Pooling Objects
When you're developing complex applications, you need to be able to manage your resources. The resources could be a database connection, file, or some other kind of resource where the cost of initialization and destruction is high. In the Jakarta Commons project, several projects deal with managing resources using pools and caches. However, the Pool package is the simplest and most useful. For example, the dbcp package allows you to pool database connections, which is generally a good idea. You could very easily do that using the Pool package; just define a business object that contains a database connection. You don't use pooling for every object due to the overhead. With pooling, you have to write some small pieces of infrastructure code that manage objects that can be pooled.
Technical Details for the Pool Package
Tables 4.1 and 4.2 contain the abbreviated details necessary to use the Pool package.
| Item | Details |
|---|---|
| CVS repository | |
| Directory within repository | pool |
| Main packages used | org.apache.commons.pool, org.apache.commons.pool.impl |
| Class/Interface | Details |
|---|---|
| [pool].ObjectPool | A base interface that represents an object pool. The client may use this interface but must instantiate a type of object pool found in the [pool].impl package. |
| GenericObjectPool: | A simple object pool implementation. |
| GenericKeyedObjectPool | An object pool that marks individual objects by a specific key. |
| SoftReferenceObjectPool | An object pool that is managed by the JVM. The JVM will decide when to compact or expand the pool. |
| StackObjectPool | A specific type of pool that uses a specific algorithm for managing object instances. Typically, the advantage of this class is that there is no limit to active objects, but the maximum of idle number of objects is strictly enforced. |
| StackKeyedObjectPool | An object pool that manages individual objects using a specific key. The object management algorithm is the same as for the class StackObjectPool. |
| [pool].PoolableObjectFactory | A structural interface used by the Object pool to instantiate and manage the various object instances. |
| [pool].BaseObjectPool | An abstract class used by pool implementations ; it contains the basic functionality of a pool. |
| [pool].KeyedObjectPool | An object pool interface that uses keys to uniquely identify specific instance types of pools. Such pools can hold multiple different types of pools. |
| [pool].KeyedPoolableObjectFactory | A structural interface used by key-based object pools to manage and instantiate objects. |
A Simple Pool
When building a pooled object component or subsystem, you need to implement one structural interface. The architecture of the pool is that the client uses a pool and the pool manages all of the details related to when to instantiate and destroy objects. However, the pool does not instantiate and destroy the individual object. A helper class will do that on behalf of the pool. In pool speak, this is known as an object pool factory . The object pool factory is a bit more complicated than the standard factories described in Chapter 3.
Listing 4.1 shows an implementation of the object pool factory.
| |
class SimpleFactory implements PoolableObjectFactory { public Object makeObject() { return new PooledObject(); } public void destroyObject(Object obj) { } public boolean validateObject(Object obj) { return true; } public void activateObject(Object obj) { } public void passivateObject(Object obj) { } } | |
In Listing 4.1, the class SimpleFactory implements the interface PoolableObject- Factory . In this sample implementation, the class SimpleFactory does nothing much other than instantiating the class PooledObject and returning a value of true for the method validateObject . In such simple implementations, it is better to extend the class BasePoolableObjectFactory since that class definition implements the essentials. If the class SimpleFactory subclasses the class BasePoolableObjectFactory , then SimpleFactory only needs to implement the method makeObject . To make use of a pooled object, a client needs to instantiate a pool and then pass the class SimpleFactory to it, as shown in Listing 4.2.
| |
GenericObjectPool pool = new GenericObjectPool( new SimpleFactory()); PooledObject obj = (PooledObject)pool.borrowObject(); obj.method(); pool.returnObject(obj);
| |
In Listing 4.2, the pool used is the class GenericObjectPool , which provides a basic pool implementation. For the class' GenericObjectPool constructor, an instance of the class SimpleFactory is passed in. Once the pool has been instantiated , it is possible to start using the pool's object instances. To get an object instance, the method pool.borrowObject is called. The method is called " borrow " because the pool decides if a new object instance needs to be allocated or if an existing object instance can be returned. Once the program is finished with the object instance, it needs to be returned to the pool using the method pool.returnObject . If the object instance is not returned to the pool, then the pool will constantly grow and objects will not be reused.
Details of the Pool Package
A pool in the default case is relatively simple object to use. However, you can use many options to manage the pool. The type of pool used and how it is implemented are other considerations. Regardless of the pool, however, you need a helper factory to manage individual object instances, as you saw in Listing 4.1.
In a pool, some objects are idle, whereas some are active. Idle objects are objects available in the pool and available for usage. Active objects are the objects that have been made available by the pool and are in usage. If you add the number of idle and active objects, you generate the total object instance count. The hard limit on the number of object instances is based on the total active count. Once the hard limit has been reached, a pool can take various actions, such as expanding the pool size or forcing the caller to wait for idle object instances.
When an object is borrowed from the pool, the state of the object instance changes from idle to active. If there are no idle objects, then the pool will create an object instance and mark it as active. A pool will always recycle objects from the object pool and activate the object before it is borrowed from the pool. When an object is being activated, the situation is like when the constructor of the object is called, except that the helper object activation method is called.
Every pool object factory implements either the interface PoolableObjectFactory or KeyedPoolableObjectFactory . The interface PoolableObjectFactory has the following methods :
-
Object makeObject() : Creates an object instance.
-
void destroyObject(Object obj) : Destroys the object. This is a bit of a strange concept because in Java there is no such thing as object destruction in memory terms. The purpose of this method is to release the resources managed by the object. Remember that the pooled object is an object that is expensive in resource terms to instantiate and release.
-
boolean validateObject(Object obj) : Checks the object for state integrality. This method is not called generally, only when the pool caller requests it.
-
void activateObject(Object obj) : Resets the object to an initialized state. It's usually called before the object's state changes from idle to active.
-
void passivateObject(Object obj) : Resets the object to an uninitialized state. It's usually called before the object's state changes from active to idle.
The methods for the interface KeyedPoolableObjectFactory are identical to those for PoolableObjectFactory , except that there is an additional parameter. For example, the interface PoolableObjectFactory has the method makeObject(), which on the interface KeyedPoolableObjectFactory would be makeObject( Object key) . The key could be any object instance; it is a reference marker that is not translated by the pools. However, each key must be unique. This means that each object instance has to be unique and not just contain unique data, since the pools will not process for uniqueness the data that the object holds.
The developer will interact with the interfaces ObjectPool and KeyedObjectPool when managing a pool of objects. As with the interfaces PoolableObjectFactory and KeyedPoolableObjectFactory , the difference between the interface ObjectPool and the interface KeyedObjectPool is that the interface KeyedObjectPool has an additional parameter key. The key is provided by the caller and is then passed onto the object factory helpers. The interfaces ObjectPool and KeyedObjectPool have the following methods: (note that the methods in square brackets are variations of the methods for the interface KeyedObjectPool ):
-
Object borrowObject() [Object borrowObject(Object key)] : This method retrieves an object instance from the pool. The object instance's state changes from idle to active. If the pool has reached a hard limit on the number of active object instances, there is no predefined result. The result depends entirely on the implementation of the pool.
-
void returnObject(Object obj) [void returnObject(Object key, Object obj)] : This returns the object instance back into the pool. The object instance's state changes from active to idle. If there are an excessive number of idle objects, then the extra ones are destroyed . The exact nature of how this method acts depends on the implementation of the pool.
-
void invalidateObject(Object obj) [void invalidateObject(Object key, Object obj)] : An object is returned to the pool and should be destroyed because the object has become invalid. This could be due to any reason, but the thinking is as follows : When an object is activated or set passivated, the object's state is reset. These operations tend not to be too expensive. However, when the object becomes invalid, the cost of resetting the object becomes too great, and it would be simpler to delete the object and instantiate a new one if necessary.
-
int getNumIdle() [int getNumIdle(Object key)] : This retrieves the number of idle objects.
-
int getNumActive() [int getNumActive(Object key)] : This retrieves the number of active objects.
-
void clear() : This releases all of the idle objects from the pool.
-
void close() : This closes and finalizes the pool and releases all resources associated with the pool.
-
void setFactory(PoolableObjectFactory factory) : This sets the factory that is used to manage individual object instances.
The details of the managing a pool may seem overwhelming; however, because of the nature of the library, it is essential that there be plenty of parameters you can tweak. Remember that we are talking about scalability, and often that is discovered only when we're testing the application. Being able to tweak the settings optimizes the performance of the application. When we use the pool, it is important that the object does need a pool. The key thing to remember is that the cost of object instantiation should be high.
Integrating the Pool Package
Although we're glad that the Pool package exists, the problem is that it introduces yet another factory. We introduced several factories in Chapter 3. The Pool package-based factory was not one of those factories. Ideally, the best solution would be to use the lang factory or the Discovery factory. Listing 4.3 shows how to wrap the lang factory in the Pool object factory.
| |
public class BasePooledFactory extends BasePoolableObjectFactory { protected Factory _factory; public BasePooledFactory( Factory factory) { _factory = factory; } public Object makeObject() throws Exception { return _factory.create(); } } | |
In Listing 4.3, the class BasePooledFactory delegates the makeObject method to the _factory.create method. This way, the strategy used in Chapter 3 has not been negated. However, the object created will not be subjected to any activation and deactivation method calls, which are part of the interface PoolableObjectFactory . This is OK if the object to be used is stateless.
If the object is not stateless, then there is a problem. Right now, the class BasePooledFactory knows nothing about the implementation of the class created by the generic Factory interface. However, the lang factory does not have any methods that relate to activate or deactivation. Therefore, the only solution to this problem is to add object-specific instructions. Doing so will preclude the need for using the interface Factory , as shown in Listing 4.4.
| |
public class BasePooledFactory extends BasePoolableObjectFactory { protected Factory _factory; public BasePooledFactory( Factory factory) { _factory = factory; } public Object makeObject() throws Exception { return _factory.create(); } public void activateObject( Object obj) throws Exception { MyClass cls = (MyClass)obj; // ... do something with the instance } } | |
In Listing 4.4, the interface instance Factory is used to instantiate the object. However, the method activateObject has the parameter variable obj typecast to the specific class MyClass . Contrast that to the method makeObject , which returns a generic object type. The result is that class BasePooledFactory , which was supposed to be generic, has a reference to a specific class, and that is not desirable.
The solution to the specific class reference problem is to look back at Listing 3.15 in Chapter 3. To recap, Listing 3.15 showed how to create some type of base interface to expose the method clone and extend the interface Cloneable . Listing 3.15 could be used as a basis for a more complex interface, as shown in Listing 4.5.
| |
public interface BaseObject extends Cloneable { public Object clone() throws CloneNotSupportedException; public void activateObject() throws Exception; public void destroyObject() throws Exception; public boolean validateObject(); public void passivateObject() throws Exception; } | |
The newly defined interface BaseObject adds the methods used to activate, deactivate, and destroy the object. Of course, the original method clone is still available. Knowing that this interface is the basis of all objects, you could substitute the reference to MyClass in Listing 4.4 with a reference to BaseObject . The actual code would appear similar to Listing 4.6.
| |
public void activateObject(Object obj) throws Exception { try { BaseInterface interf; interf = (BaseInterface)obj; interf.activateObject(); } catch( java.lang.ClassCastException ec) { ; } } | |
In Listing 4.6, the input variable obj is cast to the interface BaseInterface . Once the object has been cast, the method activateObject can be called. What is important to realize is that the entire code is wrapped in an exception block that catches the exception ClassCastException . The class ClassCatchException represents cast failure, which could occur when the variable obj is cast to the interface BaseInterface . However, no actions are taken if the cast fails. This is a good, logical solution because it allows the developer to have the option to implement the interface BaseInterface . BaseInterface must be implemented if the object is stateful, even if the object used in the pooled context is a legacy object.
Encapsulating the Pool
In Listing 4.2, the client used the pool directly and associated the object factory manually. This is another example of how the object factory is used as a hard reference, even though the rest of the code would use the interface. The object factory as shown in previous chapters could be converted into a soft reference, but there is a logic problem. The designer of the class used by the object factory knows what is expensive in resources terms of the class. Therefore, it's probably a bad idea to have the client programmer decide which pool to use and which parameters to set. It is not that the class designer should take away rights from the client programmer, but that the class designer should set meaningful defaults. This way, the client programmer does not have to look through the class sources to figure out what the class is trying to do. The simplest example of predefining what to do for the client programmer is shown in Listing 4.7.
| |
public class IntegrationExamplePool extends GenericObjectPool { public IntegrationExamplePool() { setFactory( new GenericPooledFactory( FactoryUtils.reflectionFactory( IntegrationExample.class))); } } | |
In Listing 4.7, the class IntegrationExamplePool subclasses the pool class Generic-ObjectPool . In the constructor of IntegrationExamplePool , the default object factory is set using the method call setFactory . The other class, GenericPooledFactory , is a class developed by the author of this book, which can be retrieved from the Web site www. devspace.com . Finally, the method call FactoryUtils.reflectionFactory is a method from the lang factory package.
Even though Listing 4.7 is compact, it accomplishes everything that is necessary in one step. The lang factory is used, which means the material discussed in previous chapters is not for naught, or at least it is not an either-solution situation. If, however, the lang factory is not to your liking, then you can use the pool factory as the base factory interface. The interface BaseInterface is used because the class IntegrationExample will implement the interface. The class GenericPooledFactory implements the interface PoolableObjectFactory and uses the lang factory internally to instantiate objects. In addition, the client programmer has only one hard reference to the class IntegrationExamplePool , which is responsible for maintaining all of the hard references of the specific implementations internally. Listing 4.8 shows an example of a client using the class.
| |
IntegrationExamplePool pool = new IntegrationExamplePool(); Object temp = pool.borrowObject(); InterfaceToBeShared obj = (InterfaceToBeShared)temp; obj.availability(); pool.returnObject(obj);
| |
Listing 4.8 looks very similar to Listing 4.2. The difference is that the hard references to specific implementations and object factories have been removed. The client only needs to know about the interface InterfaceToBeShared and the common pool class IntegrationExamplePool . This is a clean approach that does not violate any of the best practices we have learned thus far.
Encapsulating a Multiple Class Type Pool
Now that we have defined a strategy for defining a custom pool, we can use it to manage multiple class type pools, which are pools that can contain different class instance types. In Chapter 3, we introduced the idea of creating multiple objects using one factory class. The same sort of idea can be used to create multiple objects with a pool. Doing so is relatively simple; instead of subclassing the class GenericObjectPool , we subclass the class GenericKeyed- ObjectPool . The caller class would then define a number of static variables that can be used to instantiate the different types. Listing 4.9 shows a sample implementation of this class.
| |
public class MultiIntegrationExamplePool extends GenericKeyedObjectPool { public final static String OBJ_OBJECTTOBECREATED = ObjectToBeCreated.class.getName(); public final static String OBJ_ANOTHEROBJECTTOBECREATED = AnotherObjectToBeCreated.class.getName(); private KeyedGenericPooledFactory _helperFactory; public MultiIntegrationExamplePool() { _helperFactory = new KeyedGenericPooledFactory(); _helperFactory.setFactory( OBJ_OBJECTTOBECREATED, FactoryUtils.reflectionFactory( ObjectToBeCreated.class)); _helperFactory.setFactory( OBJ_ANOTHEROBJECTTOBECREATED, FactoryUtils.reflectionFactory( AnotherObjectToBeCreated.class)); setFactory( _helperFactory); } } | |
In Listing 4.9, the class MultiIntegrationExamplePool contains two static final strings that are used to describe two unique keys. The unique keys are used to identify the object type when you are borrowing or returning objects to the pool. In Listing 4.9, the class KeyedGenericPooledFactory is a custom-defined class part of the book's source code. The purpose of the class KeyedGenericPooledFactory is to associate a key to a specific factory interface instance. In this case, the class KeyedGenericPooledFactory is a data member, but it does not need to be. Listing 4.10 shows how to instantiate a specific object type.
| |
Object temp = pool.borrowObject( MultiIntegrationExamplePool.OBJ_OBJECTTOBECREATED);
| |
In Listing 4.10, the method borrowObject requires a key, which is the final string defined in Listing 4.9. The result from the method call is an object instance that is the class instance ObjectToBeCreated . The unique token does not need to be named something similar to the class name . The unique token could be MY_SUPER_DUPER_OBJECT . However, it is crucial that the object represent something that all developers understand.
The examples shown thus far use the lang factory package, but we could just as easily have used the Discovery factory package. We didn't because the details of the implementation of the Discovery package implementation are beyond the scope of this book.
Controlling the Characteristics of the Pool
In Listings 4.7 and 4.9, we used the generic implementations of the pool when subclassing to custom pools. We can control the generic pool by using the following attributes, which can be set using standard Java bean setters:
-
maxActive : This is an integer value that specifies the maximum number of active objects.
-
maxIdle : This is an integer value that specifics the maximum number of idle objects. If the idle count is exceeded, then those objects are destroyed.
-
maxWait : This value is used when the whenExhaustedAction flag is set to WHEN_ EXHAUSTED_BLOCK . If a client is blocked, then the client will wait the number of milliseconds as specified by the value. If a timeout occurs, the exception NoSuchElementException is thrown.
-
minEvictionIdleTimeMillis : This determines the amount of time an object can be idle before being destroyed. If an object has been idle for four hours, it has been sitting around too long without being used and hence is wasting resources.
-
testOnBorrow : This causes the interface method PoolableObjectFactory.validate to be called whenever an object is borrowed from the pool.
-
testOnReturn : This causes the interface method PoolableObjectFactory.validate to be called whenever an object is returned to the pool.
-
testWhileIdle : When the idle object inspector thread checks how idle an idle object has been, this flag will force the object inspector thread to validate the idle object. If the validation fails, then the object is automatically discarded.
-
timeBetweenEvictionRunsMillis : This determines the time that the idle object inspector thread sleeps before making another inspection run of all possible idle objects that can be removed. The time unit is milliseconds.
-
whenExhaustedAction : This is an enumeration-type value that specifies what occurs when the number of active instances exceeds the maxActive count. Setting this flag with the value WHEN_EXHAUSTED_FAIL indicates that an exception of type NoSuchElementException will be thrown. Setting the flag with the value WHEN_EXHAUSTED_GROW indicates that the method borrowObject can still be called. Using this value makes the value of the maxActive value irrelevant, since an object will be allocated anyway. Setting the flag with the value WHEN_EXHAUSTED_BLOCK indicates that the client will wait until an idle object becomes available.
Pool Monitoring
Using pools can make your application more responsive . However, setting some of the pool characteristics incorrectly can severely slow down your application because pools are system level-type classes. When you experiment with the various settings, funny things can happen. For example, in the default case of the GenericObjectPool , a too small active object pool size can cause the system to deadlock. The deadlock occurs because all of the active objects have been given away, no extra objects can be instantiated, and no thread is returning an active object back to the pool. Another situation could be that exceptions are thrown and the application reacts incorrectly and causes further problems.
The question then becomes how to know which objects should be part of a pool and which objects should not. The answer to this problem is based on monitoring the application using some kind of profiling tool. In this book, we've used Java Memory Profiler (JMP), a monitoring tool available by going to www.khelekore.org/jmp/ . The JMP tool is a shared library or Dynamic Link Library (DLL) that is placed in the operating system path . When the JVM calls the JMP profiler, direct access to the shared library or DLL is required. To activate the JMP profiler, the Java command line needs to include the command line option -Xrunjmp. The JVM uses the -Xrun command to execute a shared library or DLL named jmp (with a .dll or .so extension). When a Java application is executed and the processing time of the application exceeds five seconds, the windows in Figure 4.1 appear.
In Figure 4.1, the three windows that appear monitor all aspects of the application that is being executed. These windows will tell you which objects to manage. The problem in many Java applications is that the Memory Profiler graphic has a saw tooth pattern, as shown in Figure 4.2.
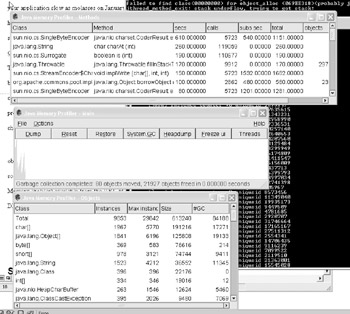
Figure 4.1: An example of JMP windows showing method calls, memory usage, and object usage.
The saw tooth pattern in Figure 4.2 indicates that the program allocates a number of objects and then the garbage collector comes along and frees a large group of objects at once. Using pools does not allow you to remove the entire saw tooth effect because Java is a garbage-collected environment, which means garbage will be generated. However, you do want to generate less garbage.
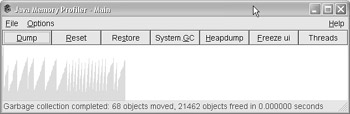
Figure 4.2: A saw tooth pattern that shows memory usage.
If a saw tooth pattern is generated, then the next step is to inspect which objects are being garbage-collected. Figure 4.3 shows a snapshot of the object usage profile for a particular application.
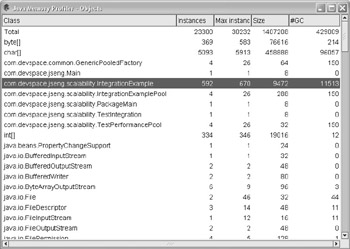
Figure 4.3: Object profiling.
In Figure 4.3, the highlighted object is the class IntegrationExample . Beside the class name are four columns :
-
Instances : This indicates the current number of active instances of the object.
-
Max Instances : This tells you the maximum number of active instances at any point in time.
-
Size : This is the size of the object.
-
#GC : This shows you the number of objects of this type that have been garbage- collected thus far.
The class IntegrationExample was highlighted because it shows an excellent example of an object that could be pooled. The first indicator of an object that should be pooled is the total number of times that the object has been garbage-collected. If the number is high, this indicates that the object has been used very often and then discarded. A pooled object would therefore not be garbage-collected as often and hence could improve performance. Also important to consider is the size of the object. Of course, the example class IntegrationExample is not that large; however, when the object is large, it might be useful to put the object into the pool. Another indicator of whether or not the object should pooled is if the number of instances that have been garbage-collected is much greater than the active count. This is called the factor of difference and is calculated by dividing the #GC by the Max Instances . For example, if the factor of difference is five or more, the object should be in the pool. In Figure 4.3, the factor is 17, indicating that objects are very commonly created and then deleted.
Once an object has been declared for pooling, you should set the parameters. The maximum count should be set to 1.5 times the Max Instances count for initial testing purposes. The maximum idle object count should be no larger than half the Max Instances count. However, this number depends on the cost of creating the objects and the fluctuation of the object count. The fluctuation of the object is not that simple to measure; you find it out by having experience testing the application.
You measure the fluctuation by noting the number of objects that change state as compared to those that remain in a specific state. A high fluctuation means that objects are retrieved very often and then quickly discarded. When the factor of difference is very high (typically greater than 20 or 30), the fluctuation is high and the minimum number of idle objects should be about the same as how many Max Instances you have. A lower fluctuation does not require as many idle objects. Of course, if the fluctuation is low, you don't need the pool since the low fluctuation could indicate that objects are referenced for a long time. The key to properly defining the idle count is to be able to keep a constant supply of objects available. If the supply of objects in a high fluctuating system is not available, then the system will be constantly garbage-collecting and creating new instances of objects. As a result, you will be managing the object without a pool. After all is done and said, however, there is no fixed rule about knowing how many idle objects to keep. It is something that is defined for each scenario.
Look back at Figure 4.3, which shows a different class and the statistics highlighted for the class IntegrationExamplePool . The highlighted class was generated artificially to show the situation where an object needs to be managed using pools. The sample numbers should be used to find potentially poolable objects in your sources.
EAN: 2147483647
Pages: 109