Section 4.1. Design Principles
4.1. Design PrinciplesHere we will start from the proclaimed design principles of Unicode. Later there will be some critical notes and considerations. We will first consider the very general, slogan-like expressions of the goals, and then the more technical principles. 4.1.1. Goals: Universality, Efficiency, UnambiguityThe Unicode standard itself says that it was designed to be universal, efficient, and unambiguous. These slogans have real meaning here, but it is important to analyze what they mean and what they do not mean. Let us first see how they are presented in the Unicode standard, and then analyze each item:
Universality means much more than just creating a superset of sets of characters. Practically all other character codes are limited to the needs of one language or a collection of languages that are similar in their use of characters, such as Western European languages. Unicode needs to encompass a variety of essentially different collections of characters and writing systems. For example, it cannot postulate that all text is written left to right, or that all letters have uppercase and lowercase forms, or that text can be divided into words separated by spaces or other whitespace. Moreover, Unicode has been designed to be universal among character codes. That is, it assigns code points to the characters included in other codes, even if the characters could be treated as variants or combinations of other characters. The reason is that Unicode was also designed for use as an intermediate code. You can take character data in any character code and convert it to Unicode without losing information. If you convert it back, you get the exact original data. You can also convert it to a third character code, provided that it is capable of representing all the characters. If the source and destination codes treat, say, £ (pound sign) and ₤ (lira sign) as different, they will appear as different after the conversion that used Unicode as an intermediate code. Thus, universality implies complexity rather than simplicity. Unicode needs to define properties of characters in a manner that makes explicit many things that we might take for grantedbecause they are not evident at all across writing systems. Efficiency refers here to efficient processing of data. When all characters have unique identifying numbers, and they are internally represented by those numbers, it is much easier to work with character data than in a system where the same number may mean different characters, depending on encoding or font or other issues. However, efficiency is relative. In particular:
Unambiguity may look like a self-evident principle, but not all character codes are unambiguous in the Unicode sense. For example, ISO 646 permits variation in some code points, allowing the use of a single code point for either # or £ by special agreement. Moreover, in Unicode, unambiguity also means unambiguity across time and versions: a code point, once assigned, will never be reassigned in a future version. Sometimes a fourth fundamental principle, uniformity, is mentioned. It has been described as a principle of using a fixed-length character code, to allow efficient processing of text. However, as currently defined, Unicode does not use a fixed-length code in a simple sense. In some Unicode encodings, all characters are represented using the same number of octets (or bits), but in many important encodings, such as UTF-8, the lengths may vary. 4.1.2. The 10 Design PrinciplesThe Unicode standard describes "The 10 Unicode Design Principles, " where the first two are the same as those quoted in the previous section, universality and efficiency. The unambiguity principle is not included. Obviously, the principles are meant to describe how Unicode was designed, whereas the slogan "Universality, Efficiency, Unambiguity" is meant to describe the ultimate goals. The standard admits that there are conflicts between the principles, and it does not specify how the conflicts are resolved. As a whole, the set of principles describe ideas of varying levels (from fundamentals to technicalities), and it should be read critically. It is however important to know the underlying ideas, so we will discuss them briefly:
Somewhat surprisingly, the list does not mention stability or continuity. Yet, one of the leading principles in Unicode strategy (as described in the goals as "unambiguity") is that a code point assignment once made will never be changed. When a number and a name have been given to a character, they will remain in all future versions, though the properties of the character may be changed. Another key principle that is not mentioned explicitly is that each character has only one code. As we will see, it is debatable whether Unicode actually follows that principle. Equivalent sequences can even be seen as a strong deviation from the principle. 4.1.3. UnificationUnification means treating different appearances and uses of a symbol as one character rather than several characters. Unicode performs extensive unification, although with many exceptions. In the section "Criticism of Unicode" later in this chapter, we will address the question of whether Unicode has gone too far in unification. Unification ranges from obvious decisions, like treating the "a" used in English as the same character as the "a" used in French (even though the pronunciation differs) to controversial identification of a Chinese character with a quite different-looking Japanese character because of their common origin. Do not expect to find perfect logic behind the decisions. Basic decisions on unification in Unicode include the following:
4.1.4. Conformance RequirementsThe Unicode standard defines conformance criteria. This just means that if some software satisfies them, it can be said to conform to the Unicode standard. This helps other software designers as well as potential customers in evaluating the software. In this context, "software" is to be understood in a wide sense, covering computer programs, parts of programs, complexes of programs, applications, data formats, etc. For the purposes of conformance requirements, the standard defines some properties of characters as "normative." This means that software that claims conformance to the standard is required to process characters according to those properties, to the extent that it processes them at all. Other properties defined in the standard are called "informative." Conformance does not require support to all Unicode characters, on display or otherwise. Software that conforms to the Unicode standard may process just a subset of Unicode characters, and this is quite normal because Unicode is an evolving standard: new characters have been added and will be added. We do not want to make conforming software nonconforming just because a rare hieroglyph is added to Unicode. When some software or data format is described as being based on Unicode or as supporting Unicode, this does not constitute a conformance clause. Quite often, such statements simply mean that the character concept used is that of Unicode. For example, HTML and XML make no claim on Unicode conformance, although they make use of Unicode definitions. Thus, HTML or XML implementations are not required to process characters according to Unicode semantics and rules, though they may do so, for some meanings and rules at least. Full presentation of the conformance requirements needs many detailed concepts related to character properties. Therefore, it will be given at the end of Chapter 5. 4.1.5. Unicode and ISO 10646ISO 10646 (officially ISO/IEC 10646) is an international standard, by ISO and IEC. It defines UCS (Universal Character Set), which is the same character repertoire as in the Unicode standard, with the same code numbers. ISO 10646 and the Unicode standard are not identical in content but they are fully equivalent in matters covered by both standards. The number of the standard intentionally reminds us of 646, the number of the ISO standard corresponding to ASCII. The rest of the number depends on ISO standard numbering in general. ISO and IEC are widely recognized international standardization organizations with a broad range of activities, from light bulb standards to general quality control standards. They work on what are regarded as "official standards" especially by governments and officials, although the standards themselves are mostly recommendations, not enforced by law. The Unicode standard, on the other hand, is a standard defined by the Unicode Consortium, which has a relative focused area of activity. Originally founded for character code standardization, the Consortium has taken new responsibilities, such as creating a common basis for software localization settings. The Unicode standard is sometimes informally cited as "TUS." Originally, ISO 10646 and the Unicode standard were two different standards created by different organizations, with different objectives. The threat of mutual incompatibility and divergence lead to a decision on full harmonization. The character repertoires were merged into one in 1992. The standards are now in full accordance, and any changes are made in a synchronized way: any change must be approved both by the Unicode Consortium and by the ISO. The harmonization wasn't easy, and it involved changing many character names defined in Version 1.0 of Unicode as different from the ISO 10646 names. However, full accordance does not mean identity. ISO 10646 is more general (abstract) in nature, whereas Unicode "imposes additional constraints on implementations to ensure that they treat characters uniformly across platforms and applications," as they say in section "Unicode & ISO 10646" of the Unicode FAQ. Moreover, each of the standards contains definitions not present in the other standard. We might say, a bit loosely, that ISO 10646 is more theoretical and the Unicode standard is more practical. ISO 10646 deals with characters, whereas Unicode also describes properties of characters as elements of text, in a manner that affects processing of text. The ISO 10646 standard has not been put onto the Web. It can be bought in digital (PDF) form via the site http://www.iso.org. For practical purposes, the same information is in the Unicode standard. In practice, people usually talk about Unicode rather than ISO 10646, partly because we prefer names to numbers (especially in speech), partly because Unicode is more explicit about the meanings of characters. However, if you write a document for a national standardization body, for example, it is appropriate to cite ISO/IEC 10646 rather than Unicode, although you might mention Unicode in parentheses. Some ISO standards are divided into "parts," which can in fact be rather independent (though interrelated) standards, such as ISO-8859-1 and ISO-8859-2. The part number is written after the basic number and separated from it with a hyphen. Previously, there were two parts in the ISO 10646 standard: ISO 10646-1 defined the overall structure and the characters in the Basic Multilingual Plane (BMP), whereas ISO 10646-2 defined the other planes (see the section "Coding Space" later in this chapter). However, in 2003, the parts were combined into one. Full references to ISO standards mention the year of issue of the version of the standard, such as ISO/IEC 10646:2003. The versions do not directly correspond to Unicode versions, since changes that mean a new version of Unicode are often implemented as documents called amendments on the ISO side. Within the ISO, work on ISO 10646 belongs to the scope of the Joint Technical Committee (JTC) 1, subcommittee (SC) 2, "Coded Character Sets." The word "Joint" refers to the cooperation between the ISO and the IEC. The web site of JTC 1/SC 2 is http://std.dkuug.dk/jtc1/sc2/. 4.1.6. Why Go Beyond 16 Bits?The original design defined Unicode as a 16-bit code, and you can still find references that describe it that way. A structure of 16-bit codes for all characters internally is very simple and it is in many ways efficient, at least in processing of data, if not always in storage and transmission. It was once regarded as sufficient for all commercially important characters in the world. Thus, there must have been good reasons to go beyond it. There are several reasons why 16 bits, or 65,536 code positions, were not enough:
It would have been possible to deal with all of these problems by using special extension mechanisms such as surrogate pairs. It was ultimately decided, however, that a unified approach is better. 4.1.7. Does Unicode Contain All Characters in the World?Quite often, Unicode is said to contain all characters used by humans. Although Unicode contains the vast majority of commonly used characters, it is far from all-encompassing. However, we can say that characters that cannot currently be written in Unicode are exceedingly rare, in terms of the number of users at present and the amount of modern printed matter or material in digital form. The most important kinds of exceptions to the coverage of Unicode are:
The Unicode standard is therefore under continuous development. For example, Version 4.1 of Unicode (March 2005) introduced 1,273 new characters, including some complete (archaic) scripts. The goal is to include all characters used in writingi.e., in textsas opposed to all possible graphic symbols. For example, the symbols of card suits are originally not text characters, but they are widely used in texts, such as bridge columns ("a contract of 3 As a different issue, Unicode does not contain and does not aim at containing all characters as separately coded characters with their own code points. Instead, characters with diacritic marks can be represented as a character sequence consisting of a base character and one or more combining diacritic marks. 4.1.8. Identity of CharactersIn Chapter 1, we discussed the concept of character and described how Unicode defines particular characters by assigning a code number, a Unicode name, and various properties to it and by showing a representative glyph. Here we consider some of the more technical aspects of defining characters. 4.1.8.1. Characters as elementary units of textIf we consider normal English text, it looks rather obvious what the elementary units of text are: letters, digits, spaces, punctuation marks, and a few special characters like $. These units look indivisible, atomic, at any structural level. None of the characters appears to be a composition of other characters, or of any parts. Things get more complicated in other writing systems, and we need not consider anything more complicated than accented letters e.g., letter e with acute accent, é. Is it a character on its own, or is it a combination of "e" and an acute accent? Unicode codes it in both waysi.e., allows é to be represented as one character or as two characters. In the latter representation, we are in fact treating the acute accent as a separate character. However, Unicode does not always consider letters with marks as decomposable into a letter and a mark. For example, the Arabic letter sheen (shin) ش (U+0634) is visually the same as the letter seen (sin) س (U+0633) with a special mark (three dots) on it. Unicode codes them as completely separate, with no mapping between them. This corresponds to the way in which people using the Arabic script understand these letters. Similarly, the letter L with stroke Different ligatures are handled differently, too. The typographic ligature A digraph i.e., a combination of two characterscan be treated as a basic unit of text, even if its shape is not ligature-like but the two glyphs are clearly distinct. For example, in some languages, the digraph "ch" is treated as a letter, with a position of its own in the alphabet. Even if the digraph is not understood as a letter in every way, it might be treated separately when putting words into a dictionary order. Although this is not the case in English, speakers of English understand "ch" as a combination with a typical phonetic value, so it has more identity than a casual combination of characters has. As we have already discussed in Chapter 1, Unicode often defines separate characters in situations where there is little or no visible difference. It is a matter of convention, history, and structure of writing systems that we regard the letter "A" as different from the capital Greek letter alpha, which normally looks just the same. As another example, we often treat lowercase and uppercase letters "the same" without even thinking about it; for example, we usually expect searches to be case-insensitive. Thus, the abstract character concept does not always correspond to the intuitive notion of a character in people's minds. Sometimes it helps to use the phrase Unicode character to emphasize that we are referring to a character as coded in Unicode, even if many people would treat it as just a part of a character, or a combination of characters, or "the same" as some other Unicode character. 4.1.8.2. Unicode numbersAs described in Chapter 1, Unicode assigns two immutable identifiers to a character that has a code point: a number and an alphanumeric string called the Unicode name of the character. For example, $ has the number 24 (hexadecimal) and the name "dollar sign." The range of possible Unicode numbers has been defined so that the numbers can be expressed using 21 bitsi.e., as strings of 21 zeros and ones representing the number in binary (base 2) notation. However, the full range of numbers representable in 21 bits is not used. Instead, Unicode limits the range to just over one million numbers, as expressed more exactly in Table 4-1 in different number systems. In the Unicode context, we mostly use the base 16 system, which was described in Chapter 1.
There are still many documents that describe Unicode as a "16-bit code," but that has not been true for a long time. Neither is Unicode a "32-bit code," although this misconception is less serious. In practice, Unicode code numbers usually appear as represented using units of 8, 16, or 32 bits according to some well-defined scheme. However, if you need to characterize Unicode as an "n-bit code," the best choice for n is 21. The assignment of numbers to characters is arbitrary in the sense that the number has no relationship with the meaning of the character. For example, digit zero does not have the number 0 but the number 48 (in decimal). This is the same as its number in ASCII and many other character codes, but other than that, there is no way you could have guessed it. In particular, the Unicode numbers should not be treated as significant in comparing characters. If the number of a character is smaller than the number of another character, this does imply that one is before the other in the alphabet or collating sequence in some language. It happens that the code number of "a" is one less than the code number of "b," but you would get the order quite wrong if you alphabetized, for example, French words on the assumption that the code numbers tell the order. For example, all words beginning with é would be sorted after all words that begin with any unaccented letter, since the code number of é is greater than the code numbers of all basic Latin letters.
In practice, the allocation of Unicode numbers is not random or arbitrary, even though it may look messy. Characters are organized into blocks, and within each block, the allocation usually reflects some traditional order. The allocation is discussed in more detail in the section "Coding Space" later in this chapter. 4.1.8.3. Unicode names of charactersThe Unicode name of a character is defined as follows:
The Unicode names of characters are based on the English language, with many loanwords taken from other languages. Interpreted as an expression in English, the Unicode name of a character is usually descriptive, but it might be uninformative, and sometimes even misleading. The Unicode name is called the formal name in the Unicode standard, to distinguish it from an alternative name (alias). Alternative names are mentioned in the code charts, and they also appear in the NamesList.txt file in plain text. They are comment-like and can be changed or removed. For example, the Unicode standard once mentioned "hyphus" as an alternative name for hyphen-minus, but this was an attempt at coining a new word rather than be descriptive, and it was silently removed from the standard. For some characters, a Unicode 1.0 name is mentioned, too, such as "period" for "full stop" and "slash" for "solidus." As the examples show, the Unicode 1.0 names often correspond better to the names normally used in U.S. English. A Unicode 1.0 name is essentially just an alternative name, although it is written in uppercase in the code charts. Formally, it differs from other alternative names by its appearance in the UnicodeData.txt file. The Unicode 1.0 names reflect the harmonization of Unicode with ISO 10646: in Version 2.0, Unicode adapted ISO 10646 names for characters if there was a mismatch of names, and the old names were preserved as comments. The Unicode name proper (the formal name) is fixed partly because it may have been used in programming. It is usually not a good idea to identify characters by their names in program code, but such approaches have been used, especially in old times. The Unicode names are identifying strings rather than normal text, but for the purposes of reading them aloud, they are English. They contain both English words and words from many other languages, adapted into English orthography. As the names "full stop" and "solidus" indicate, the English language in the names is basically British English. This is reflected in spellings like "centre" and "diaeresis." In this book, the Unicode names are spelled as defined, of course, although words like "dieresis" appear in U.S. English spelling when used in the prose text. 4.1.8.4. Using the namesDespite many problems with the official (formal) Unicode names of characters, they are very useful. When you need to specify exactly which character you are referring to, it is usually a good idea to mention both its Unicode name and its Unicode number. When writing for general audience, it might be best to use just commonly used names about characters. For example, if you are giving instructions on using a special symbol in some particular way when using some program, you could just tell people to use #, without mentioning its name. People know it by so many different names that they might get confused, even though they know the character when they see it. If you specify a name, you could list some commonly used names along with the Unicode name. You could tell people to use # (number sign, also known as hash and octothorpe). When referring to rare characters, names become essential. If you write style instructions for technical papers, for example, just telling people to use ࣺ in some context will not work well. Most of them will think that you mean the character ø that can be conveniently found among the Latin 1 characters. It is better to tell them to use the DIAMETER SIGN ࣺ (U+2300), though they may still need instructions on typing it. Software tools for selecting characters, such as the characters maps discussed in Chapter 2, often identify characters by their code numbers and Unicode names. This is in many cases insufficient, and it has caused misunderstandings. Some names are misleading or too vague, and some names are theoretical rather than commonly used names. They are often hard to understand to people who do not speak English as their native language. In the future, language-dependent names for characters might be defined in the Common Locale Data Repository (CLDR) discussed in Chapter 11. Meanwhile, most characters have no official or established names in most languages. This is one reason why the Unicode names are used so often.
The Unicode names are useful when searching for information, using Google, for example. Most Internet search engines treat all or most non-alphabetic characters as irrelevant (skippable, punctuation) or as special operators. Thus, you cannot search directly for ¶, for example. Instead, you might search for "section sign," once you know the character by its Unicode name. Of course, not all documents that use the character or even those that say something about it, mention it by that name. The alias names mentioned in the Unicode standard are often very useful, too. Generally, documents that seriously discuss a character can be expected to mention its Unicode name. This implies that as an author, you would do wisely to mention the Unicode name (spelled exactly right), if you write about a character. Mentioning the Unicode number in the U+2300 style is useful, too, since people might use it, too, and have success in searches. 4.1.8.5. Characters used in character namesThe characters that may appear in a Unicode name are:
This simple repertoire makes it usually rather straightforward to construct identifiers that correspond to character names, for use in computer programs, database entries, etc. Usually identifier syntax disallows spaces, but you can replace spaces by low line (underscore) "_" characters without ambiguitye.g., using COMMERCIAL_AT. The hyphen-minus character can be more problematic, if identifier syntax disallows it. Digits have been avoided in Unicode names; even the digits themselves have names like "digit zero." Some names, however, contain digits, because they have been generated algorithmically, by enumeration (e.g., "Greek vocal notation symbol-1"), or using the code number as part of the name (e.g., "CJK unified ideogram-4E00"). Such names are not very practical, and they have been included just to give every character a formal name. Braille pattern character names contain digits that indicate the positions of dotse.g., "Braille pattern dots-1245." A few names contain digits because they refer to the shapes of digitse.g., "double low-9 quotation mark." 4.1.8.6. Case of letters in namesTechnically, the standard defines the letters used in Unicode names as uppercase. No ambiguity can arise, however, from using lowercase. The variation should be considered as typographical only, since the case of letters is not significant in Unicode names. Any processing that takes such a name as input should thus first normalize the spelling to uppercase or lowercase or perform all comparisons in a case-insensitive manner. In a user interface that shows Unicode names, it is probably a good idea to make the case a user-settable option, with uppercase as default. 4.1.8.7. Notational issuesThe number of a character is usually written in hexadecimal notation, using at least four digitse.g., "0040." It is often preceded by "U+" for claritye.g., "U+0040." The "U+" prefix may help both human readers and computer programs to distinguish character numbers from other numbers or digit sequences in a document. The original idea was to use a special character, multiset union U+228E, There is more variation in the writing style of the name. The standard uses mostly all uppercasee.g., "COMMERCIAL AT." If you use this style in a publication, it is a good idea to try to use a small caps font or a normal font in a smaller size (e.g., COMMERCIAL AT), to avoid making the names all too prominent. Another style, used in the standard for alias names and in annotations, is all lowercase, even for words that are capitalized in normal English, as in "greek question mark." 4.1.8.8. UCS Sequence Identifiers (USI and named character sequences)Combining diacritic marks, discussed in Chapter 7, create a general method for forming new characters from a base character (such as "e") and one or more diacritic marks, producing a character like é or ë. This creates a new problem of identity: although characters like é and ë already exist as separately coded characters in Unicode, most potential combinations do not; should each of them be still regarded as a character, or just as a character sequence? For example, does letter "e" with a combining acute accent and a combining dieresis constitute a single character, or just a sequence of three characters, although rendered using one glyph? The short answer is that such a sequence is technically a character sequence in Unicode, but it can be regarded as a single character in other contexts and frames of reference. Unicode is capable of representing the character, though as a sequence of Unicode characters and not as a single character. The general idea is that the existing repertoire of precomposed characters in Unicode will normally not be extended. This saves work and coding space, and it helps to avoid long discussions. After all, commonly used characters with diacritic marks have already been incorporated into Unicode as precomposed characters, so the rest are rather specialized, and few people would be competent in deciding on them. This has caused some controversy. If you speak a language that needs such a combination, you might be dissatisfied with the statement that it is and will remain a character sequence, not a character. You might want better "characterhood" for the element of your language. Partly for such reasons, the concept of UCS Sequence Identifier (USI) was introduced in ISO 10646. A USI is of the form <UID1,UID2,...> where UID1 and so on are short identifiers for characters, usually in the U+nnnn notation. For example, <U+012B,U+0300>. USIs also serve the purpose of assigning distinguishable identity to other sequences, such as the character pair "ch," which may appear as a single unit to many. In some languages, "ch" has both a special pronunciation and a special role in ordering, where it might appear as if it were a letter after "c" (so that words beginning with "ch" are ordered after all other words beginning with "c"). Unicode takes a further step in assigning "characterhood" to character sequences by introducing the notion of a named character sequence, defined in Unicode Standard Annex (UAX) #34 at http://www.unicode.org/reports/tr34/. A named character sequence is simply a name for a USI. The name follows the general syntax of Unicode names of characters, though with some special restrictions. For example, the sequence <U012B,U+0300> has the name "Latin small letter i with macron and grave," which looks very much like a Unicode name for a character. Thus, when someone says that such a character ( This strategy has not been as successful as you might think. There is a fairly small number of named character sequences currently defined. The registry of definitions for them is the text file http://www.unicode.org/Public/UNIDATA/NamedSequences.txt. The approach might still turn out to be useful, especially in giving advice to font designers about sequences that might need a separately designed glyph. |
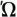 ), but the decomposed form of this character still consists of omega followed by combining tonos.
), but the decomposed form of this character still consists of omega followed by combining tonos.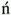 sk), even though traditional typography for the languages uses rather different shape for the acute. The acute accent is even unified with the Greek tonos mark (e.g., on first letter in "
sk), even though traditional typography for the languages uses rather different shape for the acute. The acute accent is even unified with the Greek tonos mark (e.g., on first letter in " ρα"), even though it is commonly called tonos and not acute and even though its traditional shape is different from both French and Polish style. Often you do not see differences in the shapes of a diacritic because typically each font has a uniform design for a diacritic. However, a diacritic on a Latin letter often looks different from the same diacritic on a non-Latin letter.
ρα"), even though it is commonly called tonos and not acute and even though its traditional shape is different from both French and Polish style. Often you do not see differences in the shapes of a diacritic because typically each font has a uniform design for a diacritic. However, a diacritic on a Latin letter often looks different from the same diacritic on a non-Latin letter.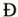 and Latin capital letter "D with stroke
and Latin capital letter "D with stroke 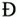 are coded as separate characters, since the corresponding lowercase letters look quite different:
are coded as separate characters, since the corresponding lowercase letters look quite different:  and
and  . Without the difference, it would be impossible to convert text from uppercase to lowercase using simple algorithms.
. Without the difference, it would be impossible to convert text from uppercase to lowercase using simple algorithms. , with
, with  9 lead), and therefore the symbols are defined as Unicode characters. Many archaic writing systems contain characters that have been or will be included into Unicode due to their use in texts, such as digitized versions of old documents and modern research papers that discuss such documents and their language. On the other hand, characters of the fictional Klingon language are not commonly used in texts, so they have not been included into Unicode so far. The language's fictional nature is no obstacle per se; what matters is actual use in books, magazines, web pages, or elsewhere.
9 lead), and therefore the symbols are defined as Unicode characters. Many archaic writing systems contain characters that have been or will be included into Unicode due to their use in texts, such as digitized versions of old documents and modern research papers that discuss such documents and their language. On the other hand, characters of the fictional Klingon language are not commonly used in texts, so they have not been included into Unicode so far. The language's fictional nature is no obstacle per se; what matters is actual use in books, magazines, web pages, or elsewhere. (U+0141) is not decomposable. On the other hand, Unicode defines the Cyrillic letter short i
(U+0141) is not decomposable. On the other hand, Unicode defines the Cyrillic letter short i  (U+0439) as decomposable into the Cyrillic letter i
(U+0439) as decomposable into the Cyrillic letter i  (U+0438) and a diacritic mark (breve), although people who use these letters hardly see things that way.
(U+0438) and a diacritic mark (breve), although people who use these letters hardly see things that way.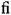 can be written as a single character, but it is only a compatibility character. On the other hand, æ is treated as a separate character with no decomposition, although it is historically a ligature and is still used as a typographic alternative to "ae when writing Latin words.
can be written as a single character, but it is only a compatibility character. On the other hand, æ is treated as a separate character with no decomposition, although it is historically a ligature and is still used as a typographic alternative to "ae when writing Latin words.
 , in front of a code number. This character, consisting of the symbol of union of sets and a plus sign, was meant to symbolize the nature of Unicode as a union of character sets, and more. However, for practical reasons, the symbol was soon replaced by the two ASCII characters "U+."
, in front of a code number. This character, consisting of the symbol of union of sets and a plus sign, was meant to symbolize the nature of Unicode as a union of character sets, and more. However, for practical reasons, the symbol was soon replaced by the two ASCII characters "U+." ̀) should be added into Unicode, one can say: it can be written using existing Unicode characters, and the sequence has even got a name, so you can treat it as a character.
̀) should be added into Unicode, one can say: it can be written using existing Unicode characters, and the sequence has even got a name, so you can treat it as a character.