Section 11.6. Identifiers, Patterns, and Regular Expressions
11.6. Identifiers, Patterns, and Regular ExpressionsIn the section "Classification of Characters" in Chapter 5, we preliminarily mentioned the use of defined Unicode properties for the purposes of defining identifiers (names) and patterns of strings. Here we will discuss the issue more technically. Identifier syntax and pattern syntax had previously been treated as different issues. Unicode combines the two intrinsically to some extent, and the Unicode standard presents them together in Unicode Technical Report #31, "Identifier and Pattern Syntax," http://www.unicode.org/reports/tr31/. One reason for this is that patterns, as used in, for example, search clauses, may need to contain identifiers. 11.6.1. IdentifiersAn identifier is a defined name for something. Identifiers are extensively used in many computer languagese.g., as names of constants, variables, and functions in programming languages or for aggregates and components of data, such as table rows. An identifier is a formal name in the sense that it is formed according to specific rules and it is kept the same, unless explicitly changed. An identifier is often shorter than names used in natural languages. For example, the ISO 3166 standard defines two-letter identifiers for countries, to be used as language-independent immutable code names. (In practice, it does not quite work that way. Sometimes the codes are changed for political reasons.) 11.6.1.1. Identifiers: internal or external?In most contexts, identifiers are internal symbols that are not visible to end users of applications. However, usually identifiers are meant to be more or less mnemonic and descriptive of their meaning, to make computer code more readable and easier to maintain. Certainly, totalPopulation is easier to understand than x78. In practice, programmers often use short identifiers such as n and x especially for variables used very locally. In such style, c or ch often denotes a character variable and s a string variable. When the native language of a programmer or a group of programmers is not English, it may be desirable to be able to use a wider character repertoire. Especially if the documentation and comments are written in some other language, it would be natural to use that language in identifiers, too. Besides, identifiers might stand for things that have natural names in some language. For example, if you assign identifiers to municipalities of France, it would be natural to use accented letters in them, even if you do not use the French names as such. Identifiers may become visible to end users, perhaps even as something that they need to type. An example is the naming of Internet domains (such as www.oreilly.com), where the components can be regarded as identifiers. (This particular issue was discussed in Chapter 10.) End users often seen identifiers in error messages and user interfaces, even if the programmers may have regarded the identifiers as purely internal and technical. On the Web, pages that use frames need to use identifiers for them. Authors have typically used short and often cryptic names like frame1 or left for them. Problems arise when people use browsers that implement frames in ways that authors did not anticipatee.g., browsers that read the names of frames aloud, asking the user to choose between them. 11.6.1.2. Traditional format of identifiersEach computer language and data format that uses identifiers needs to define its identifier syntax, and there is a lot of variation in it. However, conventionally, the definitions have been relatively simply, allowing just a subset of ASCII. More exactly, the definitions typically allow ASCII letters, digits, and a small collection of special characters. Usually the first character of an identifier has to be a letter, or in some cases, a character treated as equivalent to a letter, such as _ or $. The reason is that when parsing, for example, a computer source program, you need to be able to distinguish identifiers from other atoms of text, such as numbers and punctuation symbols. For example, when a programming language compiler or interpreter reads "a+b" in program source, it needs to know whether + is allowed in identifiers or not. If + were allowed, special rules would be needed to make it possible to distinguish such use of + from its use as an operator. For similar reasons, a space is usually not allowed in identifiers. A hyphen is typically not allowed either. Since identifiers are often formed from two or more words of a natural language, this poses a problem. The usual solutions are: just writing words together (e.g., openwindow), using case variation (openWindow), and using the low line (underscore), if the identifier syntax permits that (open_window). If identifiers occur in a limited context onlyi.e., in particular fields of a data structure, there is much less need to use a restricted syntax for them. The typical identifier syntax is designed for use in contexts where identifiers appear in the midst of program code or other data and need to be recognized easily. However, even when identifiers occur in specific contexts only and need not be parsed from text, safety considerations often lead to some restricted syntax. When using traditional formats of identifiers, a specific syntax for them needs to decide on the following matters:
The Unicode names of characters do not conform to this traditional syntax, since the names may contain spaces. When the Unicode names are used as identifierse.g., in programming languagesthe specific syntax might specify that spaces are replaced by underline characters. However, in some contexts, spaces are permitted. 11.6.1.3. Case sensitivityCase sensitivityi.e., whether lowercase and uppercase letters are equivalentis an important feature but external to identifier syntax. The syntax only defines the allowed format of identifiers. At the dawn of the computer era, there were no lowercase letters available. Later, they were typically treated as equivalent to uppercase letters, and this is still common in many contexts. A more modern style, such as the one applied in Java and in XML, is to treat lowercase and uppercase as distinct, making a and A two identifiers that are no more connected to each other than a and b are. 11.6.1.4. The Unicode approach to identifiersThe identifier concept described in the Unicode standard is a generalization of the traditional identifier syntax. It is a basis upon which you can build different syntax definitions for identifiers, rather than a standard identifier syntax per se. As UTR #31 itself puts it, it provides "a recommended default for the definition of identifier syntax." For example, the syntax of programming language identifiers could be defined by saying that it is the Unicode identifier syntax with the addition that the £ character is treated as an Identifier Start character. The syntax is very similar to the traditional syntax of identifiers, just with a possibility of using much wider repertoires of characters in a convenient way. 11.6.2. PatternsPatterns are used to describe the format of strings, for the purposes of searching and recognizing components of a string. For example, for reading numeric data, some pattern is needed for recognizing strings that constitute numbers. The specific pattern used determines, among other things, whether ".0" or "0." is a number or whether a digit is needed on either side of the decimal point. Similarly, the pattern specifies whether a period or a comma is used as the decimal separator (or whether either of them is allowed). The structure of identifiers is a pattern, too. Patterns can be very simple or very complex. For example, a pattern might specify the format of lines in a logfile as just a sequence of characters from a particular set. It could alternatively describe the structure of a line as containing particular fixed strings, intermixed with other strings with some internal structure, such as sequences of digits or letters, perhaps of a particular length. The word "pattern" as used in the context of string processing has two meanings:
We are here interested in patterns in the latter, technical sense. Such a pattern itself is a string of characters. It may contain characters of three kinds:
If a character is defined as a syntax character or as a whitespace character in some formalism, it cannot be directly used as a literal character. The reason is obvious: if you tried to do so, the program that processes the pattern would treat the character by its defined meaning in the syntax or as whitespace. Formalisms typically contain methods for escaping characters so that they can be used in the role of a literal character. Several escape mechanisms were mentioned in Chapter 2. A rather common method is to prefix a character with the backslash (reverse solidus) \ (e.g., \\ to escape the backslash itself). 11.6.3. Identifier and Pattern CharactersThe Unicode approach distinguishes the following disjoint sets of characters for use in identifiers and patterns. The names in parentheses are the long and short name of the property that indicates, for each character, whether it belongs to the set (see Chapter 5):
The policy that Pattern Syntax Characters and Pattern Whitespace Characters are fixed (closed) sets does not mean that actual identifier syntax needs to use exactly those sets. On the contrary, fixing the sets makes it easier to define identifier syntax on a Unicode basis: it can be defined using the Unicode syntax as an immutable base and adding or removing characters as desired. Of course, if a specific identifier syntax definition makes a character such as $ allowed in an identifier, it is removed from the Pattern Syntax Characters set in that syntax; the three sets must be disjoint. The Identifier Characters and the Identifier Start characters are listed in the DerivedCoreProperties.txt file of the Unicode database. As the name of the file suggests, the definitions have been derived from other Unicode properties, in this case, mainly from the gc (General Category) property. Identifier Start characters include the following:
Other Identifier characters include:
11.6.4. Identifier SyntaxIdentifier syntax is defined simply so that an identifier consists of one Identifier Start character followed by zero or more Identifier characters (i.e., Identifier Continue characters). Thus, program code that scans an identifier can be quite simple, if you can use functions that check for a character being an Identifier Start or Identifier Continue character. The syntax thus generally allows, among other things, words and abbreviations written in languages that use an alphabetic writing system or an ideographic writing system. Examples: años, Ψυχ 11.6.4.1. NormalizationThe identifier syntax allows nonspacing marks like accents. You can use an identifier like résumé, because é is defined to be a letter, but you could also use an identifier that contains é as decomposed into "e" and a combining acute accent, U+0301. This means that you can also use a combination of a letter and one or more diacritic marks that does not exist in Unicode as a precomposed character. Nonspacing marks create the question of whether identifiers are regarded as equal if the only difference is that one of them contains a precomposed character like é and the other contains the corresponding decomposed character. The definition of identifier syntax may specify that such identifiers be treated as the same, by specifying that Normalization Form C (as described in Chapter 5) is to be used. Normalization is an optional feature in identifier syntax. If used, the particular normalization form has to be specified. The definition may list characters that are to be excluded from normalization. There are special rules to be applied if Normalization Form KC is used. The standard does not define a general method for ignoring diacritic marks in identifiers. If you wish to allow diacritic marks in identifiers, you are more or less supposed to treat them as significant. Outside Unicode identifier syntax you could, however, normalize to Normalization Form D (canonical decomposition only), and then perform a comparison that ignores nonspacing marks. 11.6.4.2. Case foldingSimilarly to normalization, case folding is an optional feature. The definition of identifier syntax may specify either simple or full case folding (as described in Chapter 5). If case folding is specified, identifiers are internally mapped to lowercase. This of course applies to accented letters too, so résumé and RÉSumé would be treated as the same. Somewhat surprisingly, the standard says: "Generally if the programming language has case-sensitive identifiers, then Normalization Form C is appropriate, while if the programming language has case-insensitive identifiers, then Normalization Form KC is more appropriate." Logically, however, case sensitivity is quite independent of the difference of these normalization forms: Form KC includes compatibility decomposition. 11.6.4.3. Identifiers (names) in XMLXML1.0 has an identifier syntax that is similar to the general Unicode identifier syntax but is defined in a different way. The definition is fixed: addition of new characters, even letters, to Unicode does not extend the character repertoire in XML identifiers. We will first consider XML 1.0 identifiers, and then the broader XML 1.1 identifier syntax. XML identifiers are important due to the widespread use of XML for various purposes, often in contexts where identifiers might be shown to or written by end users. Identifiers are used to name elements, attributes, enumerated values of attributes, entities, etc. Of course, XML-based markup systems usually define a finite set of identifiers, and it is still common to use ASCII characters only in them. In designing markup systems and in processing generic XML, it is important to know the exact syntax. XML identifier syntax, or name syntax as the XML specification calls it, is based on fixed rules derived from "Properties of characters in Unicode version 2.0." These definitions are presented as explicit lists in the XML specification, at http://www.w3.org/TR/REC-xml/#CharClasses. It is however much easier to understand the definitions, when you consider the design principles:
Thus, the XML name syntax has been defined rigorously and in a stable manner, but the definition is far from intuitively clear and easy to remember. Table 11-8 summarizes the main points, though it does not express all prohibitions.
In XML 1.1, the approach is different: the identifier syntax is more permissive, based on allowing everything that need not be excluded for specific reasons. However, there are few implementations of XML 1.1. Usually, it is impractical to try to use XML 1.1, unless you need the extended identifier syntax or similar features of XML 1.1 and you can use an XML 1.1 implementation. The XML 1.1 name (identifier) syntax is simpler than XML 1.0 name syntax. Almost all characters are permitted in names, excluding mostly just characters that need to be treated as punctuation, or generally as delimiters in a context where names are used. Thus, the syntax is best described negatively. Table 11-9 lists characters that are disallowed in XML 1.1 names either completely or as the first character. In the "Status" column, "no" means that the character is disallowed, "cont." means that it is allowed as a continuation character only (not at the start), and "special" means that it has special meaning. The XML 1.1 specification contains a non-normative appendix "Suggestions for XML names," which recommends additional restrictions.
Although the definition of XML 1.1 names is more concise than the definition of XML 1.0 names and includes large ranges, implying extensibility (new Unicode characters will be automatically allowed), it is still somewhat difficult to use. Some characters (such as U+037E) have been excluded in a matter that looks random, though there are reasons behind the exclusions (e.g., U+037E is canonical equivalent to semicolon). 11.6.5. Alternative Identifier SyntaxThe Unicode standard also specifies an alternate, more permissive syntax for identifiers. It is based on the idea of excluding some characters from use in identifiers and allowing the rest. The characters excluded are those that are reserved for syntactic use, so that identifiers can be distinguished from text. Syntax analysis based on this approach can be implemented more efficiently, since the exclusion set is fixed and small. Thus, as new characters are added to Unicode, they automatically become available for use in identifiers. In fact, they already are: the approach means that even unassigned code points are allowed in identifiers. If a future version of Unicode assigns a character to a currently unassigned position, nothing happens in the alternative identifier syntax. At another level, though, a document that uses such a code point gains a better status with respect to the Unicode standard. Thus, a scanner (parser) for identifiers using the alternative identifier syntax need not be changed, if the Unicode standard is changed. On the other hand, the approach has drawbacks, too. The permissive syntax is too permissive for many purposes. It has been described as allowing nonsensical identifiers that lack any human legibility. However, even using the normal syntax, it is easy to write identifiers that have no mnemonic value and intuitive understandability. The definition of alternative identifier syntax is simple: an identifier is a sequence of characters not containing any Pattern Syntax characters or any Pattern Whitespace characters. This definition can be used as such or as modified in some documented way by adding or removing disallowed characters. An identifier that is formed according to the alternative syntax is sometimes called an extended identifier or XID. The DerivedCoreProperties.txt file in the Unicode character database defines the properties XIDS (XID Start), indicating whether a character may start an XID, XIDC (XID Continue), which indicates whether a character may appear in an XID in general. These properties are seldom needed, since the XID approach is based on excluding characters rather than using positive lists. 11.6.6. Pattern SyntaxThe pattern syntax recommended in the Unicode standard uses fixed sets of Pattern Syntax characters and Pattern Whitespace characters as described above. Of course, this does not mean that in a particular formalism, every Pattern Syntax character needs to have a defined meaning. Rather, Pattern Syntax characters are what you may define for use in the syntax. The approach allows, and encourages, a design where the formalism requires that Pattern Syntax characters must not be used as literal characters, even if the formalism does not assign a syntactic meaning to them. This means that if such characters would be needed as literals, they must be "escaped" using some suitable mechanism. In such a design, the formalism can later be extended by assigning meanings to Pattern Syntax characters that are now unused. For example, suppose that you have defined a formalism of regular expressions that does not use the character #. Since it is a Pattern Syntax character, you would still require that it not be used as a literal character but escaped somehowe.g., as \#. Now suppose that you later extend the formalism by taking the character # into some use. This would mean that the regular expression foo\#bar would still be correct and would have the same meaning (denoting the literal string "foo#bar"). The regular expression foo#bar would become correct, with some meaning. If it were given as input to a program that processes data by the old definition of your formalism, it would generate an error message, due to the attempt to use # as a literal character. This is better than treating it as a literal, since this would not be the intended meaning. 11.6.7. Regular ExpressionsA regular expression, or regexp (or regex) for short, is a string of characters that presents a pattern of strings, for purposes of searching and matching. Strings that correspond to the pattern are said to match the regular expression. We can also say that a regular expression defines a set of strings. For example, [a-z][0-9]* is a regular expression that represents the set of strings that start with a lowercase letter "a" to "z" and continue with zero or more common digits 0 to 9. Different syntaxes are used for regular expressions, but the syntax used in the example is rather common. In simple cases, it is relatively intuitive if you just know one special rule: the asterisk * indicates that characters matching the immediately preceding part of the expression may appear any number of times, including zero. Thus, [0-9]* matches any sequence of digits, including the empty string. Another common convention is that the period . means "any character." For example, st.p is a regexp that matches "stop" and "step" but also "st8p," "st!p," etc. An alternative convention is that the question mark ? means "any character." This has caused some confusion, since formal descriptions of programming languages typically use a syntax in which the question mark indicates optionality of the preceding construct, so that, for example, c? matches the one-letter string "c" and the empty string. According to Unicode principles, the characters used in special meanings in regular expression syntax should be selected among Pattern Syntax characters. 11.6.7.1. Regexp use in programmingRegular expressions are widely used in programming, and many programming languages contain a regexp syntax and matching, searching, or replacement statements where they may be used. They often make it easy to specify the pattern matching to be performed, without needing to write the code that implements the matching. The following Perl program reads the standard input stream and prints only those lines to the standard output stream that contain the characters "U+" followed by an alphanumeric character (e.g., "U+A" or "U+9"). Note that the character + has been escaped with the backslash \, since otherwise + would have a special meaning. The notation \w denotes an alphabetic character, also called a "word" character: while(<>) { if(m/U\+\w/) { print; }}11.6.7.2. Regexp use by end usersRegular expressions have become relevant to end users, too, since search and replace operations in programs often allow their use, at least in some limited form and maybe in a program-specific syntax. In database searches, for example, regexp syntax, if available, is a powerful tool. Unfortunately, the general search engines on the Web do not support regexp syntax, but site-specific search tools may well do so. Thus, regular expressions can be important to end users of applications, not just to programmers. The concept is not widely known, though. Moreover, finding the tools and the specific syntax in a program may require some experimentation or manuals. For example, in MS Word, if you start a search (Edit Find or Ctrl-F), click on the "More" button, and check the "Use wildcards" checkbox, you can use regular expressions in the search string. By clicking on the "Special" button, you get a menu of characters and notations that have special meanings in Word regexps. The menu also lets you enter special characters (with no special regexp meaning) that might be difficult or impossible to type normally. The dialog is shown in Figure 11-2. In fact, you can use regular expressions even without checking "Use wildcards," but then you need to precede regexp syntax characters with a circumflexe.g., ^? instead of just ?. In Unix and Linux environments, it is common to use programs like grep that accept regular expressions as input. The following command would list all lines in file data.txt that contain the string "U+" followed by an alphanumeric character (cf. to the preceding example of a Perl program): grep "U\+[A-Za-z0-9]" data.txt Some special characters used in regular expressions are often called wildcards (or wildcard characters). The word comes from card games such as poker and canasta where some cards, such as jokers or deuces, may be used in place of any other card. On the other hand, the word "wildcard" often refers to a more limited syntax that gives some of the capabilities of regexp syntax. For example, in many search operations, you can use a special character, often * or #, to denote an arbitrary string (including the empty string). Thus, a database search interface might let you type synta* or synta# to refer to all words that begin with "synta" (e.g., "syntax," "syntactic," etc.). The exact meaning of such notations depends on the program, but it would typically correspond to what we could express in regexp syntax as synta[a-z]*. When using regular expressions, we often wish to use constructs that refer to "words" in a meaning that roughly corresponds to words in a natural language. For this, we may need Figure 11-2. Using regular expressions in MS Word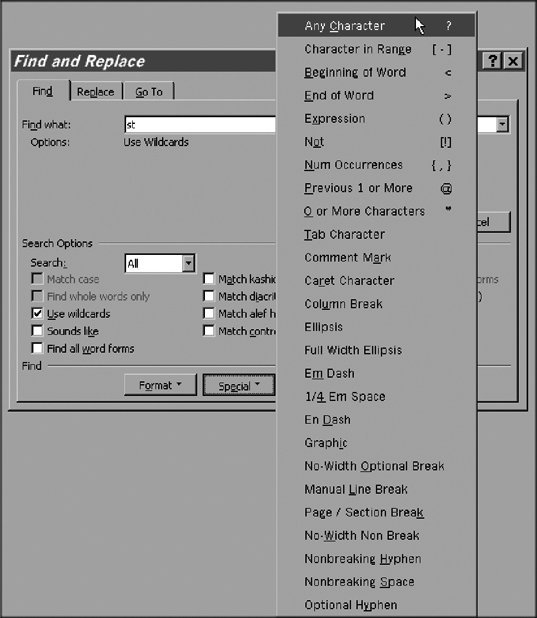 an expression for "letter." An expression like [A-Za-z] that covers only the basic Latin alphabet "A" to "Z" is too limited for most languages written in Latin letters. 11.6.7.3. Unicode regular expressionsThe use of regular expressions in conjunction with Unicode is defined in the Unicode Technical Standard UTS #18, "Unicode Regular Expressions," which is available online at http://www.unicode.org/reports/tr18/. It is not part of the Unicode standard but a separate specification issued by the Unicode Consortium. The specification defines three levels of Unicode support that a program may offer if it recognizes and interprets regular expressions:
The specification UTS #18 does not fix the specific syntax to be used for regular expressions, but it uses a sample syntax, which is based on the syntax used in Perl. The description of the Perl syntax is available via http://www.perl.com/pub/q/documentation. 11.6.7.4. Basic Unicode supportThere is no guarantee that a programming language (or an application) that recognizes regular expressions has even basic Unicode support as defined in UTS #18. However, such support is becoming common, and in learning how to use a language, it is useful to know the basic ideas as a background. Basic Unicode support requires:
The sample syntax follows the Perl approach even in the rather odd convention that the use of \P instead of \p indicates negation. For example, the regular expression \P{Letter} matches all characters that are not letters. 11.6.7.5. ExamplesUtilities like the grep program (command) exist in different versions, and modern versions generally support Unicode regular expressions. A Unicode-capable version can be downloaded from http://www.gnu.org/software/grep/. The following command illustrates simple use of such a version. The command lists those lines in a file that contain a word that begins with "B" and ends with "n." The special construct [[:alpha:]] matches any alphabetic Unicode character, including accented letters of course (so that the full expression matches, for example, "Bohusvägen" and "Blixén"). However, this functionality may depend on locale settings: grep 'B[[:alpha:]]*n' data.txt The following Perl program reads UTF-8 encoded input and prints all lines that contain a word beginning with é or É. The construct \b matches the start of a word, and the specifier i after the second slash means case-insensitive matching. The letter é is written using the special construct \N{ name } to avoid problems that might arise from writing it directly into Perl source: use charnames ':full'; binmode STDIN, ":utf8"; while (<>) { if(m/\b\N{LATIN SMALL LETTER E WITH ACUTE}/i) { print; }In Java, using modern implementations like JDK 1.4, the same operation could be coded as follows. Note that in the string defining the regular expression, "\\b\u00E9", the first occurrence of the backslash needs to be doubled, since the backslash is a special character in Java strings. Thus, in order to include it in the actual string data passed as argument, it must be escaped. A Java compiler interprets the notation \u00E9 as denoting U+00E9i.e., é'so the backslash must not be escaped. Another specialty is that when using the compile function to define a regular expression, a second argument may be used to specify flags for the matching, and a simple Pattern.CASE_INSENSITIVE would limit case folding to ASCII characters. Using Pattern.UNICODE_CASE, you request Unicode case matching rules. The input routines used here perform input in the system's native encoding: import java.util.regex.*; import java.io.*; public class RegexpExample{ public static void main(String[] args) throws IOException { Pattern regexp = Pattern.compile("\\b\u00E9", Pattern.CASE_INSENSITIVE + Pattern.UNICODE_CASE); BufferedReader infile = new BufferedReader(new FileReader(args[0])); String line; while ((line = infile.readLine( )) != null) { Matcher m = regexp.matcher(line); if (m.find()) { System.out.println(line); } } } } |
 (U+2118), estimated symbol ℮ (U+212E), and U+309B and U+309C, which are Japanese (kana) sound marks
(U+2118), estimated symbol ℮ (U+212E), and U+309B and U+309C, which are Japanese (kana) sound marks 8,
8, 


 xyz42.
xyz42. §¨©ª«¬®¯°±23´µ¶
§¨©ª«¬®¯°±23´µ¶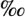
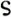 , and the capital sigma Σ must all match.
, and the capital sigma Σ must all match.