Section 6.5. Byte Order
6.5. Byte OrderA unit that consists of two or four octets, such as the code units in UTF-16 and UTF-32, has a logical order of octets. For example, if you interpret a two-octet unit as a single unsigned integer (in the range 0..FFFF in hexadecimal, 0..65,535 in decimal), one of the octets is treated as more significant than the other. Strange as it may sound, the physical order of octets within a unit may differ from their logical order. This might be compared to storing a string like "42" so that "2" appears first in storage, then "4." Specifically, the physical order of octets in a two-octet unit might be less significant octet first. For a four-octet unit, you might in theory define several possible orders. In practice, unless the natural order from the most significant to the least significant is used, it's the exactly opposite order. The term byte order refers to the mutual order of octets (bytes) within a unit of two or four octets. Computers that use a reverse order (least significant to most significant) of octets within a storage unit are called little-endian. Those with the logical order are called big-endian. Within a single computer, endian-ness seldom causes trouble. In programming, if you access individual octets, you may need to know the endian-ness. However, for most practical purposes, the softwareincluding library routinesthat you use can be expected to handle the endian-ness, so that you can work with the logical order only. In data transfer, on the other hand, endian-ness becomes a problem. Suppose that you create a file in UTF-16 encoding, for example, on a big-endian computer and send the file to a little-endian computer. How does the recipient know that it needs to reverse the order of octets within a code unit? There are three possible approaches:
The second approach can be applied in the context of Unicode encodings by using the encoding names UTF-16LE and UTF-16BE. They denote UTF-16 in little-endian and big-endian byte order, respectively. In these encodings, no byte order mark is allowed. Using just UTF-16 means an unspecified byte order, but so that big-endian is implied, if the data itself does not indicate the byte order. Similarly, for UTF-32, you can use the specific names UTF-32LE and UTF-32BE. Although the second approach looks logical, it is not universal. One problem with this is that not everything is sent with Internet message headers. Even if you can declare the byte order outside the data, things might get separated and your data might need to be processed without any outside declaration. For example, data received as an email attachment or via HTTP may have headers that specify the byte order, but when it is saved locally, this information may get lost. Filesystems often lack tools for saving information about encoding and byte order. Indicating the byte order in the data itself, using a byte order mark, helps quite a lot.
The way to indicate the byte order in the data itself is to start the data with abyte order mark (BOM). This means a Unicode code point reserved for this specific purpose, namely U+FEFF. Note that you use the same code point, irrespective of byte order. When your data is represented in UTF-16 encoding in a specific byte order, the first two octets will be either FE FF or FF FE. From this, the recipient can infer big-endian or little-endian byte order, respectively. In practice, the byte order mark also works as a strong indication of the fact that the data is UTF-16 in the first place. This is useful in situations where the software has no direct information about the encoding. If a program opens a disk file, it might guess from the filename extension (such as .txt) that it is a text file, but how can it guess the encoding? If the first two octets are FE and FF, in either order, it is very unlikely that the data is any other encoding but UTF-16. It cannot be ASCII encoded, since the octets are not in the ASCII range. If it were ISO-8859-1 or windows-1252 encoded, the file would start with the character pair " Note that although the octet sequence FF FE may thus appear in UTF-16 encoded data, the code point U+FFFE is not allowed; it is defined to be a noncharacter. If you receive data claimed to be in big-endian UTF-16 and the first two octets are FF FE, you know that something is wrongprobably the claim about byte order is wrong. Similarly, when data is known or expected to be in UTF-32 encoding, but in unspecified byte order, it should start with the octets 00 00 FE FF or 00 00 FF FE, from which you can deduce the byte order (big-endian or little-ending, respectively). If it does not start in either way, it should be assumed to be big-endian without BOM. The Unicode standard does not require the use of BOM. Other standards or specifications may require or recommend its use. In general, there's no reason not to use BOM in UTF-16 and UTF-32. It is a cheap way to help in correct interpretation of data. In UTF-8, there is no byte order issue, since the code unit size is one octet. Therefore, using BOM serves no purpose. It is nevertheless allowed, though discouraged. The most common situation for its presence is that data has been converted from UTF-16 or UTF-32 without removing BOM. (In UTF-8, BOM is the octet sequence EF BB BF.) The BOM is to be treated as indicating the byte order only, not as part of the data. Previously, code point U+FEFF was defined to have the meaning of a zero width no-break space (ZWNBSP), too, and it could appear in the middle of text, too. This usually did not cause problems, but such usage has now been deprecated. In theory, when you detect U+FEFF at the start of UTF-8 data, you cannot know for sure whether it is meant to be a byte order mark or just a no-break space as part of the data proper. In practice, this seldom makes a difference, since an initial no-break space doesn't really matter. However, if you concatenate files, for example, it might matter. If U+FEFF is encountered within text, it should be treated as ZWNBSP, which acts as invisible "glue" that prevents a line break between characters. However, you should not use it that way in new data; the recommended "glue" character is word joiner U+2060. Unicode implementations are allowed to convert U+FEFF (inside data) to U+2060. There is no way in Unicode to change the byte order within a file. If U+FEFF appears anywhere else except at the start of character data, it must be interpreted according to the no-break space semantics (or not be interpreted at all). Due to the stability principles of Unicode, code point U+FEFF preserves "zero width no-break space" as its Unicode name. |

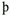 ÿ" or "ÿ
ÿ" or "ÿ ." These characters are rather rare, and their combination is impossible in any natural text. (The thorn,
." These characters are rather rare, and their combination is impossible in any natural text. (The thorn,