| Serviceguard is a set of software components designed to ensure that workloads are highly available. Because Serviceguard is software based, an initial assumption could be that installation and configuration of the Serviceguard software results in a highly available platform for hosting applications. However, that is not the case. In order to achieve a highly available foundation for running workloads, you must carefully plan and implement both the hardware and the software. Serviceguard Software Components Figure 16-1 shows the primary Serviceguard components. Immediately below the workload are the four major components in the Serviceguard application, the package manager, cluster manager, network manager, and object manager. Below the Serviceguard components in the diagram are the volume manager and operating system. These components are the same as the standard HP-UX and Linux volume managers and operating systems. The Serviceguard components are discussed in more detail in the following sections. Figure 16-1. Serviceguard Components 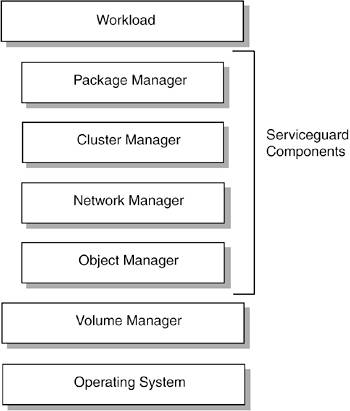
Package Manager The first Serviceguard component is the package manager, which is responsible for deciding where a package should run and executing the control scripts of packages. There are two types of package managers. One of the package managers in each cluster takes on the role of package coordinator, which decides where each package should be running. All package managers, including the package coordinator, perform the following functions: Take responsibility for starting and stopping packages that are supposed to be running on the local node. Monitor the services, resources, and subnets required for normal running of the package.
Workload failures in a cluster can usually be classified in one of two categories. The first is when a node running the workload becomes unreachable on the network and does not respond to heartbeat messages. As discussed in the next section, the cluster manager is responsible for detecting this failure condition and migrating packages accordingly. The second category of workload failures happens when a node is running normally and responding to heartbeat messages, but the application is experiencing a problem. In this situation, the package manager is responsible for detecting the failure. The package manager monitors several aspects of the workload to detect a workload failure. These include: Services: application processes are monitored as services. The package manager starts these services when the package is started and then monitors whether these processes are running. If a service process stops running, the package manager attempts to restart it based on the package configuration. If that fails, it stops the package and fails it over to another node. Subnet: the package manager monitors the availability of the subnets required by the package. If there is a failure and a standby network interface is available, the package manager instructs the network manager to switch over to the standby interface. If no standby is available, the package will fail over to another node. EMS Resources: EMS resource monitors can be created to monitor any attribute relevant to the application's status. The package manager can then be configured to monitor those EMS resources. If a resource exceeds the specified threshold, the package manager fails the package over to another node in the cluster.
Cluster Manager The next Serviceguard component is the cluster manager, which is responsible for initializing the cluster. It also monitors the health of the cluster and decides when a failure should occur. When a node leaves or joins the cluster, the cluster manager controls the reformation of the cluster. The cluster manager monitors the health of cluster nodes by sending heartbeat messages to all nodes in the cluster at every heartbeat interval. The interval is configurable. Setting this value lower will cause failovers to happen more quickly but may result in false failovers due to network congestion or intermittent network failures. Network Manager The third component of Serviceguard is the network manager that is responsible for ensuring the networking infrastructure for the cluster remains available, even in the event of a network card, network cable, or network switch failure. To accomplish this task, the network manager migrates a package's IP address along with the package to keep the address of the package constant, regardless of where the package is running. In addition, the network manager can enable a standby network adapter should an active network adapter experience a failure. Object Manager Finally, the Object Manager is responsible for responding to Serviceguard Manager client requests for information about the cluster. When a user starts Serviceguard Manager and specifies a cluster node to connect to, the object manager on the target node services the requests. If the object manager is not running, the connection fails. Serviceguard Hardware Planning The first step for configuring a Serviceguard cluster is planning how the cluster will be implemented. The hardware configuration of the cluster is crucial for achieving a highly available platform for workloads. The following list provides an overview of the planning steps that should be considered when configuring a cluster. Note The Managing Serviceguard user's guide provides extensive documentation and planning worksheets that assist in the planning process. HP highly recommends that you consult the user's guide when going through the planning process for a Serviceguard cluster.
Hardware planning should consider every aspect of the hardware's configuration while paying special attention to any component that is a single point of failure. The loss of any one component should not affect the workload in a high availability environment. The hardware planning steps are generally broken down into planning for highly available power, storage, and networking. Power is an aspect of planning that can be easily overlooked but is crucial for you to perform thoroughly. This includes ensuring that no single power circuit outage would cause a loss of enough resources to prevent the cluster from operating. Each individual component does not need to be connected to a separate power circuit, but the key is to ensure that the loss of any one power circuit does not prevent the cluster from operating. As a simple example, each copy of a mirrored data disk should be on a separate power circuit; that way, at least one copy of the mirrored disk will be available if a power circuit fails. For even more power reliability, you can use an uninterruptible power supply (UPS) to protect from short-term power losses. In addition, many devices now have multiple power cords that allow a single device to have redundant power connections. These power cords should be connected to separate power circuits. Storage devices must be carefully planned. Every storage device must be configured with a redundant mirror, including the root device. In addition, steps must be taken to ensure that the failure of a single storage adapter or cable will not result in the loss of all the copies in a mirrored-disk configuration. Networking is the final aspect of hardware planning. There should be redundant network devices for each LAN connection, including the heartbeat connection. Each of the LAN cards in a redundancy set should be connected to a separate LAN switch, and those switches should be on distinct power circuits. The desired result is a cluster that will continue to function until a failed componenta power circuit, a network switch, a network cable, or a network adapter-is repaired. The repair should be performed as soon as possible because another failure could result in loss of cluster connectivity.
Serviceguard Software Configuration Planning After completing the hardware planning, the next step is planning for the software configuration of the cluster. This also includes planning for any packages that will be configured to run on the cluster and planning for the cluster lock. The following list provides more details about each of the primary software planning topics. Cluster Planning involves deciding how the cluster will be configured, especially with regard to how failovers will occur. A cluster could be configured with eight nodes, for example, seven of them active and one a standby. The standby node serves as a failover for all seven of the other nodes. Alternatively, the cluster may contain as few as two nodes, each node serving as a failover for the other. Another aspect of cluster planning is deciding how the networking interfaces will be configured, including the heartbeat connections. It is important to consider aspects such as whether a separate LAN is required for the heartbeat. If the data LAN is used for the heartbeat and it becomes saturated, then the heartbeat messages may not get transmitted in a timely fashion, which could result in a cluster failure. The cluster lock is another aspect of cluster planning. Cluster Lock Planning is an important factor to consider as part of planning the entire cluster. Either a lock disk or a quorum server is required for a cluster lock. A lock is acquired only when a cluster fails and exactly half of the cluster nodes are available to reform the cluster. In this situation, the cluster lock will be used to ensure that the other half of the cluster nodes do not also reform a cluster. When there is no lock, split-brain syndrome occurs, a circumstance when two instances of the same cluster are running at the same time. Storage Software Planning for a cluster involves deciding which volume manager and file systems will be used for the disks containing the data and programs necessary for the packages. The HP Logical Volume Manager (LVM), the VERITAS Volume Manager (VxVM), or the VERITAS Cluster Volume Manager (CVM) may be used as the volume managers in a Serviceguard cluster. The type of file system within each volume must also be considered. To a large degree, the type of file system is dictated by the application. Package Planning involves deciding where the package should run and which nodes will serve as adoptive nodes in the event of a failure. Another part of package planning is whether the package will be configured to run automatically when the cluster is started and how the adoptive node will be chosen in the event of a failure. The next node in the list of alternate nodes can be used or Serviceguard can be configured to start the package on the node that has the least number of packages running. Finally, the behavior of the package after the primary node is restored must be considered. The package can continue to run on the adoptive node until the package is manually moved back to the primary node or Serviceguard can be configured to automatically move the package back to the primary node when it becomes available.
After completing the planning phases, the configuration and implementation of the cluster can begin. The example scenario described in the next section provides a concrete example of configuration of a Serviceguard cluster using the Serviceguard Manager graphical user interface. The Serviceguard Manager application used in the example scenario is delivered as a separate product from the core Serviceguard application in the bundle B8325BA. The application is available for Linux, Windows, and HP-UX. In addition to running the application natively on a Serviceguard Linux or HP-UX cluster, a Windows desktop can be used to remotely manage the cluster configuration. |