Enter XHTML
XHTML 1 is, again, the rewrite of HTML as an XML application. The primary concepts in HTML 4—especially the separation of document structure from presentation and issues concerning accessibility and internationalization—remain intact in XHTML 1. What’s more, the three DTD offerings (Strict, Transitional, and Frameset), originally from HTML 4 and later refined by HTML 4.01, are essentially the same DTDs in XHTML 1.
Despite these similarities, there are quite a few differences of great importance from both theoretic and semantic standpoints.
XHTML in Theory
XML brings several important ideas and incentives to web designers and developers through XHTML:
Reintroduce structure back into the language Picking up on the SGML and XML idea that documents should be written in conformance with the rules set out within the languages, XHTML makes it clear to authors that structural and semantic rules should be adhered to and must be adhered to in order to create compliant pages.
Provide designers with incentives to validate documents Validation carries with it some controversy, but it’s a powerful learning tool that helps you find your mistakes, fix them, and in the process, understand the way a specific DTD works. Validation, therefore, is an encouraged practice.
Accommodating new devices Part of the drive to accommodate XML in the web development environment has to do with the interest of delivering web-based content to other devices such as PDAs, cell phones, pagers, set-top boxes, WebTV (now known as MSNTV), and even television.
With XHTML 1.1, the concept of separation of structure and presentation is complete. XHTML 1.1 has only one public DTD, based on the Strict DTD in XHTML 1. Web authors also have the option to work with modularization.
Modularization breaks HTML down into discrete modules such as text, images, tables, frames, forms, and so forth. The author can choose which modules they want to use and then write a DTD combining those modules into a unique application.
This is the first time you really see the extensibility introduced by XML at work: instead of having only the public DTDs to choose from, authors can create their own applications.
| Note | An overview of XHTML modularization can be found at www.w3.org/MarkUp/modularization . The actual XHTML 1.1 recommendation is at www.w3.org/TR/xhtml11/ . Modularization is a fascinating and rather dramatic change to the way we approach pages, but it is beyond the scope of this book to cover it in detail. |
Semantic Changes from HTML
In practice, XHTML works a bit differently from HTML. XHTML is much more rigorous than HTML and demands close attention to details.
-
It is recommended but not required that an XHTML 1 document be declared as an XML document using an XML declaration.
-
It is required that an XHTML 1 document contain a DOCTYPE that denotes that it is an XHTML 1 document and also denotes the DTD being used by that document.
-
An XHTML 1 document has a root element of html. The opening tag of the html element should contain the XML namespace xmlns and the appropriate value for the namespace.
-
The syntax and structure of the document must follow the syntactical rules of XHTML.
XML Prolog, DOCTYPE Declaration, and Namespace
An XHTML document may contain several structural elements to be considered correct.
The XML Prolog
The XML Prolog is a declaration that can appear above your DOCTYPE declaration. The prolog is recommended but not required. Part of the reason it is not required is that some browsers (including IE 4.5 for Mac, IE 6 for Windows, and Netscape 4 for Windows) will display XHTML pages inappropriately if it is used.
So, most XHTML 1 authors interested in the best interoperability leave it out. However, because the encoding information is important in many instances—particularly when working with international documents—if you don’t use the XML declaration, you are encouraged to be sure encoding is set on your server or in a meta tag. Here’s an example of the XML prolog, which states the XML version of the document as well as the document’s encoding:
<?xml version="1.0" encoding="UTF-8"?>
The DOCTYPE Declaration
There are only three DTDs available in XHTML 1: Strict, Transitional, and Frameset, all carrying over with some minor differences from HTML 4.01. The DOCTYPE declaration declares the language version, interpretation, and location of the related DTD.
The way a DOCTYPE declaration is written is important for the reasons described in this DOCTYPE Switching sidebar. The following shows the available DOCTYPE declarations for HTML 4.01, XHTML 1.0, and XHTML 1.1, as they should be written.
HTML 4.01 Strict
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
HTML 4.01 Transitional
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
HTML 4.01 Frameset
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd">
XHTML 1.0 Strict
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
XHTML 1.0 Transitional
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
XHTML 1.0 Frameset
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
XHTML 1.1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
In many recent browsers, an implementation for managing standard versus nonstandard markup has emerged. Browsers with this feature, referred to as DOCTYPE Switching, will behave in different ways depending upon the DTD that is declared in your document, or if in fact the DTD is declared at all.
This behavior involves switching modes to best represent standard versus nonstandard markup. The two modes are quirks mode, which behaves just as any legacy browser would, and strict rendering mode, which follows the standard.
Those pages containing older or transitional HTML DOCTYPEs or no DOCTYPE at all are displayed using quirks mode. Documents with correct Strict or XHTML DOCTYPEs use strict rendering mode.
This switching becomes more important as you delve into CSS, because certain rendering modes create different results. I’ll point these concerns out as you move through the CSS chapters in the next part of the book.
A switching table created by Eric A. Meyer (technical editor of this book) can be found at www.meyerweb.com/eric/dom/dtype/dtype-grid.html. Another table, by Matthias Gutfeldt, is available at http://gutfeldt.ch/matthias/articles/doctypeswitch/table.html. This table shows how various browsers will relate to given DOCTYPE declarations.
The XML Namespace for XHTML
An XML namespace is a collection of unique element and attribute names. In XHTML, the namespace points to the related document at the W3C. The namespace is placed in the root element of the document tree, html:
<html xmlns="http://www.w3.org/1999/xhtml">
XHTML Syntax
Once an XHTML document contains the necessary declarations and basic structural information, you can examine the syntax changes resulting from XML’s influences on web markup, including:
-
Heavy focus on logical markup
-
Case sensitivity
-
Well-formed syntax
-
Specific management of empty and non-empty elements
-
Quotation requirements
-
Escaping of script characters
-
Management of minimized attributes
Each of these changes brings a marked amount of rigor to your authoring practices. Whether you end up using HTML or XHTML to mark up the documents you’ll be styling with CSS, the knowledge of these practices will greatly influence your ability to write your style sheets with equal logic and organization.
Logical Markup
It can’t be expressed enough that anyone wishing to learn CSS must understand the value of logical markup. When you work with content, the proper use of headers, paragraphs, breaks, lists, and so on should follow a sensible tree.
If you’ve ever wondered why an h1 is bigger than an h6 instead of the other way around, consider that headers in a document are meant to be organized by level of topic importance, like in an outline.
Let’s say you’ve got three important places to go today: Bank, Post Office, Grocery Store. If you were creating a document tree out of those three topics, they would all be level 1 headers. The main activities you want to do at each stop would comprise your level 2 headers, and so on.
Paragraphs of content should be structured properly, too. Other items, such as lists, can easily organize information in a logical way. As you build your page, keep the tree concept in mind because you can work off of the elements in your tree when creating your style sheets—as you will see in many examples throughout the course of this book.
Using the Bank, Post Office, Grocery Store example, Listing 1.4 shows how this structure might pan out within a document.
Listing 1.4: Exploring the Logical Structure of Level 1 and 2 Headers
<h1>Bank</h1> <p>Today I need to go to the bank.</p> <h2>Cash Check</h2> <p>My first order of the day is to cash my check.</p> <h2>Transfer Funds</h2> <p>I also need to transfer funds from one account to another. Once I’m done with that, I can go to the post office.</p> <h1>Post Office</h1> <p>After the bank, I need to stop at the post office.</p> <h2>Mail Packages</h2> <p>I have three packages to mail.</p> <h2>Buy Stamps</h2> <p>I need to buy stamps, I’m always forgetting! Once done with the bank and post office, I’m off to the grocery store.</p> <h1>Grocery Store</h1> <p>I have a few things to get at the grocery store.</p> <h2> Salad Fixings</h2> <p>Since it’s summer, all I want to eat are lots of fresh veggies.</p> <h2>Wine</h2> <p>I’m having company Friday night and need a few bottles of a decent wine.</p>
Of course, you can go on to develop your markup to use additional headers. The important lesson is tapping into using headers the way they were intended. The problem prior to style sheets was that designers were limited to what the default display was of their header (unless they also used a font tag and attributes to modify it). With CSS, the logic can be restored to the page while the separate presentation rules can leave the customized look of these components in your hands.
Figure 1.10 shows this sample page, unstyled. In Figure 1.11, I added a few simple CSS styles for the headers.
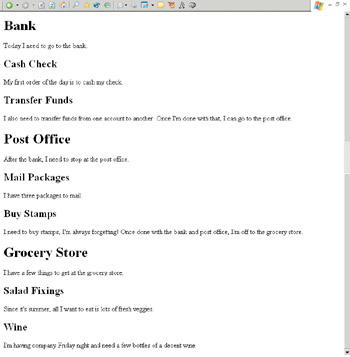
Figure 1.10: Studying logical structure, unstyled.
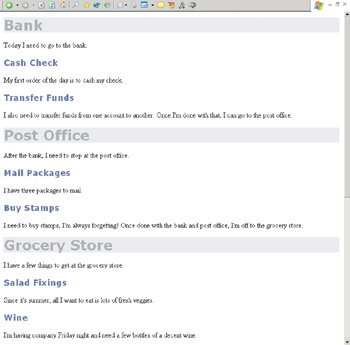
Figure 1.11: The same document, styled.
Case Sensitivity
HTML is not case sensitive. This means that HTML elements and attributes names can be in upper-, lower-, or mixed-case:
<body background="my.gif">
or
<BODY BACKGROUND="my.gif">
or even
<BoDy background="my.gif">
All of these examples mean the same thing in HTML.
On the other hand, XML is case sensitive. This means that XHTML is also case sensitive. In XHTML 1, all elements and attribute names must be written in lowercase:
<body background="my.gif">
| Note | Attribute values, such as “my.gif", can be in mixed case. This is especially important in instances where the files are on servers with case-sensitive file systems. |
Well-Formed Syntax
Many HTML browsers are quite forgiving of HTML errors and many HTML tools don’t conform to standards. As such, some web designers have either inadvertently created poorly formed markup or learned bad habits.
The following example will work in many browsers:
<b><i>Welcome to MySite.Com</b></i>
It will display as both bold and italic in a forgiving browser. But, if you take a pencil and draw an arc from the opening bold tag to its closing companion, and then from the opening italic tag to its closing companion, you’ll see that the lines of the arcs intersect. This demonstrates improper nesting of tags and is considered poorly formed.
| Note | In a conforming browser, assuming the content displayed at all, it would be italic but not boldface. |
In XHTML 1, such poorly formed markup is unacceptable because the potential problems resulting from nonstandard methods are unacceptable. The concept of well-formedness must be adhered to in that every element must nest appropriately. The XHTML 1 equivalent of the prior sample is as follows:
<b><i>Welcome to MySite.Com</i></b>
Draw the arcs now, and you’ll see that they do not intersect. These tags are placed in the proper sequence and are considered to be well-formed.
Management of Non-Empty and Empty Elements
A non-empty element is one that contains an element and some content:
<p>This is the content within a non-empty element.</p>
An empty element is one that has no content, just the element and any allowed attributes, such as hr, br, and img. XML says that empty and non-empty elements must be properly terminated. In HTML, non-empty elements often have optional closing tags.
In HTML, I could write the paragraph above as follows:
<p>This is the content within a non-empty element.
This is considered correct. XHTML 1 demands that non-empty elements be properly terminated with a closing tag, as in the first example.
Another example is the list item, li, element.
In HTML, you could have a list like this:
<ul> <li>Bank <li>Post Office <li>Grocery Store </ul>
or like this:
<ul> <li>Bank</li> <li>Post Office</li> <li>Grocery Store</li> </ul>
In XHTML 1, only the latter method is allowed.
Empty elements work a bit differently. They are terminated in XML with what is known as a trailing slash:
<br>
becomes:
<br/>
Due to problems some browsers accustomed to interpreting HTML have with this method, a workaround was introduced, adding a space before the slash: br /. You should always use the space prior to the trailing slash in XHTML documents.
Here’s an XHTML example of the image element, which is an empty element:
<img src="/books/1/266/1/html/2/my.gif" height="55" width="25" border="0" alt="picture of me" />
Other empty elements of note are hr, meta, and link.
Quotation Rules
Quotation marks in HTML are arbitrary in that you can use or not use them around attribute values without running into too much trouble. There’s no rule that says that leaving values unquoted is illegal. The following is perfectly acceptable in HTML:
<table border=0 width="90%" cellpadding=10 cellspacing="10">
Despite the fact that some attribute values are quoted and others are not, browsers will render this markup just fine. However, if you want to conform to XHTML 1, you’ll have to quote all of your attribute values:
<table border="0" width="90%" cellpadding="10" cellspacing="10">
| Tip | You can never go wrong when you quote your attribute values in HTML, so get in the practice of always quoting values! |
Other Markup and Code Concerns in XHTML
There are two other important concerns of which to be aware when working with XHTML:
Escaping certain characters in any inline script Let’s say you have a JavaScript within your document. Any ampersand (&) must be escaped properly (that is, coded as an entity, not input using the keyboard symbol) as & for that document to be valid.
No attribute minimization is allowed Attribute minimization is a phenomenon that occurs in HTML, where an attribute is minimized to only the attribute name. An example of this is the nowrap attribute. In HTML, the attribute name can stand alone, with no value. However, in XHTML, minimization is not allowed—the attribute name is its value. Therefore, to be valid in XHTML, the HTML nowrap attribute must become nowrap="nowrap".
As you can see, none of these changes are monumental. A bit different, yes, but if you begin to use XHTML, you’ll find that your markup is a lot more consistent. That consistency is part of what makes XHTML so attractive—it provides a strong foundation upon which to build future constructs as well as to help you and your team members manage documents within a site more efficiently.
EAN: 2147483647
Pages: 86