Deploying the Application
|
We will only discuss installation into small, departmental-scale servers here, but WebSphere is fully capable of scaling to a large-scale enterprise environment; see Chapter 11 and 12 for more details.
| Important | If you have the samples installed that ship with the default installation of WebSphere Application Server, then you will find you already have a PlantsByWebSphere application installed. The application we are developing in this book is somewhat different, so you will need to stop and then uninstall the full blown example application before you can deploy our new created version. Refer to Chapter 14 for more instructions on this process. |
The installation of applications into WebSphere version 5.0 is accomplished via a thin-client web application known at the Administration Console. The administration console is simply a web application that is provided with WebSphere 5.0. This allows for consistent administrative access to your applications from any network-connected machine, there's no client software (other than a browser) required.
It is possible to run the admin console in the Studio unit test environment; ensure that the administration console checkbox is selected in the server configuration editor, and then use the Run Administrative Console menu item from the context menu in the Servers view. However, more typically the unit test environment is configured via the Studio editors, and the admin console is only used to configure a standalone WebSphere instance. We'll describe the installation of the Plants-By-WebSphere application using the admin console now, and we'll use the opportunity to explain how to create a DB2 data source at the same time.
You can start the console simply by opening a browser to the remote server's URL; by default the admin console is configured to use a port of 9090, in which case the URL will be of the form http://your_host_name:9090/admin/. When you start the admin console, you are first prompted for a user ID – note that the ID is only used to track changes made to the configuration; it is not secure. You are then taken to the admin console's workspace home page:
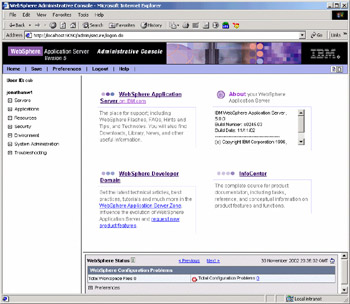
The home page consists of four main components:
-
The items on the left of the screen show the actions you take, grouped by category.
-
The central area of the screen is where the bulk of the data entry will occur. We'll walk through these screens below.
-
The WebSphere Status area in the bottom right of the screen shows the health of the server; any problems detected will be displayed here.
-
Finally, the menu bar across the top. Any changes you make will not be applied until you select Save from the menu bar, so it's important to remember this task.
Defining a New Data Source
| Important | Again, if you had the default PlantsByWebSphere application installed then you will already have a data source configured. However, because we wish to use an XA-compliant data source, you should first delete the pre-configured data source and follow the steps outlined here to create a new one. |
The first action to complete is the creation of the CloudScape data source. In order to support more advanced work in later chapters, we'll describe the creation of an XA-compliant CloudScape data source. Data sources are resources, so expand the Resources node on the left, and select Manage JDBC Providers and the New button on that page:
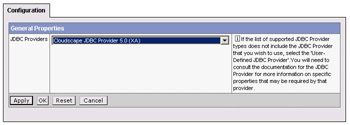
In the drop-down list, select the JDBC provider type you desire; we want CloudScape JDBC Provider 5.0 (XA). Click the OK button to continue, and you can complete the definition of the JDBC provider. For most cases, the defaults here are correct, and you can just select OK again:
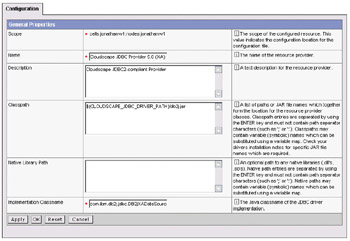
You've now defined the JDBC provider, and it (along with all other defined JDBC providers) will appear in the list shown below:
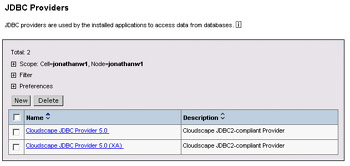
To create the data source, click on the hyperlink name of the new provider. This will take you back to a screen similar to that shown when creating the provider, but with additional options at the bottom. Scroll down, and you'll see a list including "data sources". Select that, and click New on the next screen, and you can configure the new data source as shown below:
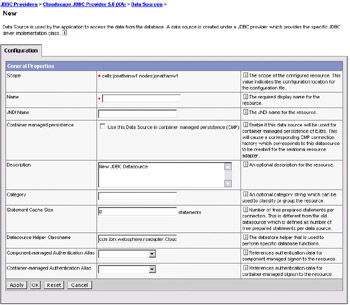
The settings here are very similar to those described previously in the Studio case:
-
The name is simply used when displaying the data source.
-
The JNDI name is critical; this is used when installing the application. We will use jdbc/PlantsByWebSphereDataSource.
-
The Use data source in container managed persistence checkbox should be selected, to ensure that a CMP connector factory that corresponds to this data source is created for the relational resource adapter.
-
The default data source helper class name should be correct; com.ibm.websphere.rsadapter.CloudscapeDataStoreHelper.
Click OK to save this data.
The next screen will display the data sources defined in the current provider; the newly created one should be in that list. We now need to configure some properties for the data source, so click the hypertext link that is its name.
As before, this will take you to a screen similar to that used to initially define the data source, but with additional options at the bottom of the screen. Scroll to the bottom, select the option Custom Properties, and you'll see the following screen:
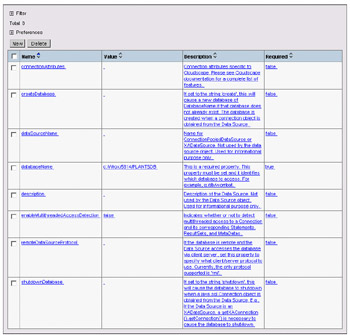
Each of the property names and values can be edited by clicking on them. The primary setting we need to change here is the database name, as we did before in Studio, to point to our PLANTSDB location. When complete, click the Save item in the menu bar; after prompting, the new data source will be saved for you as part of the server configuration. Although the administration console user interface is very different from that of the Studio editors, the result is identical; the changes you have made are persisted in a set of XML files that are saved on the server.
Install the Application
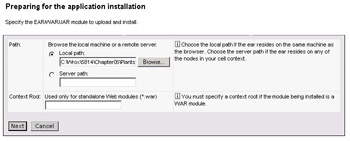
We next need to install the application. Expand the Applications node in the main tree view, and select Install New Application. You will first be prompted for the name of the EAR file to install. This file can be anywhere on your local file system, or it may be located on the server you are interacting with. In our case, we'll assume the file is available locally (this should be the EAR file we exported from Studio earlier in the chapter):
The next page allows us to indicate if default binding information should be generated automatically:
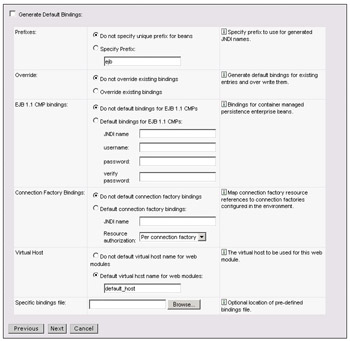
This automatic generation will consist of identifying all the unmapped references (such as ejb-refs) in the EAR, and then attempting to resolve them with resources that are defined in the EAR. In order to walk through the details, we'll leave the checkbox de-selected. This also means we do not need to select any of the subsequent fields, which are used to control the defaults when automatic binding is used. The rules used for the defaults are:
-
EJB JNDI names are generated of the form prefix/ejb-name. The default prefix is ejb, but can be overridden. The ejb-name is as specified in the deployment descriptor's <ejb-name> tag.
-
EJB references are bound as follows: If an <ejb-link> is found it will be honored. Otherwise, if a unique bean is found with a matching home (or local home) interface as the referenced bean, the reference will be resolved automatically.
-
Resource reference bindings are derived from the <res-ref-name> tag. Note that this assumes that the java:comp/env name is the same as the resource's global JNDI name.
-
Connection factory bindings (for EJB 2.0 JARs) are generated based on the JNDI name and authorization information provided. This results in the default connection factory being set for each EJB 2.0 JAR file in the application being installed. No bean-level connection factory bindings will be generated.
-
Data source bindings (for EJB 1.1 JARs) are generated based on the JNDI name, and data source username password options. This results in the default data source being set for each EJB JAR. No bean-level data source bindings are generated.
-
Message-driven bean (MDB) listener ports are derived from the MDBs by the <ejb-name> tag with the string Port appended.
-
For WAR files, the virtual host will be set as default_host unless otherwise specified.
The default binding action will suffice for most applications, but is not suitable if:
-
You want to explicitly control the global JNDI name(s) of one or more EJB files.
-
You need finer-grained control of data source bindings for CMPs. That is, you have multiple data sources and need more than one global data source.
-
You must map resource references to global resource JNDI names that are different from the java:comp/env name.
Hitting the Next button on this page will start the series of pages known as the Application Installation wizard.
| Important | Note that some of the pages are added dynamically, and depending on the choices you make the page numbers may not always be the same. You can navigate to any page of the wizard directly, by using the hypertext links for each page. Any data that is not completed when you finish the wizard will have defaults provided: |
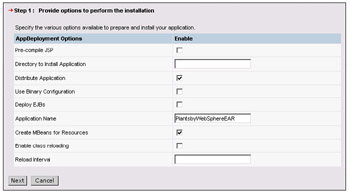
The first page allows you to provide additional options regarding the installation process itself:
-
Pre-compile JSP files if you are deploying an application to a server that will require a quick response the first time a page is hit; but this action will also take some time to complete during the installation. If you are just debugging or testing an application, you may wish not to pre-compile your JSP files.
-
The directory to install the application is the resultant directory for your application; this can be left blank in most cases and the default location of installedApps will be used.
-
The ability to distribute your application refers to the installation of your application into a multi-server networked environment; if you select this, the application will be distributed to all node servers.
-
The binary configuration option allows you to select if a previous set of configuration data saved in the module (such as the data entered in Studio) should be used. If it is not used, then defaults will be provided in most cases.
-
Deploy EJBs allows you to indicate if the EJB deployment code generation action should be run on the server prior to installation. You can deselect this if the EJB deployment code was previously generated (either in Studio, or by using the "EJBDeploy" tool that is shipped with WebSphere). For now, select the button to re-deploy the archive.
-
The application name is just used to identify the application later; the name can be anything.
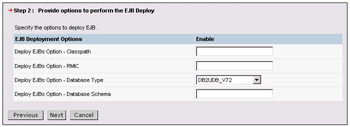
Step 2 allows you to enter data required for the EJB deployment code generation:
-
The first two fields allow you to define the classpath and any additional RMIC options required to complete the deploy action.
-
The database options (type, schema, and name) are only applicable for CMP entity beans, if you have not created a schema map in the JAR. In that case, the settings entered here will be used to create a schema map "top-down" (based on the bean definition) using the database details provided.
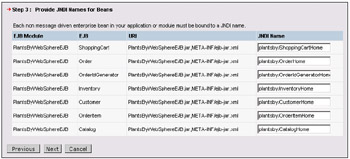
We now need to define the JNDI names for each EJB in the application. The JNDI names are used within your application to look up the various home beans from the initial context factory, so it's important to ensure the data entered here is consistent with your application usage:
The next action is to define the default data source information for the application, and the JNDI name of the data source to use for the archive. This is the data source that will be used for all CMP beans that do not override the setting on the next page.
| Important | There is a special rule that affects the JNDI name of data sources used by CMP beans. Additional infrastructure is required for a data source to be used by CMP beans, and this modified data source has a slightly different JNDI name; it is given a prefix of eis/ and a suffix of _CMP. For Plants-By-WebSphere, we defined the data source as jdbc/PlantsByWebSphereDataSource, but references to it need to use eis/jdbc/PlantsByWebSphereDataSource_CMP. |
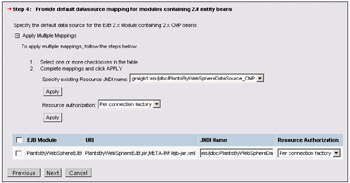
We next have the ability to override the module default for the data source to use, on a bean-by-bean basis. As before, the JNDI name is used within your application to locate the data source:

The resource authorization can be per-container or per-connection factory. Container managed authentication is used when you want to control access to a resource, but not by individual ID. In this case, you use the same ID for all access to the resource, and the ID and password declared in the bindings is used. Connection factory resource authentication means that each individual must authenticate themselves to the resource. This must be done by the client code that gets the connection from the factory.
We now move on o completing the EJB references. As described above in the Studio-based support, the references are defined by the bean provider, but the JNDI name of the bean that resolves each reference must be completed. For example, the Catalog bean has an ejb-ref to ejb/InventoryHome, but we now need to bind that reference to the same JNDI name set on Step 3, which was plantsby/InventoryHome in this case:

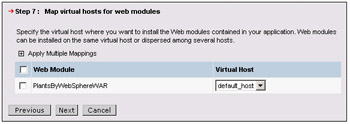
The next page allows you to map virtual hosts for the web application. Virtual hosts allow you to emulate multiple hosts from a single server. We do not need this capability in the Plants-By-WebSphere application:
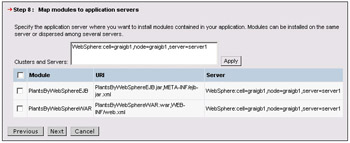
Step 8 in the wizard allows the application to be mapped to multiple servers. This capability is required when you are administering a cluster of servers, and is not required if we are just installing the application onto a single server:
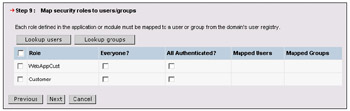
We next need to map any security roles defined in the application to users. As we are not enabling security in the Plants-By-WebSphere application, we can leave these selections blank:
The final data collection page in the wizard verifies the state of all unprotected methods in the application; you can assign a required security role to any such methods, or leave them unprotected:

You can now select the final (summary) page in the wizard, and after verifying the data shown click Finish to install the application. The server will process the application for a moment or two, and your application will be installed and available from the server. Don't forget to select the Save item on the menu, to save the configuration.
| Note | If your application contained any web services then there would be a couple of additional steps to this wizard – see Chapter 8 for more details. |
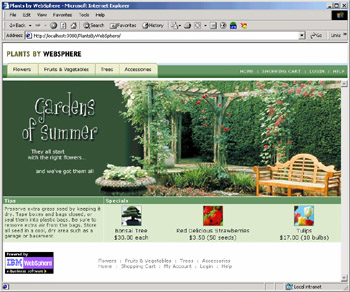
The installed application can now be accessed from any browser. The URL will be constructed as http://you_host_name:port/contextroot. By default, the port is 9080, and the context root we assigned for the application was PlantsByWebSphere. These combine to form a URL of http://you_host_name:9080/PlantsByWebSphere, which will result in a page like this:
|
EAN: N/A
Pages: 135
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- Distributed Data Warehouse for Geo-spatial Services
- Data Mining for Business Process Reengineering
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Development of Interactive Web Sites to Enhance Police/Community Relations
- Chapter VIII Personalization Systems and Their Deployment as Web Site Interface Design Decisions
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XII Web Design and E-Commerce
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability