URL Syntax
2.2 URL Syntax
URLs provide a means of locating any resource on the Internet, but these resources can be accessed by different schemes (e.g., HTTP, FTP, SMTP), and URL syntax varies from scheme to scheme.
Does this mean that each different URL scheme has a radically different syntax? In practice, no. Most URLs adhere to a general URL syntax, and there is significant overlap in the style and syntax between different URL schemes.
Most URL schemes base their URL syntax on this nine-part general format:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag> Almost no URLs contain all these components . The three most important parts of a URL are the scheme , the host , and the path . Table 2-1 summarizes the various components.
Table 2-1. General URL components | ||
| Component | Description | Default value |
| scheme | Which protocol to use when accessing a server to get a resource. | None |
| user | The username some schemes require to access a resource. | anonymous |
| password | The password that may be included after the username, separated by a colon (:). | <Email address> |
| host | The hostname or dotted IP address of the server hosting the resource. | None |
| port | The port number on which the server hosting the resource is listening. Many schemes have default port numbers (the default port number for HTTP is 80). | Scheme-specific |
| path | The local name for the resource on the server, separated from the previous URL components by a slash (/). The syntax of the path component is server- and scheme-specific. (We will see later in this chapter that a URL's path can be divided into segments, and each segment can have its own components specific to that segment.) | None |
| params | Used by some schemes to specify input parameters. Params are name/value pairs. A URL can contain multiple params fields, separated from themselves and the rest of the path by semicolons (;). | None |
| query | Used by some schemes to pass parameters to active applications (such as databases, bulletin boards , search engines, and other Internet gateways). There is no common format for the contents of the query component. It is separated from the rest of the URL by the "?" character. | None |
| frag | A name for a piece or part of the resource. The frag field is not passed to the server when referencing the object; it is used internally by the client. It is separated from the rest of the URL by the "#" character. | None |
For example, consider the URL http://www.joes-hardware.com:80/index.html . The scheme is "http", the host is "www.joes-hardware.com", the port is "80", and the path is "/index.html".
2.2.1 Schemes: What Protocol to Use
The scheme is really the main identifier of how to access a given resource; it tells the application interpreting the URL what protocol it needs to speak. In our simple HTTP URL, the scheme is simply "http".
The scheme component must start with an alphabetic character, and it is separated from the rest of the URL by the first ":" character. Scheme names are case-insensitive, so the URLs "http://www.joes-hardware.com" and "HTTP://www.joes-hardware.com" are equivalent.
2.2.2 Hosts and Ports
To find a resource on the Internet, an application needs to know what machine is hosting the resource and where on that machine it can find the server that has access to the desired resource. The host and port components of the URL provide these two pieces of information.
The host component identifies the host machine on the Internet that has access to the resource. The name can be provided as a hostname, as above ("www.joes-hardware.com") or as an IP address. For example, the following two URLs point to the same resourcethe first refers to the server by its hostname and the second by its IP address:
http://www.joes-hardware.com:80/index.html
http://161.58.228.45:80/index.html
The port component identifies the network port on which the server is listening. For HTTP, which uses the underlying TCP protocol, the default port is 80.
2.2.3 Usernames and Passwords
More interesting components are the user and password components. Many servers require a username and password before you can access data through them. FTP servers are a common example of this. Here are a few examples:
ftp://ftp.prep.ai.mit.edu/pub/gnu
ftp://anonymous@ftp.prep.ai.mit.edu/pub/gnu
ftp://anonymous:my_passwd@ftp.prep.ai.mit.edu/pub/gnu
http://joe:joespasswd@www.joes-hardware.com/sales_info.txt
The first example has no user or password component, just our standard scheme, host, and path. If an application is using a URL scheme that requires a username and password, such as FTP, it generally will insert a default username and password if they aren't supplied. For example, if you hand your browser an FTP URL without specifying a username and password, it will insert "anonymous" for your username and send a default password (Internet Explorer sends "IEUser", while Netscape Navigator sends "mozilla").
The second example shows a username being specified as "anonymous". This username, combined with the host component, looks just like an email address. The "@" character separates the user and password components from the rest of the URL.
In the third example, both a username ("anonymous") and password ("my_passwd") are specified, separated by the ":" character.
2.2.4 Paths
The path component of the URL specifies where on the server machine the resource lives. The path often resembles a hierarchical filesystem path. For example:
http://www.joes-hardware.com:80/seasonal/index-fall.html
The path in this URL is "/seasonal/index-fall.html", which resembles a filesystem path on a Unix filesystem. The path is the information that the server needs to locate the resource. [2] The path component for HTTP URLs can be divided into path segments separated by "/" characters (again, as in a file path on a Unix filesystem). Each path segment can have its own params component.
[2] This is a bit of a simplification. In Section 18.2 , we will see that the path is not always enough information to locate a resource. Sometimes a server needs additional information.
2.2.5 Parameters
For many schemes, a simple host and path to the object just aren't enough. Aside from what port the server is listening to and even whether or not you have access to the resource with a username and password, many protocols require more information to work.
Applications interpreting URLs need these protocol parameters to access the resource. Otherwise, the server on the other side might not service the request or, worse yet, might service it wrong. For example, take a protocol like FTP, which has two modes of transfer, binary and text. You wouldn't want your binary image transferred in text mode, because the binary image could be scrambled.
To give applications the input parameters they need in order to talk to the server correctly, URLs have a params component. This component is just a list of name/value pairs in the URL, separated from the rest of the URL (and from each other) by ";" characters. They provide applications with any additional information that they need to access the resource. For example:
ftp://prep.ai.mit.edu/pub/gnu;type=d
In this example, there is one param, type=d , where the name of the param is "type" and its value is "d".
As we mentioned earlier, the path component for HTTP URLs can be broken into path segments. Each segment can have its own params. For example:
http://www.joes-hardware.com/hammers;sale=false/index.html;graphics=true
In this example there are two path segments, hammers and index.html . The hammers path segment has the param sale , and its value is false . The index.html segment has the param graphics , and its value is true .
2.2.6 Query Strings
Some resources, such as database services, can be asked questions or queries to narrow down the type of resource being requested .
Let's say Joe's Hardware store maintains a list of unsold inventory in a database and allows the inventory to be queried, to see whether products are in stock. The following URL might be used to query a web database gateway to see if item number 12731 is available:
http://www.joes-hardware.com/inventory-check.cgi?item=12731
For the most part, this resembles the other URLs we have looked at. What is new is everything to the right of the question mark ( ? ). This is called the query component. The query component of the URL is passed along to a gateway resource, with the path component of the URL identifying the gateway resource. Basically, gateways can be thought of as access points to other applications (we discuss gateways in detail in Chapter 8 ).
Figure 2-2 shows an example of a query component being passed to a server that is acting as a gateway to Joe's Hardware's inventory-checking application. The query is checking whether a particular item, 12731 , is in inventory in size large and color blue .
Figure 2-2. The URL query component is sent along to the gateway application
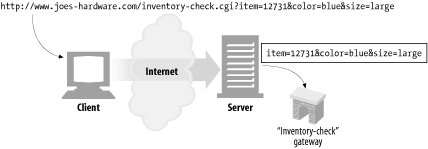
There is no requirement for the format of the query component, except that some characters are illegal, as we'll see later in this chapter. By convention, many gateways expect the query string to be formatted as a series of "name=value" pairs, separated by "&" characters:
http://www.joes-hardware.com/inventory-check.cgi?item=12731&color=blue
In this example, there are two name/value pairs in the query component: item=12731 and color=blue .
2.2.7 Fragments
Some resource types, such as HTML, can be divided further than just the resource level. For example, for a single, large text document with sections in it, the URL for the resource would point to the entire text document, but ideally you could specify the sections within the resource.
To allow referencing of parts or fragments of a resource, URLs support a frag component to identify pieces within a resource. For example, a URL could point to a particular image or section within an HTML document.
A fragment dangles off the right-hand side of a URL, preceded by a # character. For example:
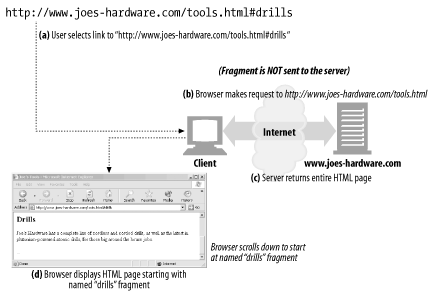
http://www.joes-hardware.com/tools.html#drills
In this example, the fragment drills references a portion of the /tools.html web page located on the Joe's Hardware web server. The portion is named "drills".
Because HTTP servers generally deal only with entire objects, [3] not with fragments of objects, clients don't pass fragments along to servers (see Figure 2-3 ). After your browser gets the entire resource from the server, it then uses the fragment to display the part of the resource in which you are interested.
[3] In Section 15.9 , we will see that HTTP agents may request byte ranges of objects. However, in the context of URL fragments, the server sends the entire object and the agent applies the fragment identifier to the resource.
Figure 2-3. The URL fragment is used only by the client, because the server deals with entire objects
EAN: 2147483647
Pages: 294