Backpropagation Learning
Backward error propagation, or simply backpropagation, is the most popular learning algorithm for connectionist learning. As the name implies, an error in the output node is corrected by back propagating this error by adjusting weights through the hidden layer and back to the input layer. While relatively simple, convergence can take some time depending upon the allowable error in the output.
Backpropagation Algorithm
The algorithm begins with the assignment of randomly generated weights for the multi-layer, feed-forward network. The following process is then repeated until the mean-squared error (MSE) of the output is sufficiently small:
-
Take a training example E with its associated correct response C.
-
Compute the forward propagation of E through the network (compute the weighted sums of the network, S i , and the activations, u i , for every cell ).
-
Starting at the outputs, make a backward pass through the output and intermediate cells , computing the error values (Equations 5.3 and 5.4):
(5.3) 
(5.4) 
(Note that m denotes all cells connected to the hidden node, w is the given weight vector and u is the activation).
-
Finally, the weights within the network are updated as follows (Equations 5.5 and 5.6):
(5.5) 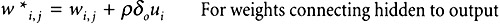
(5.6) 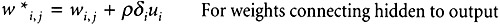
where represents the learning rate (or step size ). This small value limits the change that may occur during each step.
| Tip | The parameter can be tuned to determine how quickly the backpropagation algorithm converges toward a solution. It's best to start with a small value (0.1) to test and then slowly increment. |
The forward pass through the network computes the cell activations and an output. The backward pass computes the gradient (with respect to the given example). The weights are then updated so that the error is minimized for the given example. The learning rate minimizes the amount of change that may take place for the weights. While it may take longer for a smaller learning rate to converge, we minimize overshooting our target. If the learning rate is set too high, the network may never converge.
We'll see the actual code that's required to implement the functions above, listed with the numerical steps for the backpropagation algorithm as shown above.
Backpropagation Example
Let's now look at an example of backpropagation at work. Consider the network shown in Figure 5.7.
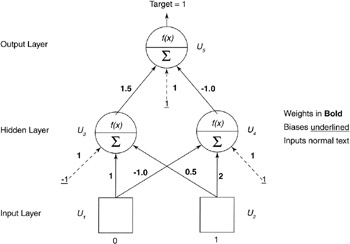
Figure 5.7: Numerical backpropagation example.
The Feed-forward Pass
First, we feed forward the inputs through the network. Let's look at the values for the hidden layer:
-
u 3 = f ( w 3,1 u 1 + w 3,2 u 2 + w b *bias )
-
u 3 = f (1*0 + 0.5*1 + 1*1) = f (1.5)
-
u 3 = 0.81757
-
u 4 = f ( w 4,1 u 1 + w 4,2 u 2 + w b *bias )
-
u 4 = f (-1*0 + 2*1 + 1*1) = f (3)
-
u 4 = 0.952574
Recall that f ( x ) is our activation function, the sigmoid function (Equation 5.7):
| (5.7) | |
Our inputs have now been propagated to the hidden layer; the final step is to feed the hidden layer values forward to the output layer to calculate the output of the network.
-
u 5 = f ( w 5,3 u 3 + w 5,4 u4 + w b *bias )
-
u 5 = f (1.5*0.81757+ -1.0*0.952574+ 1*1) = f (1.2195)
-
u 5 = 0.78139
Our target for the neural network was 1.0; the actual value computed by the network was 0.78139. This isn't too bad, but by applying the backpropagation algorithm to the network, we can reduce the error.
The mean squared error is typically used to quantify the error of the network. For a single node, this is defined as Equation 5.8:
| (5.8) | |
Therefore, our error is:
-
err = 0.5 * (1.0 - 0.78139) 2 = 0.023895
The Error Backward Propagation Pass
Now let's apply backpropagation, starting with determining the error of the output node and the hidden nodes. Using Equation 5.1, we calculate the output node error:
-
o = (1.0 - 0.78139) * 0.78139 * (1.0 - 0.78139)
-
o = 0.0373
Now we calculate the error for both hidden nodes. We use the derivative of our sigmoidal equation (Equation 5.5), which is shown as Equation 5.9.
| (5.9) | |
Using Equation 5.2, we now calculate the errors for the hidden nodes:
-
u4 = ( o * w 5,4 ) *u 4 * (1.0 - u 4 )
-
u4 = (0.0373 * -1.0) * 0.952574 * (1.0 - 0.952574)
-
u4 = -0.0016851
-
u3 = ( o * w 5,3 ) *u 3 * (1.0 - u 3 )
-
u3 = (0.0373 * 1.5) * 0.81757 * (1.0 - 0.81757)
-
u3 = 0.0083449
Adjusting the Connection Weights
Now that we have the error values for the output and hidden layers , we can use Equations 5.3 and 5.4 to adjust the weights. We'll use a learning rate ( ) of 0.5. First, we'll update the weights that connect our output layer to the hidden layer.
-
w* i,j = w i,j + o u i
-
w 5,4 = w 5,4 + ( * 0.0373 * u 4 )
-
w 5,4 = -1 + (0.5 * 0.0373 * 0.952574)
-
w 5,4 = -0.9822
-
w 5,3 = w5,3 + ( * 0.0373 * u 3 )
-
w 5,3 = 1.5 + (0.5 * 0.0373 * 0.81757)
-
w 5,3 = 1.51525
Now, let's update the output cell bias:
-
w 5,b = w 5,b + ( * 0.0373 * bias 5 )
-
w 5,b = 1 + (0.5 * 0.0373 * 1)
-
w 5,b = 1.01865
In the case of w 5,4 , the weight was decreased where for w 5,3 the weight was increased. Our bias was updated for greater excitation . Now we'll show the adjustment of the hidden weights (for the input to hidden cells).
-
w* i,j = w i,j + i u i
-
w 4,2 = w 4,2 + ( * -0.0016851 * u 2 )
-
w 4,2 = 2 + (0.5 * -0.0016851 * 1)
-
w 4,2 = 1.99916
-
w 4,1 = w 4,1 + ( * -0.0016851 * u 1 )
-
w 4,1 = -1 + (0.5 * -0.0016851 * 0)
-
w 4,1 = -1.0
-
w 3,2 = w 3,2 + ( * 0.0083449 * u 2 )
-
w 3,2 = 0.5 + (0.5 * 0.0083449 * 1)
-
w 3,2 = 0.50417
-
w 3,1 = w 3,1 + ( * 0.0083449 * u 1 )
-
w 3,1 = 1.0 + (0.5 * 0.0083449 * 0)
-
w 3,1 = 1.0
The final step is to update the cell biases:
-
w 4,b = w 4,b + ( * -0.0016851 * bias 4 )
-
w 4,b = 1.0 + (0.5 * -0.0016851 * 1)
-
w 4,b = 0.99915
-
w 3,b = w 3,b + ( * 0.0083449 * bias 3 )
-
w 3,b = 1.0 + (0.5 * 0.0083449 * 1)
-
w 3,b = 1.00417
That completes the updates of our weights for the current training example. To verify that the algorithm is genuinely reducing the error in the output, we'll run the feed-forward algorithm one more time.
-
u 3 = f ( w 3,1 u 1 + w 3,2 u 2 + w b *bias )
-
u 3 = f (1*0 + 0.50417*1 + 1.00417*1) = f (1.50834)
-
u 3 = 0.8188
-
u 4 = f ( w 4,1 u 1 + w 4,2 u 2 + w b *bias )
-
u 4 = f (-1*0 + 1.99916*1 + 0.99915*1) = f (2.99831)
-
u 4 = 0.952497
-
u 5 = f ( w 5,3 u 3 + w 5,4 u 4 + w b *bias )
-
u 5 = f (1.51525*0.8188+ -0.9822*0.952497 + 1.01865*1) = f (1.32379)
-
u 5 = 0.7898
-
err = 0.5 * (1.0 - 0.7898) 2 = 0.022
Recall that the initial error of this network was 0.023895. Our current error is 0.022, which means that this single iteration of the backpropagation algorithm reduced the mean squared error by 0.001895.
EAN: 2147483647
Pages: 175