncheck the first item in the encoding menu, "Automatic selection," you make the browser override any encoding that the server has specified. Try it; visit, say, some page in French and change the encoding to some Cyrillic encoding, and you see the accented letters turn to Cyrillic letters. Remember to check "Automatic selection back again after this test, since otherwise you will need to select it manually on every page.
 sa." Working with it in MS Word, you would click on the name "Wa
sa." Working with it in MS Word, you would click on the name "Wa