Evolving Game AI Behaviors
The application that we'll use for backpropagation is the creation of neurocontrollers for game AI characters . A neurocontroller is the name commonly given to neural networks that are used in control applications. In this application, we'll use the neural network to select an action from an available set based upon the current environment perceived by the character. The usage of "character" and "agent" in the following discussion are synonymous.
The rationale for using neural networks as neurocontrollers is that we can't practically give a game AI character a set of behaviors that cover all possible combinations of perceived environments. Therefore, we train the neural network with a limited number of examples (desired behaviors for a given environment), and then let it generalize all of the other situations to provide proper responses. The ability to generalize and provide proper responses to unknown situations is the key strength of the neurocontroller design.
Another advantage to the neurocontroller approach is that the neurocontroller is not a rigid function map from environment to action. Slight changes in the environment may elicit different responses from the neurocontroller, which should provide a more believable behavior from the character. Standard decision trees or finite automata lead to predictable behaviors, which are not very gratifying in game-play.
As shown in Figure 5.8, the environment is the source of information for a character. Information is received from the environment and provided to the agent. This process of "seeing" the environment is called "perception." The neurocontroller provides the capability for "action-selection." Finally, the character manipulates the environment through "action." This alters the environment, so the character cycles back to perception to continue the sense- react cycle.
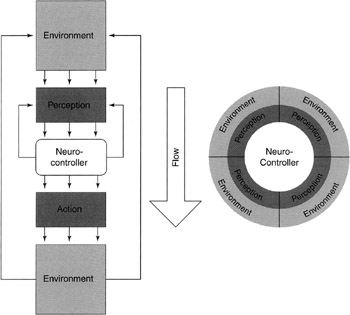
Figure 5.8: Example of a neurocontroller in an environment.
Neurocontroller Architecture
In the prior example, a neural network with a single output was discussed in detail. For the game AI agent, we'll look at another architecture called a "winner-take-all" network. Winner-take-all architectures are useful where inputs must be segmented into one of several classes (see Figure 5.9, page 97).
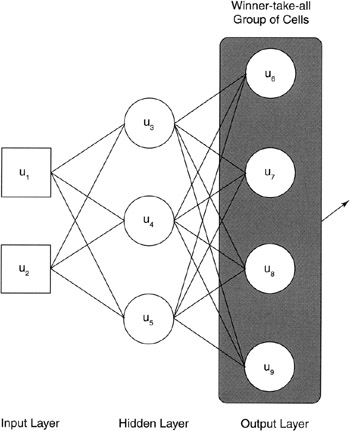
Figure 5.9: Winner-take-all group .
In the "winner-take-all" network, the output cell with the highest weighted sum is the "winner" of the group and is allowed to fire. In our application, each cell represents a distinct behavior that is available to the character within the game. Example behaviors include fire-weapon, runaway, wander, etc. The firing of a cell within the winner-take-all group causes the agent to perform the particular behavior. When the agent is again allowed to perceive the environment, the process is repeated.
Figure 5.10 (page 98) illustrates the network that was used to test the architecture and method for action-selection. The four inputs include the health of the character (0-poor to 2- healthy ), has- knife (1 if the character has a knife, 0 otherwise ), has-gun (1 if in possession, 0 otherwise), and enemy-present (number of enemies in field-of-view).
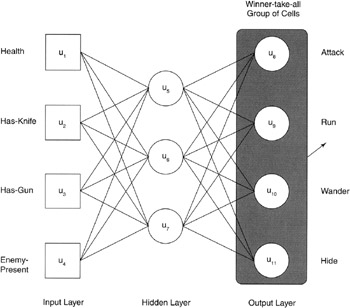
Figure 5.10: Game AI neurocontroller architecture for verification.
The outputs select the particular behavior that the character will take. Action attack causes the character to attack the peers in the field-of-view, run causes the character to flee its current position, wander represents random or non-random movement of the character within the environment, and hide causes the character to seek shelter. These behaviors are very high-level, and it's anticipated that the behavior subsystem will take the selected action and follow-through.
| Note | The architecture selected here (three hidden cells) was determined largely by trial-and-error. Three hidden cells could be trained for all presented examples with 100% accuracy. Decreasing the cells to two or one resulted in a network that did not successfully classify all examples. |
Training the Neurocontroller
The neurocontroller within the game environment is a static element of the character's AI. The following discusses online learning of the neurocontroller within the environment.
Training the neurocontroller consists of presenting training examples from a small set of desired behaviors, and then performing the backpropagation on the network given the desired result and the actual result. For example, if the character is in possession of a gun and is healthy and in the presence of a single enemy, the desired behavior may be to attack. However, if the character is healthy, in possession of a knife, but in the presence of two enemies, the correct behavior would be to hide.
Test Data Set
The test data set consists of a small number of desired perception-action scenarios. Since we want the neurocontroller to behave in a more life-like fashion, we will not train the neurocontroller for every case. Therefore, the network will generalize the inputs and provide an action that should be similar to other scenarios for which it was trained. The examples used to train the network are presented in Table 5.1.
| |
| Health | Has-Knife | Has-Gun | Enemies | Behavior |
|---|---|---|---|---|
| | ||||
| 2 |
|
|
| Wander |
| `2 |
|
| 1 | Wander |
| 2 |
| 1 | 1 | Attack |
| 2 |
| 1 | 2 | Attack |
| 2 | 1 |
| 2 | Hide |
| 2 | 1 |
| 1 | Attack |
| 1 |
|
|
| Wander |
| 1 |
|
| 1 | Hide |
| 1 |
| 1 | 1 | Attack |
| 1 |
| 1 | 2 | Hide |
| 1 | 1 |
| 2 | Hide |
| 1 | 1 |
| 1 | Hide |
|
|
|
|
| Wander |
|
|
|
| 1 | Hide |
|
|
| 1 | 1 | Hide |
|
|
| 1 | 2 | Run |
|
| 1 |
| 2 | Run |
|
| 1 |
| 1 | Hide |
| |
The data set in Table 5.1 was presented randomly to the network in backpropagation training. The mean-squared-error reduction is shown in Figure 5.11.
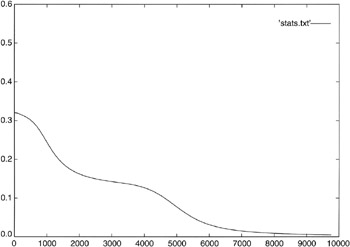
Figure 5.11: Sample run of the backpropagation algorithm on the neurocontroller.
In most cases, all examples shown in Table 5.1 are successfully trained. In some runs, up to two examples resulted in improper actions. Increasing the number of hidden cells resulted in perfect training. However, this would increase the computing resources needed to run the neurocontroller. Therefore, three hidden cells were chosen with multiple training cycles to ensure proper training. The neurocontroller was trained offline for as many runs as were necessary for perfect training on the given set.
To test the neurocontroller, new examples were presented to the network to identify how it would react to scenarios for which it had no specific knowledge. These tests give an understanding of how well the neurocontroller can generalize and respond with desirable actions for unseen examples.
If we present the neurocontroller with a scenario, in which it has full health, access to both weapons, and a single enemy present, or (2:1:1:1), the neurocontroller responds with an attack action. This is a reasonable response given the situation. Now consider a scenario where the character has full health, access to a knife, and three enemies present (2:1:0:3). The neurocontroller in this scenario responds with the hide action. This is another reasonable scenario. See Table 5.2 for other examples.
| |
| Health | Has-Knife | Has-Gun | Enemies | Behavior |
|---|---|---|---|---|
| | ||||
| Good (2) | Yes | Yes | 1 | Attack |
| OK (1) | Yes | Yes | 2 | Hide |
| Poor (0) | No | No |
| Wander |
| Poor (0) | Yes | Yes | 1 | Hide |
| Good (2) | No | Yes | 3 | Hide |
| Good (2) | Yes | No | 3 | Hide |
| Poor (0) | Yes | No | 3 | Run |
| |
From Table 5.2, we can see that the neurocontroller successfully generalizes from the existing training set to provide reasonable actions for given environments. While it wasn't trained for these examples directly, it's able to perform a desirable behavior in response to them.
| On the CD | The source code for the backpropagation algorithm can be found on the CD-ROM at ./software/ch5/backprop/. |
EAN: 2147483647
Pages: 175