Chapter 26. Character Sets
| CONTENTS |
|
By default, an XML parser assumes that XML documents are written in the UTF-8 encoding of Unicode. However, documents may instead be written in any character set the XML processor understands, provided that there's either some external metadata like an HTTP header or internal metadata like a byte order mark or an encoding declaration that specifies the character set. For example, a document written in the Latin-5 character set would need this XML declaration:
<?xml version="1.0" encoding="ISO-8859-9"?>
Most good XML processors understand many common character sets. The XML specification recommends the character names shown in Table 26-1. When using any of these character sets, you should use these names. Of these character sets, only UTF-8 and UTF-16 must be supported by all XML processors, though many XML processors support all character sets listed here, and many support additional character sets besides. When using character sets not listed here, you should use the names specified in the IANA character sets registry at http://www.iana.org/assignments/character-sets.
| Name | Character set |
|---|---|
| UTF-8 | The default encoding used in XML documents, unless an encoding declaration, byte order mark, or external metadata specifies otherwise; a variable-width encoding of Unicode that uses one to six bytes per character. UTF-8 is designed such that all ASCII documents are legal UTF-8 documents, which is not true for other character sets, such as UTF-16 and Latin-1. This character set is the best encoding choice if your XML documents contain limited Chinese, Japanese, or Korean. |
| UTF-16 | A two-byte encoding of Unicode in which all Unicode characters defined in Unicode 3.0 and earlier (including the ASCII characters) occupy exactly two bytes. However, characters from planes 1 through 14, added in Unicode 3.1 and later, are encoded using surrogate pairs of 4 bytes each. This encoding is the best choice if your XML documents contain substantial amounts of Chinese, Japanese, or Korean. |
| ISO-10646-UCS-2 | The Basic Multilingual Plane of Unicode, i.e., plane 0. This character set is the same as UTF-16, except that it does not allow surrogate pairs to represent characters with code points beyond 65,535. The difference is only significant in Unicode 3.1 and later. Each Unicode character is represented as exactly one two-byte, unsigned integer. Determining endianness requires a byte-order mark at the beginning of the file. |
| ISO-10646-UCS-4 | A four-byte encoding of Unicode in which each Unicode character is represented as exactly one four-byte, unsigned integer. Determining endianness requires a byte-order mark at the beginning of the file. |
| ISO-8859-1 | Latin-1, ASCII plus the characters needed for most Western European languages, including Danish, Dutch, English, Faroese, Finnish, Flemish, German, Icelandic, Irish, Italian, Norwegian, Portuguese, Spanish, and Swedish. Some non-European languages, such as Hawaiian, Indonesian, and Swahili, also use these characters. |
| ISO-8859-2 | Latin-2, ASCII plus the characters needed for most Central European languages, including Croatian, Czech, Hungarian, Polish, Slovak, and Slovenian. |
| ISO-8859-3 | Latin-3, ASCII plus the characters needed for Esperanto, Maltese, Turkish, and Galician. Latin-5, ISO-8859-9, however, is now preferred for Turkish. |
| ISO-8859-4 | Latin-4, ASCII plus the characters needed for the Baltic languages Latvian, Lithuanian, Greenlandic, and Lappish. Now largely replaced by ISO-8859-10, Latin-6. |
| ISO-8859-5 | ASCII plus the Cyrillic characters used for Byelorussian, Bulgarian, Macedonian, Russian, Serbian, and Ukrainian. |
| ISO-8859-6 | ASCII plus Arabic |
| ISO-8859-7 | ASCII plus modern Greek. |
| ISO-8859-8 | ASCII plus Hebrew. |
| ISO-8859-9 | Latin-5, which is essentially the same as Latin-1 (ASCII plus Western Europe), except that the Turkish letters |
| ISO-8859-10 | Latin-6, which covers the characters needed for the Northern European languages Estonian, Lithuanian, Greenlandic, Icelandic, Inuit, and Lappish. It's similar to Latin-4, but drops some symbols and the Latvian letter, |
| ISO-8859-11 | Adds the Thai alphabet to basic ASCII. However, it is not well supported by current XML parsers, and you're probably better off using Unicode instead. |
| ISO-8859-12 | Not yet in existence and unlikely to exist in the foreseeable future. At one point, this character set was considered for Devanagari, so the number was reserved. However, this effort is not yet off the ground, and it now seems likely that the increasing acceptance of Unicode will make such a character set unnecessary. |
| ISO-8859-13 | Another character set designed to cover the Baltic languages. This set adds back in the Latvian letter |
| ISO-8859-14 | Latin-8; a variant of Latin-1 with extra letters needed for Gaelic and Welsh, such as |
| ISO-8859-15 | Known officially as Latin-9 and unofficially as Latin-0; a revision of Latin-1 that replaces the international currency symbol with the Euro sign |
| ISO-8859-16 | Latin-10; intended primarily for Romanian. |
| ISO-2022-JP | A seven-bit encoding of the character set defined in the Japanese national standard JIS X-0208-1997 used on web pages and in email; see RFC 1468. |
| Shift_JIS | The encoding of the Japanese national standard character set JIS X-0208-1997 used in Microsoft Windows. |
| EUC-JP | The encoding of the Japanese national standard character set JIS X-0208-1997 used by most Unixes. |
Some parsers do not understand all these encodings. Specifically, parsers based on James Clark's expat often support only UTF-8, UTF-16, ISO-8859-1, and US-ASCII encodings. Xerces-C supports ASCII, UTF-8, UTF-16, UCS4, IBM037, IBM1140, ISO-8859-1, and Windows-1252. IBM's XML4C parser, derived from the Xerces codebase, adds over 100 more encodings, including ISO-8859 character sets 1 through 9 and 15. However, for maximum cross-parser compatibility, you should convert your documents to either UTF-8 or UTF-16 before publishing them, even if you author them in another character set.
26.1 Character Tables
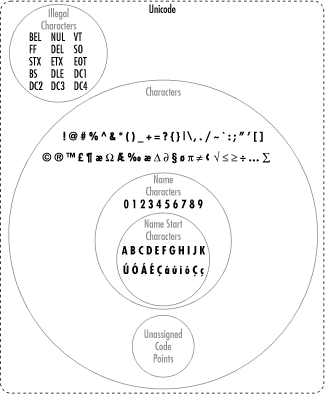
The XML 1.0 specification divides Unicode into five overlapping sets:
- Name characters
-
Characters that can appear in an element, attribute, or entity name. These characters are letters, ideographs, digits, and the punctuation marks _, -, ., and :. In the tables that follow, name characters are shown in bold type, such as A, ,
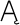 ,
, 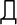 ,
, 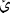 , 1, 2, 3,
, 1, 2, 3,  ,
, 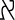 , and _.
, and _. - Name start characters
-
Characters that can be the first character of an element, attribute, or entity name. These characters are letters, ideographs, and the underscore _. In the tables that follow, these characters are shown with a gray background, such as A, ,
, ,, , , and _. Because name start characters are a subset of name characters, they are also shown in bold. - Character data characters
-
All characters that can be used anywhere in an XML document, including element and attribute content, comments, and DTDs. This set includes almost all Unicode characters, except for surrogates and most C0 control characters. These characters are shown in a normal typeface. If they are name characters, then they will be bold. If they are also name start characters, they'll have a gray background.
- Illegal characters
-
Characters that may not appear anywhere in an XML document, such as in part of a name, character data, or comment text. These characters are shown in italic, such as NUL or BEL. Most of these characters are either C0 control characters or half of a surrogate pair.
- Unassigned code points
-
Bytes or byte sequences that are not assigned to a character as of Unicode 3.1.1. Theoretically, a program could produce a file containing one of these byte sequences, but their meaning is undefined and they should be avoided. They are represented in the following tables as n/a.
Figure 26-1 shows the relationship between these sets. Note that all name start characters are name characters and that all name characters are character data characters.
Figure 26-1. XML's division of Unicode characters
In all the tables that follow, each cell's upper lefthand corner contains the character's two-digit Unicode hexadecimal value and the upper righthand corner contains the character's Unicode decimal value. You can insert a character in an XML document by prefixing the decimal value with &# and suffixing it with a semicolon. Thus, Unicode character 69, the capital letter E, can be written as E. Hexadecimal values work the same way, except that you prefix them with &#x;. In hexadecimal, the letter E is 45, so it can also be written as E.
26.1.1 ASCII
Most character sets in common use today are supersets of ASCII. That is, code points 0 through 127 are assigned to the same characters to which ASCII assigns them. Figure 26-2 lists the ASCII character set. The only notable exceptions are the EBCDIC-derived character sets. Specifically, Unicode is a superset of ASCII, and code points 1 through 127 identify the same characters in Unicode as they do in ASCII.
Figure 26-2. The first 128 Unicode characters (known as the ASCII character set)
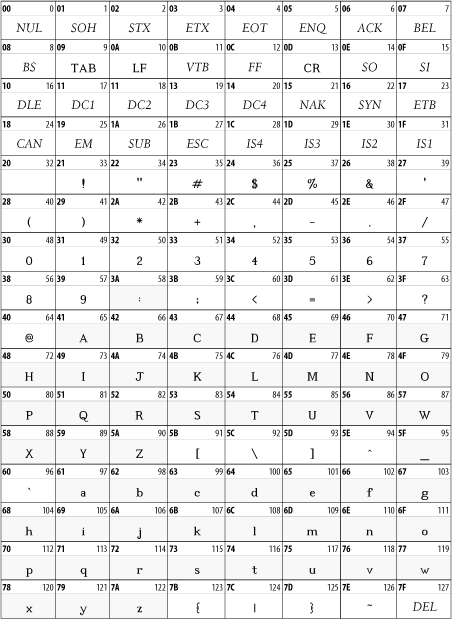
Characters 0 through 31 and character 127 are nonprinting control characters, sometimes called the C0 controls to distinguish them from the C1 controls used in the ISO-8859 character sets. Of these 33 characters, only the carriage return, linefeed, and horizontal tab may appear in XML documents. The other 29 may not appear anywhere in an XML document, including in tags, comments, or parsed character data. They may not be inserted with character references, such as . For example, you may not use form feeds to insert page breaks.
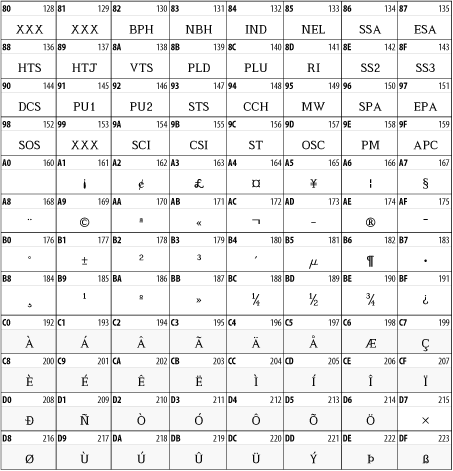
26.1.2 ISO-8859-1, Latin-1
Character sets defined by the ISO-8859 standard comprise one popular superset of the ASCII character sets. These characters all provide the normal ASCII characters from code points 0 through 127 and the C1 controls from 128 to 159, as well as change the characters from 160 through 255.
In particular, many Western European and American systems use a character set called Latin-1. This set is the first code page defined in the ISO-8859 standard and is also called ISO-8859-1. Though all common encodings of Unicode map code points 128 through 255 differently than Latin-1, code points 128 through 255 map to the same characters in both Latin-1 and Unicode. This situation does not occur in other character sets.
26.1.2.1 C1 controls
All ISO-8859 character sets begin with the same 32 extra nonprinting control characters in code points 128 through 159. These sets are used on terminals like the DEC VT-320 to provide graphics functionality not included in ASCII, for example, erasing the screen and switching it to inverse video or graphics mode. These characters cause severe problems for anyone reading or editing an XML document on a terminal or terminal emulator.
Fortunately, these characters are not necessary in XML documents. Their inclusion in XML 1.0 was an oversight. They should have been banned like the C0 controls. Unfortunately, many editors and documents incorrectly label documents written in the Cp1252 Windows character set as ISO-8859-1. This character set does use the code points between 128 and 159 for noncontrol graphics characters. When documents written with this character set are displayed or edited on a dumb terminal, they can effectively disable the user's terminal. Similar problems exist with most other Windows code pages for single-byte character sets.
In the spirit of being liberal in what you accept and conservative in what you generate, you should never use Cp1252, correctly labeled or otherwise. You should also avoid using other nonstandard code pages for documents that move beyond a single system. On the other hand, if you receive a document labeled as Cp1252 (or any other Windows code page), it can be displayed if you're careful not to throw it at a terminal unchanged. If you suspect that a document labeled as ISO-8859-1 that uses characters between 128 and 159 is in fact a Cp1252 document, you should probably reject it. This decision is difficult, however, given the prevalence of broken software that does not identify documents sent properly.
26.1.2.2 Latin-1
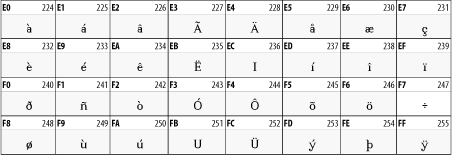
Latin-1 covers most Western European languages that use some variant of the Latin alphabet. Characters 0 through 127 in this set are identical to the ASCII characters with the same code points. Characters 128 to 159 are the C1 control characters used only for dumb terminals. Character 160 is the nonbreaking space. Characters 161 through 255 are accented characters, such as , , and , non-U.S. punctuation marks, such as and , and a few new letters, such as the Icelandic ![]() and . Figure 26-3 shows the upper half of this character set. The lower half is identical to the ASCII character set shown in Figure 26-2.
and . Figure 26-3 shows the upper half of this character set. The lower half is identical to the ASCII character set shown in Figure 26-2.
Figure 26-3. Unicode characters between 160 and 255 and the second half of the Latin-1, ISO-8859-1 character set
26.2 HTML4 Entity Sets
HTML 4.0 predefines several hundred named entities for use in your documents, many of which are quite useful. For instance, the nonbreaking space is . XML, however, defines only five named entities:
- &
-
The ampersand (&)
- <
-
The less-than sign (<)
- >
-
The greater-than sign (>)
- "
-
The straight double quote (")
- '
-
The apostrophe (')
Other needed characters can be inserted with character references in decimal or hexadecimal format. For instance, the nonbreaking space is Unicode character 160 (decimal). Therefore, you can insert it in your document as either   or  . If you really want to type it as , you can define this entity reference in your DTD. Doing so requires you to use a character reference:
<!ENTITY nbsp " ">
The XHTML 1.0 specification includes three DTD fragments that define the familiar HTML character references:
- Latin-1 characters (http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent)
-
The non-ASCII, graphic characters included in ISO-8859-1 from code points 160 through 255, shown in Figure 26-3
- Special characters (http://www.w3.org/TR/xhtml1/DTD/xhtml-special.ent)
-
A few useful letters and punctuation marks not included in Latin-1
- Symbols (http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent)
-
The Greek alphabet, plus various arrows, mathematical operators, and other symbols used in mathematics
Feel free to borrow these entity sets for your own use. They should be included in your document's DTD with these parameter entity references and PUBLIC identifiers:
<!ENTITY % HTMLlat1 PUBLIC "-//W3C//ENTITIES Latin 1 for XHTML//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent"> %HTMLlat1; <!ENTITY % HTMLspecial PUBLIC "-//W3C//ENTITIES Special for XHTML//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml-special.ent"> %HTMLspecial; <!ENTITY % HTMLsymbol PUBLIC "-//W3C//ENTITIES Symbols for XHTML//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent"> %HTMLsymbol;
However, we do recommend saving local copies and changing the system identifier to match the new location, rather than downloading them from the http://www.w3.org every time you need to parse a file. You may import just one, two, or all three of them, depending on what you need. There are no interdependencies.
Alternatively, just use the character references given in Table 26-4 through Table 26-6.
| Character | Meaning | XHTMLentity reference | Hexadecimalcharacter reference | Decimalcharacter reference |
|---|---|---|---|---|
|
| Nonbreaking space | |   |   |
|
| Inverted exclamation mark | ¡ | ¡ | ¡ |
|
| Cent sign | ¢ | ¢ | ¢ |
|
| Pound sign | £ | £ | £ |
|
| Currency sign | ¤ | ¤ | ¤ |
|
| Yen sign, Yuan sign | ¥ | ¥ | ¥ |
| | | Broken vertical bar | ¦ | ¦ | ¦ |
|
| Section sign | § | § | § |
| | Dieresis, spacing dieresis | ¨ | ¨ | ¨ |
|
| Copyright sign | © | © | © |
|
| Feminine ordinal indicator | ª | ª | ª |
|
| Left-pointing double angle quotation mark, left-pointing guillemot | « | « | « |
|
| Not sign | ¬ | ¬ | ¬ |
| - | Soft hyphen, discretionary hyphen | ­ | ­ | ­ |
|
| Registered trademark sign | ® | ® | ® |
|
| Macron, overline, APL overbar | ¯ | ¯ | ¯ |
|
| Degree sign | ° | ° | ° |
|
| Plus-or-minus sign | ± | ± | ± |
| 2 | Superscript digit two, squared | ² | ² | ² |
| 3 | Superscript digit three, cubed | ³ | ³ | ³ |
|
| Acute accent, spacing acute | ´ | ´ | ´ |
| m | Micro sign | µ | µ | µ |
|
| Pilcrow sign, paragraph sign | ¶ | ¶ | ¶ |
| | Middle dot, Georgian comma, Greek middle dot | · | · | · |
|
| Cedilla, spacing cedilla | ¸ | ¸ | ¸ |
| 1 | Superscript digit one | ¹ | ¹ | ¹ |
|
| Masculine ordinal indicator | º | º | º |
|
| Right-pointing double angle quotation mark, right-pointing guillemot | » | » | » |
| 1/4 | Vulgar fraction one-quarter | ¼ | ¼ | ¼ |
| 1/2 | Vulgar fraction one-half | ½ | ½ | ½ |
| 3/4 | Vulgar fraction three-quarters | ¾ | ¾ | ¾ |
|
| Inverted question mark | ¿ | ¿ | ¿ |
|
| Latin capital letter A with grave | À | À | À |
|
| Latin capital letter A with acute | Á | Á | Á |
|
| Latin capital letter A with circumflex | Â | Â | Â |
|
| Latin capital letter A with tilde | Ã | Ã | Ã |
|
| Latin capital letter A with dieresis | Ä | Ä | Ä |
|
| Latin capital letter A with ring above, Latin capital letter A ring | Å | Å | Å |
|
| Latin capital letter AE, Latin capital ligature AE | Æ | Æ | Æ |
|
| Latin capital letter C with cedilla | Ç | Ç | Ç |
|
| Latin capital letter E with grave | È | È | È |
|
| Latin capital letter E with acute | É | É | É |
|
| Latin capital letter E with circumflex | Ê | Ê | Ê |
|
| Latin capital letter E with dieresis | Ë | Ë | Ë |
|
| Latin capital letter I with grave | Ì | Ì | Ì |
|
| Latin capital letter I with acute | Í | Í | Í |
|
| Latin capital letter I with circumflex | Î | Î | Î |
|
| Latin capital letter I with dieresis | Ï | Ï | Ï |
| | Latin capital letter eth | Ð | Ð | Ð |
|
| Latin capital letter N with tilde | Ñ | Ñ | Ñ |
|
| Latin capital letter O with grave | Ò | Ò | Ò |
|
| Latin capital letter O with acute | Ó | Ó | Ó |
|
| Latin capital letter O with circumflex | Ô | Ô | Ô |
|
| Latin capital letter O with tilde | Õ | Õ | Õ |
|
| Latin capital letter O with dieresis | Ö | Ö | Ö |
| x | Multiplication sign | × | × | × |
|
| Latin capital letter O with stroke | Ø | Ø | Ø |
|
| Latin capital letter U with grave | Ù | Ù | Ù |
|
| Latin capital letter U with acute | Ú | Ú | Ú |
|
| Latin capital letter U with circumflex | Û | Û | Û |
|
| Latin capital letter U with dieresis | Ü | Ü | Ü |
| | Latin capital letter Y with acute | Ý | Ý | Ý |
| | Latin capital letter thorn | Þ | Þ | Þ |
|
| Latin small letter sharp s, ess-zett | ß | ß | ß |
|
| Latin small letter a with grave | à | à | à |
|
| Latin small letter a with acute | á | á | á |
|
| Latin small letter a with circumflex | â | â | â |
|
| Latin small letter a with tilde | ã | ã | ã |
|
| Latin small letter a with dieresis | ä | ä | ä |
|
| Latin small letter a with ring above | å | å | å |
|
| Latin small letter ae, Latin small ligature ae | æ | æ | æ |
|
| Latin small letter c with cedilla | ç | ç | ç |
|
| Latin small letter e with grave | è | è | è |
|
| Latin small letter e with acute | é | é | é |
|
| Latin small letter e with circumflex | ê | ê | ê |
|
| Latin small letter e with dieresis | ë | ë | ë |
|
| Latin small letter i with grave | ì | ì | ì |
|
| Latin small letter i with acute | í | í | í |
|
| Latin small letter i with circumflex | î | î | î |
|
| Latin small letter i with dieresis | ï | ï | ï |
| | Latin small letter eth | ð | ð | ð |
|
| Latin small letter n with tilde | ñ | ñ | ñ |
|
| Latin small letter o with grave | ò | ò | ò |
|
| Latin small letter o with acute | ó | ó | ó |
|
| Latin small letter o with circumflex | ô | ô | ô |
|
| Latin small letter o with tilde | õ | õ | õ |
|
| Latin small letter o with dieresis | ö | ö | ö |
|
| Division sign | ÷ | ÷ | ÷ |
|
| Latin small letter o with stroke | ø | ø | ø |
|
| Latin small letter u with grave | ù | ù | ù |
|
| Latin small letter u with acute | ú | ú | ú |
|
| Latin small letter u with circumflex | û | û | û |
|
| Latin small letter u with dieresis | ü | ü | ü |
| | Latin small letter y with acute | ý | ý | ý |
| | Latin small letter thorn | þ | þ | þ |
|
| Latin small letter y with dieresis | ÿ | ÿ | ÿ |
| Character | Meaning | XHTML entity reference | Hexadecimal character reference | Decimal character reference |
|---|---|---|---|---|
| " | Quotation mark, APL quote | " | " | " |
| & | Ampersand | & | & | & |
| ' | Apostrophe mark | ' | ' | ' |
| < | Less-than sign | < | < | < |
| > | Greater-than sign | > | > | > |
| | Latin capital ligature OE | Π| Π| Π|
| | Latin small ligature oe | œ | œ | œ |
| | Latin capital letter S with caron | Š | Š | Š |
| | Latin small letter s with caron | š | š | š |
| | Latin capital letter Y with dieresis | Ÿ | Ÿ | Ÿ |
| ~ | Modifier letter circumflex accent | ˆ | ˆ | ˆ |
| ~ | Small tilde | ˜ | ˜ | ˜ |
| En space |   |   |   | |
| Em space |   |   |   | |
| Thin space |   |   |   | |
| Nonprinting character | Zero width nonjoiner | ‌ | ‌ | ‌ |
| Nonprinting character | Zero width joiner | ‍ | ‍ | ‍ |
| Nonprinting character | Left-to-right mark | ‎ | ‎ | ‎ |
| Nonprinting character | Right-to-left mark | ‏ | ‏ | ‏ |
| - | En dash | – | – | – |
|
| Em dash | — | — | — |
| ` | Left single quotation mark | ‘ | ‘ | ‘ |
| ' | Right single quotation mark | ’ | ’ | ’ |
| , | Single low-9 quotation mark | ‚ | ‚ | ‚ |
| " | Left double quotation mark | “ | “ | “ |
| " | Right double quotation mark | ” | ” | ” |
| | Double low-9 quotation mark | „ | „ | „ |
| | Dagger | † | † | † |
| | Double dagger | ‡ | ‡ | ‡ |
| | Per mille sign | ‰ | ‰ | ‰ |
| | Single left-pointing angle quotation mark | ‹ | ‹ | ‹ |
| | Single right-pointing angle quotation mark | › | › | › |
| | Euro sign | € | € | € |
| Character | Meaning | XHTML entity reference | Hexadecimal character reference | Decimal character reference |
|---|---|---|---|---|
| | Latin small f with hook, function, florin | ƒ | ƒ | ƒ |
| A | Greek capital letter alpha | Α | Α | Α |
| B | Greek capital letter beta | Β | Β | Β |
| | Greek capital letter gamma | Γ | Γ | Γ |
| | Greek capital letter delta | Δ | Δ | Δ |
| E | Greek capital letter epsilon | Ε | Ε | Ε |
| Z | Greek capital letter zeta | Ζ | Ζ | Ζ |
| H | Greek capital letter eta | Η | Η | Η |
| | Greek capital letter theta | Θ | Θ | Θ |
| I | Greek capital letter iota | Ι | Ι | Ι |
| K | Greek capital letter kappa | Κ | Κ | Κ |
| | Greek capital letter lambda | Λ | Λ | Λ |
| M | Greek capital letter mu | Μ | Μ | Μ |
| N | Greek capital letter nu | Ν | Ν | Ν |
| | Greek capital letter xi | Ξ | Ξ | Ξ |
| O | Greek capital letter omicron | Ο | Ο | Ο |
| | Greek capital letter pi | Π | Π | Π |
| | Greek capital letter rho | Ρ | Ρ | Ρ |
| | Greek capital letter sigma | Σ | Σ | Σ |
| T | Greek capital letter tau | Τ | Τ | Τ |
| | Greek capital letter upsilon | Υ | Υ | Υ |
| | Greek capital letter phi | Φ | Φ | Φ |
| | Greek capital letter chi | Χ | Χ | Χ |
| | Greek capital letter psi | Ψ | Ψ | Ψ |
| | Greek capital letter omega | Ω | Ω | Ω |
| | Greek small letter alpha | α | α | α |
| | Greek small letter beta | β | β | β |
| | Greek small letter gamma | γ | γ | γ |
| | Greek small letter delta | δ | δ | δ |
| | Greek small letter epsilon | ε | ε | ε |
| | Greek small letter zeta | ζ | ζ | ζ |
| | Greek small letter eta | η | η | η |
| | Greek small letter theta | θ | θ | θ |
| | Greek small letter iota | ι | ι | ι |
| | Greek small letter kappa | κ | κ | κ |
| | Greek small letter lambda | λ | λ | λ |
| m | Greek small letter mu | μ | μ | μ |
| | Greek small letter nu | ν | ν | ν |
| | Greek small letter xi | ξ | ξ | ξ |
| | Greek small letter omicron | ο | ο | ο |
| | Greek small letter pi | π | π | π |
| | Greek small letter rho | ρ | ρ | ρ |
| | Greek small letter final sigma | ς | ς | ς |
| | Greek small letter sigma | σ | σ | σ |
| | Greek small letter tau | τ | τ | τ |
| | Greek small letter upsilon | υ | υ | υ |
| | Greek small letter phi | φ | φ | φ |
| | Greek small letter chi | χ | χ | χ |
| | Greek small letter psi | ψ | ψ | ψ |
| | Greek small letter omega | ω | ω | ω |
| | Greek small letter theta symbol | ϑ | ϑ | ϑ |
| | Greek upsilon with hook symbol | ϒ | ϒ | ϒ |
| | Greek pi symbol | ϖ | ϖ | ϖ |
|
| Bullet, black small circle | • | • | • |
| ... | Horizontal ellipsis, three-dot leader | … | … | … |
|
| Prime, minutes, feet | ′ | ′ | ′ |
| | Double prime, seconds, inches | ″ | ″ | ″ |
|
| Overline, spacing overscore | ‾ | ‾ | ‾ |
| / | Fraction slash | ⁄ | ⁄ | ⁄ |
| | Black letter capital I, imaginary part | ℑ | ℑ | ℑ |
| | Script capital P, power set, Weierstrass p | ℘ | ℘ | ℘ |
| | Black letter capital R, real part symbol | ℜ | ℜ | ℜ |
|
| Trademark sign | ™ | ™ | ™ |
| | Aleph symbol, first transfinite cardinal | ℵ | ℵ | ℵ |
| | Leftward arrow | ← | ← | ← |
| | Upward arrow | ↑ | ↑ | ↑ |
| | Rightward arrow | → | → | → |
| | Downward arrow | ↓ | ↓ | ↓ |
| | Left-right arrow | ↔ | ↔ | ↔ |
| | Downward arrow with corner leftward, carriage return | ↵ | ↵ | ↵ |
| | Leftward double arrow | ⇐ | ⇐ | ⇐ |
| | Upward double arrow | ⇑ | ⇑ | ⇑ |
| | Rightward double arrow | ⇒ | ⇒ | ⇒ |
| | Downward double arrow | ⇓ | ⇓ | ⇓ |
| | Left-right double arrow | ⇔ | ⇔ | ⇔ |
| | For all | ∀ | ∀ | ∀ |
| | Partial differential | ∂ | ∂ | ∂ |
| | There exists | ∃ | ∃ | ∃ |
| | Empty set, null set, diameter | ∅ | ∅ | ∅ |
| | Nabla, backward difference | ∇ | ∇ | ∇ |
| | Element of | ∈ | ∈ | ∈ |
| | Not an element of | ∉ | ∉ | ∉ |
| | Contains as member | ∋ | ∋ | ∋ |
| | N-ary product, product sign | ∏ | ∏ | ∏ |
| | N-ary summation | ∑ | ∑ | ∑ |
| - | Minus sign | − | − | − |
| * | Asterisk operator | ∗ | ∗ | ∗ |
| | Square root, radical sign | √ | √ | √ |
| | Proportional to | ∝ | ∝ | ∝ |
| | Infinity | ∞ | ∞ | ∞ |
| | Angle | ∠ | ∠ | ∠ |
| | Logical and, wedge | ∧ | ∧ | ∧ |
| | Logical or, vee | ∨ | ∨ | ∨ |
| | Intersection, cap | ∩ | ∩ | ∩ |
| | Union, cup | ∪ | ∪ | ∪ |
| | Integral | ∫ | ∫ | ∫ |
| | Therefore | ∴ | ∴ | ∴ |
| ~ | Tilde operator, varies with, similar to | ∼ | ∼ | ∼ |
| | Approximately equal to | ≅ | ≅ | ≅ |
| | Almost equal to, asymptotic to | ≈ | ≈ | ≈ |
| | Not equal to | ≠ | ≠ | ≠ |
| | Identical to | ≡ | ≡ | ≡ |
| | Less than or equal to | ≤ | ≤ | ≤ |
| | Greater than or equal to | ≥ | ≥ | ≥ |
| | Subset of | ⊂ | ⊂ | ⊂ |
| | Superset of | ⊃ | ⊃ | ⊃ |
| | Not a subset of | ⊄ | ⊄ | ⊄ |
| | Subset of or equal to | ⊆ | ⊆ | ⊆ |
| | Superset of or equal to | ⊇ | ⊇ | ⊇ |
| | Circled plus, direct sum | ⊕ | ⊕ | ⊕ |
| | Circled times, vector product | ⊗ | ⊗ | ⊗ |
| | Up tack, orthogonal to, perpendicular | ⊥ | ⊥ | ⊥ |
| | Dot operator | ⋅ | ⋅ | ⋅ |
| | Left ceiling, APL upstile | ⌈ | ⌈ | ⌈ |
| | Right ceiling | ⌉ | ⌉ | ⌉ |
| | Left floor, APL downstile | ⌊ | ⌊ | ⌊ |
| | Right floor | ⌋ | ⌋ | ⌋ |
| | Left-pointing angle bracket, bra | ⟨ | 〈 | 〈 |
| | Right-pointing angle bracket, ket | ⟩ | 〉 | 〉 |
| | Lozenge | ◊ | ◊ | ◊ |
| | Black spade suit | ♠ | ♠ | ♠ |
| | Black club suit, shamrock | ♣ | ♣ | ♣ |
| | Black heart suit, valentine | ♥ | ♥ | ♥ |
| | Black diamond suit | ♦ | ♦ | ♦ |
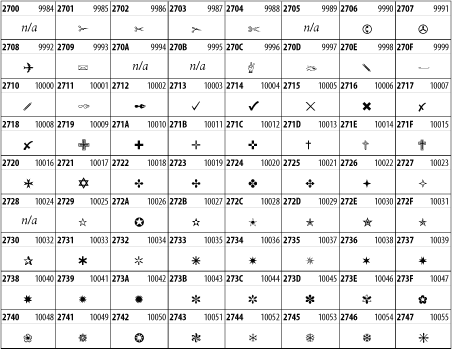
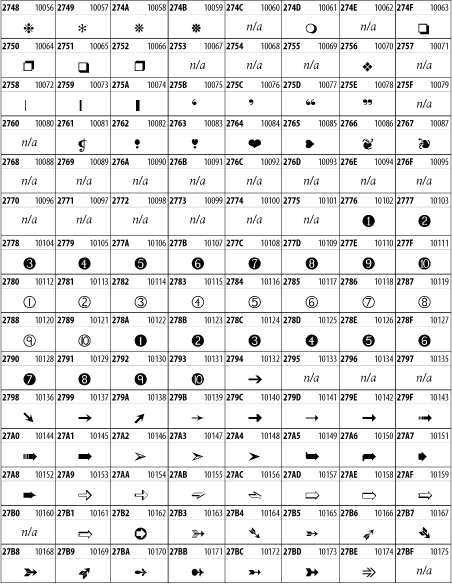
26.3 Other Unicode Blocks
So far we've accounted for a little over 300 of the more than 90,000 Unicode characters. Many thousands are still unaccounted for. Outside the ranges defined in XHTML and SGML, standard entity names don't exist. You should either use an editor that can produce the characters you need in the appropriate character set or you should use character references. Most of the 90,000-plus Unicode characters are either Han ideographs, Hangul syllables, or rarely used characters. However, we do list a few of the most useful blocks later in this chapter. Others can be found online at http://www.unicode.org/charts/ or in The Unicode Standard Version 3.0 by the Unicode Consortium (Addison Wesley, 2000).
In the tables that follow, the upper lefthand corner contains the character's hexadecimal Unicode value, and the upper righthand corner contains the character's decimal Unicode value. You can use either value to form a character reference so as to use these characters in element content and attribute values, even without an editor or fonts that support them.
26.3.1 Latin Extended-A
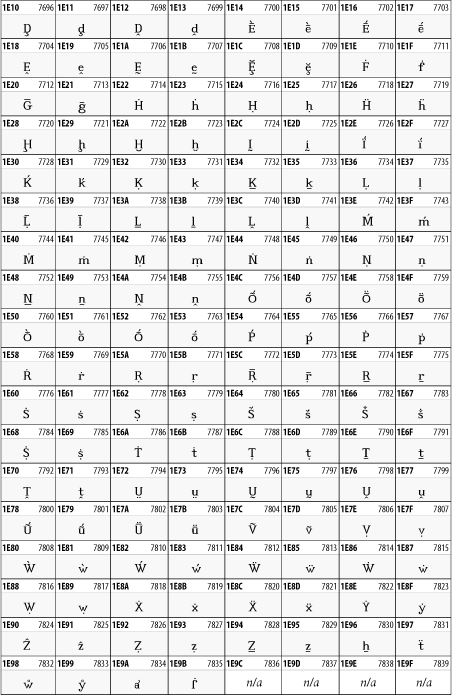
The 128 characters in the Latin Extended-A block of Unicode are used in conjunction with the normal ASCII and Latin-1 characters. They cover most European Latin letters missing from Latin-1. The block includes various characters you'll find in the upper halves of the other ISO-8859 Latin character sets, including ISO-8859-2, ISO-8859-3, ISO-8859-4, and ISO-8859-9. When combined with ASCII and Latin-1, this block lets you write Afrikaans, Basque, Breton, Catalan, Croatian, Czech, Esperanto, Estonian, French, Frisian, Greenlandic, Hungarian, Latvian, Lithuanian, Maltese, Polish, Proven al, Rhaeto-Romanic, Romanian, Romany, Sami, Slovak, Slovenian, Sorbian, Turkish, and Welsh. See Figure 26-7.
Figure 26-7. Unicode's Latin Extended-A block
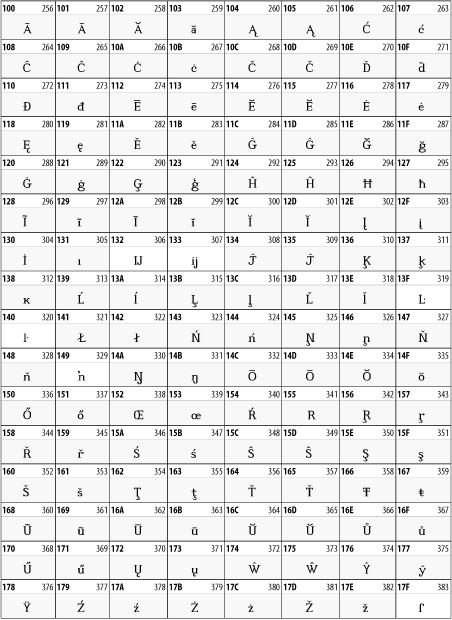
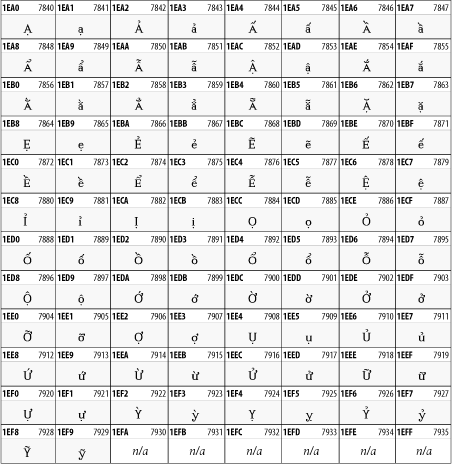
26.3.2 Latin Extended-B
The Latin Extended-B block of Unicode is used in conjunction with the normal ASCII and Latin-1 characters. It mostly contains characters used for transcription of non-European languages not traditionally written in a Roman script. For instance, it's used for the Pinyin transcription of Chinese and for many African languages. See Figure 26-8.
Figure 26-8. The Latin Extended-B block of Unicode
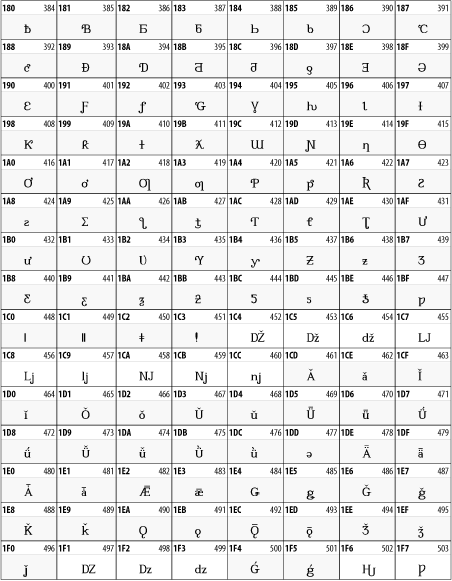
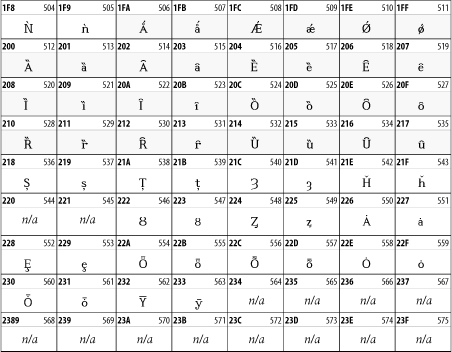
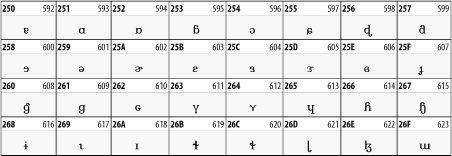
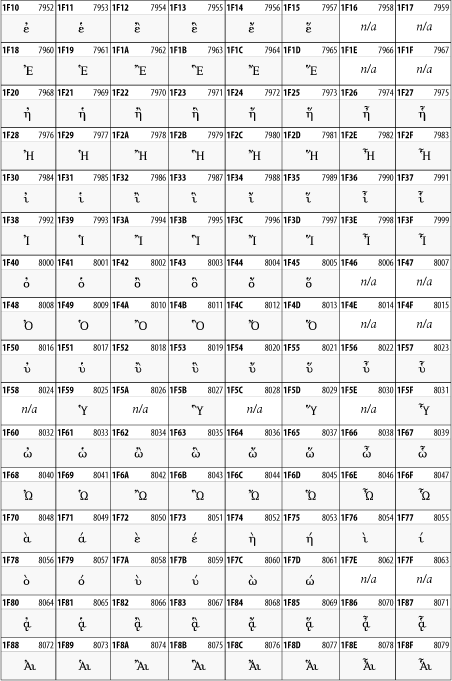
26.3.3 IPA Extensions
Linguists use the International Phonetic Alphabetic (IPA) to identify uniquely and unambiguously particular sounds of various spoken languages. Besides the symbols listed in this block, the IPA requires use of ASCII, various other extended Latin characters, the combining diacritical marks in Figure 26-11, and a few Greek letters. The block shown in Figure 26-9 only contains the characters not used in more traditional alphabets.
Figure 26-9. The IPA Extensions block of Unicode
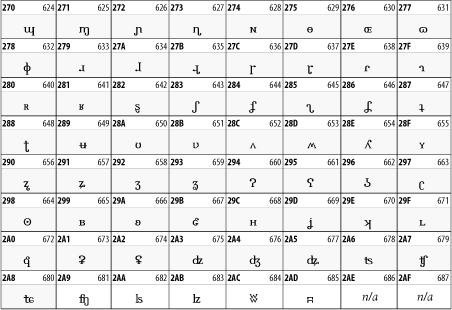
26.3.4 Spacing Modifier Letters
The Spacing Modifier Letters block, shown in Figure 26-10, includes characters from multiple languages and scripts that modify the preceding or following character, generally by changing its pronunciation.
Figure 26-10. The Spacing Modifier Letters block of Unicode
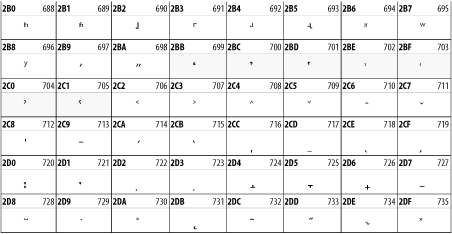

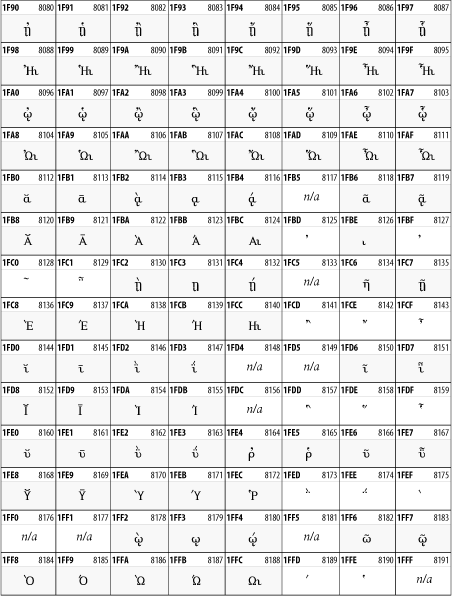
26.3.5 Combining Diacritical Marks
The Combining Diacritical Marks block contains characters that are not used on their own, such as the accent grave and circumflex. Instead, they are merged with the preceding character to form a single glyph. For example, to write the character , you could type the ASCII letter N followed by the combining tilde character, like this: Ñ. When rendered, this combination would produce the single glyph . In Figure 26-11 the character to which the diacritical mark is attached is a dotted circle ![]() (Unicode code point &0x25CC;) but of course it could be any normal character.
(Unicode code point &0x25CC;) but of course it could be any normal character.
Figure 26-11. The Combining Diacritical Marks block of Unicode
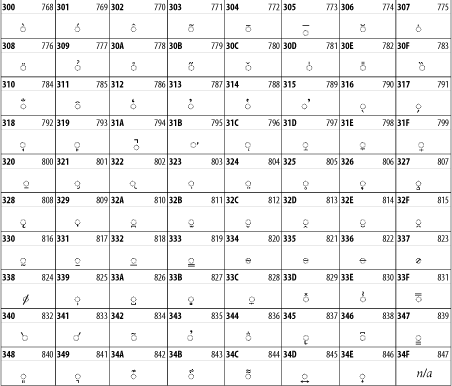
26.3.6 Greek and Coptic
The Greek block of Unicode is used primarily for the modern Greek language. Currently, it's the only option for the Greek-derived Coptic script, but it doesn't really serve that purpose very well, and a separate Coptic block is a likely addition in the future. Extending coverage to classical and Byzantine Greek requires many more accented characters, which are available in the Greek Extended Block, shown in Figure 26-22, or by combining these characters with the Combining Diacritical Marks in Figure 26-11. The Greek alphabet is also a fertile source of mathematical and scientific notation, though some common letters, such as ![]() and
and ![]() , are encoded separately in the Mathematical Operators block in Figure 26-27 and the Mathematical Alphanumeric Symbols block in Figure 26-28 for their use as mathematical symbols. The Greek and Coptic block of Unicode is shown in Figure 26-12.
, are encoded separately in the Mathematical Operators block in Figure 26-27 and the Mathematical Alphanumeric Symbols block in Figure 26-28 for their use as mathematical symbols. The Greek and Coptic block of Unicode is shown in Figure 26-12.
Figure 26-12. The Greek and Coptic block of Unicode
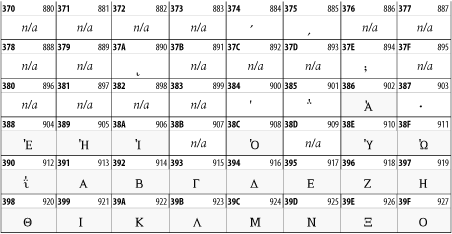
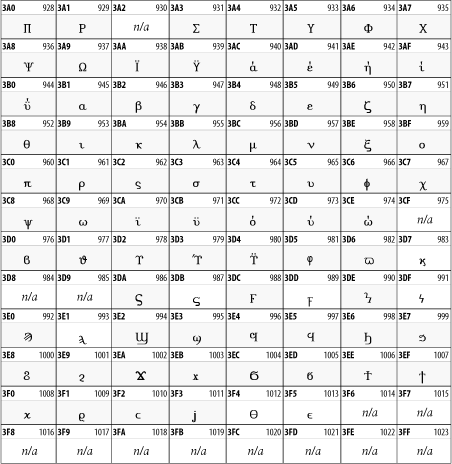
26.3.7 Cyrillic
While the Cyrillic script shown in Figure 26-13 is most familiar to Western readers from its use for Russian, it's also used for other Slavic languages, including Serbian, Ukrainian, and Byelorussian, and for many non-Slavic languages of the former Soviet Union, such as Azerbaijani, Tuvan, and Ossetian. Indeed, many characters in this block are not actually found in Russian, but exist only in other languages written in the Cyrillic script. Following the breakup of the Soviet Union, some non-Slavic languages, such as Moldavian and Azerbaijani, are now reverting to Latin-derived scripts.
Figure 26-13. The Cyrillic block of Unicode
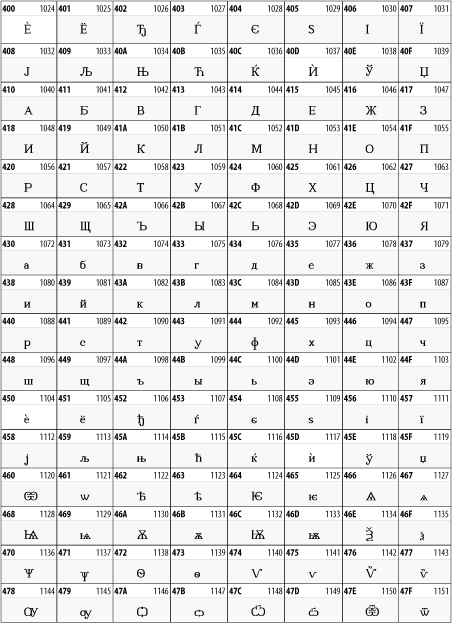
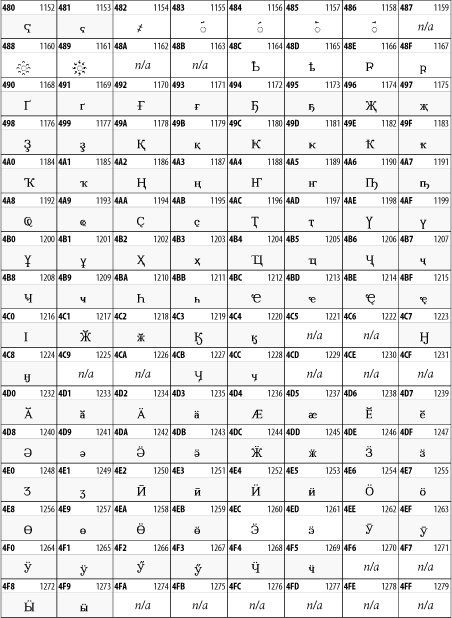
26.3.8 Armenian
The Armenian script shown in Figure 26-14 is used for writing the Armenian language, currently spoken by about seven million people around the world.
Figure 26-14. The Armenian block of Unicode
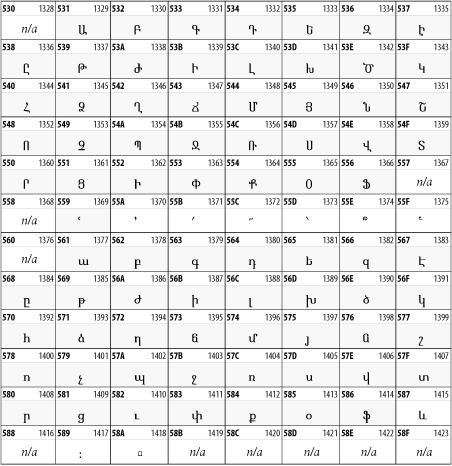
26.3.9 Hebrew
The Hebrew alphabet is used for Hebrew, Yiddish, and Judezmo. It's also occasionally used for mathematical notation. See Figure 26-15.
Figure 26-15. The Hebrew block of Unicode
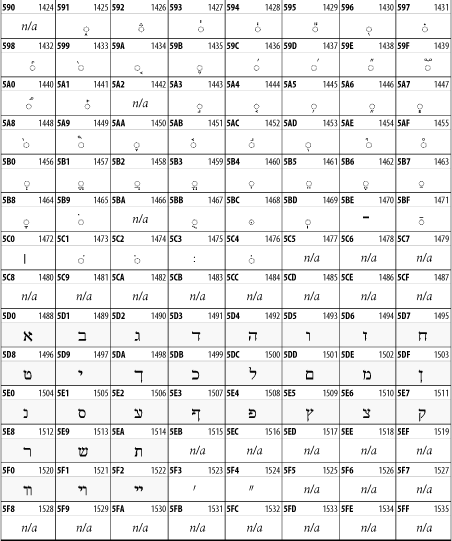
26.3.10 Arabic
The Arabic script shown in Figure 26-16 is used for many languages besides Arabic, including Kurdish, Pashto, Persian, Sindhi, and Urdu. Turkish was also written in the Arabic script until early in the twentieth century when Turkey converted to a modified Latin alphabet.
Figure 26-16. The Arabic block of Unicode
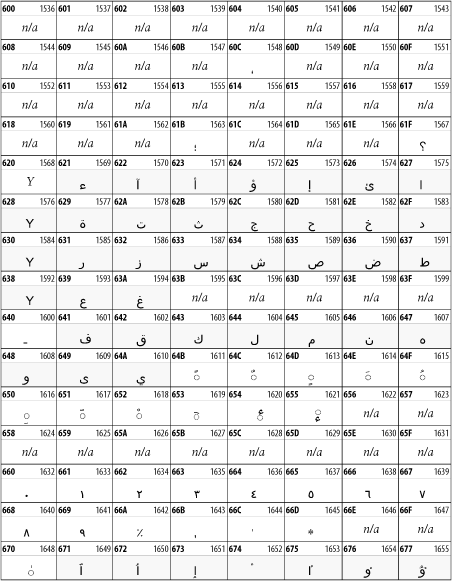
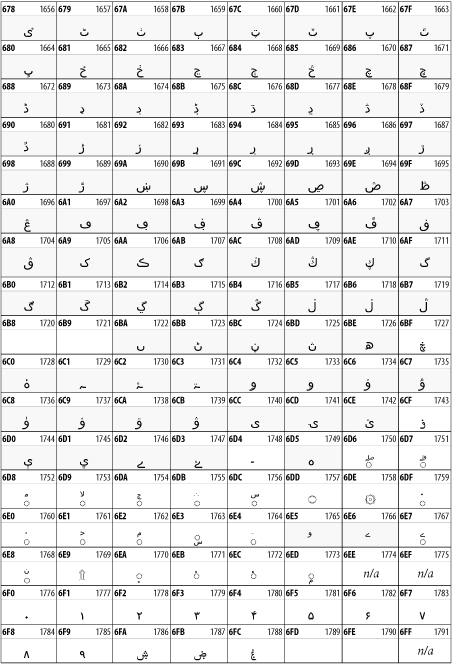
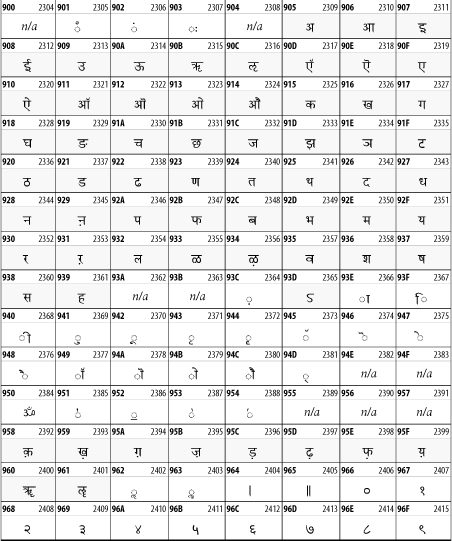
26.3.11 Devanagari
The Devanagari script is used for many languages of the Indian subcontinent, including Awadhi, Bagheli, Bhatneri, Bhili, Bihari, Braj Bhasa, Chhattisgarhi, Garhwali, Gondi, Harauti, Hindi, Ho, Jaipuri, Kachchhi, Kanauji, Konkani, Kului, Kumaoni, Kurku, Kurukh, Marwari, Mundari, Newari, Palpa, and Santali. It's also used for the classical language Sanskrit. See Figure 26-17.
Figure 26-17. The Devanagari block of Unicode

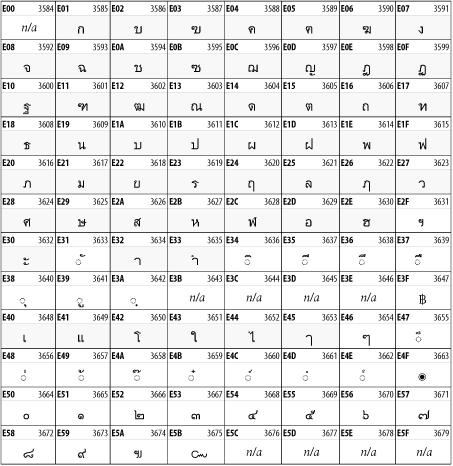
26.3.12 Thai
The Thai script is used for Thai and other Southeast Asian languages, including Kuy, Lavna, and Pali. See Figure 26-18.
Figure 26-18. The Thai block of Unicode
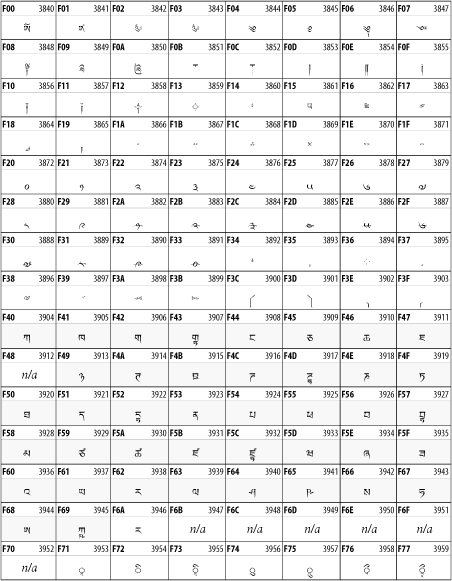
26.3.13 Tibetan
The Tibetan script is used to write the various dialects of Tibetan and Dzongkha, Bhutan's main language. Like Chinese, Tibetan is divided into mutually unintelligible spoken languages, though the written forms are identical. See Figure 26-19.
Figure 26-19. The Tibetan block of Unicode
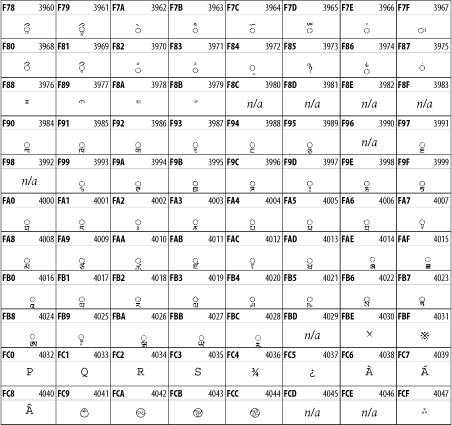
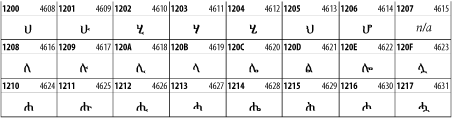
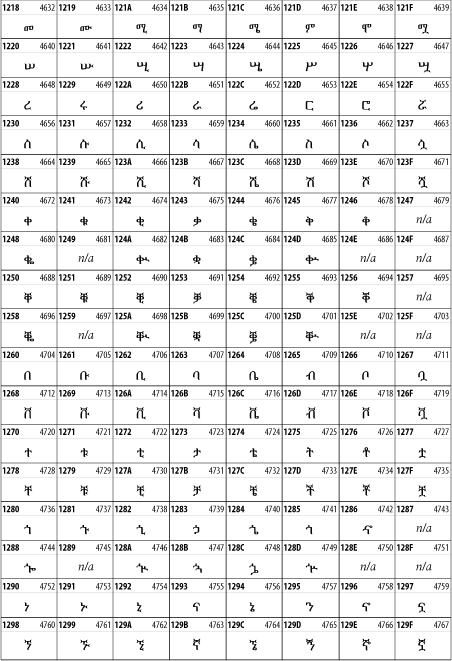
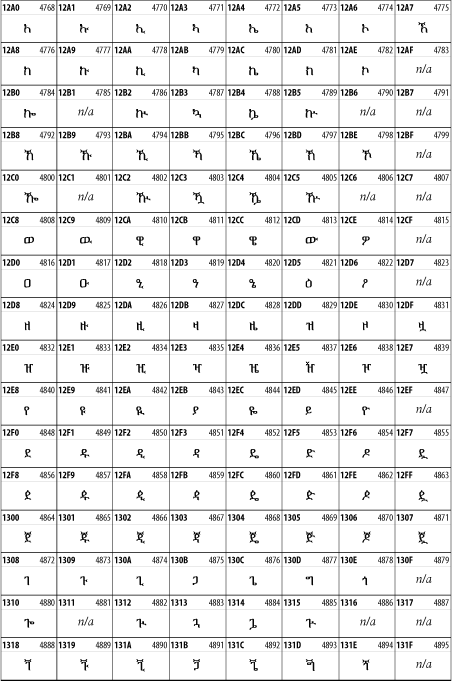
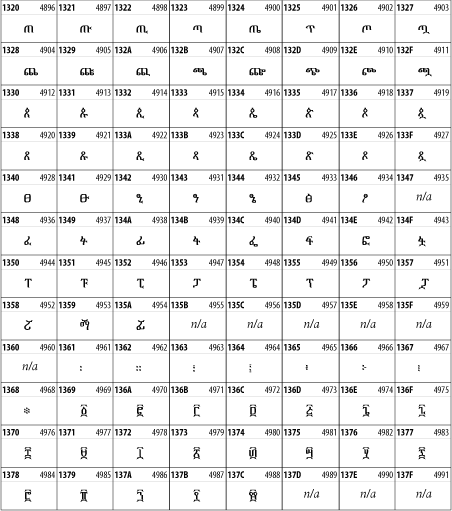
26.3.14 Ethiopic
The Ethiopic script is used by several languages in Ethiopia, including Amharic. Tigre, Oromo, and the liturgical language Ge'ez. See Figure 26-20.
Figure 26-20. The Ethiopic block of Unicode
26.3.15 Latin Extended Additional
The Latin Extended Additional characters are single code-point representations of letters combined with diacritical marks. This block is particularly useful for modern Vietnamese. See Figure 26-21.
Figure 26-21. The Latin Extended Additional block of Unicode

26.3.16 Greek Extended
The Greek Extended block shown in Figure 26-22 contains mostly archaic letters and accented letters that are used in classical and Byzantine Greek, but not in modern Greek.
Figure 26-22. The Greek Extended block of Unicode

26.3.17 General Punctuation
The General Punctuation block shown in Figure 26-23 contains punctuation characters used across a variety of languages and scripts that are not already encoded in Latin-1. Characters 0x2000 through 0x200B are all varying amounts of whitespace ranging from zero width (0x200B) to six ems (0x2007). 0x200C through 0x200F and 0x206A through 0x206F are nonprinting format characters with no graphical representation.
Figure 26-23. The General Punctuation block of Unicode
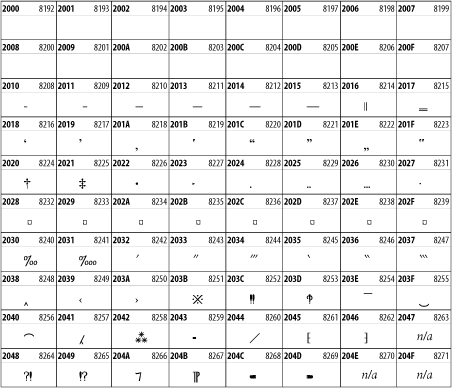
26.3.18 Currency Symbols
The Currency Symbols block includes a few monetary symbols not already encoded in other blocks, such as the Indian rupee, the Italian lira, and the Greek drachma. See Figure 26-24.
Figure 26-24. The Currency Symbols block of Unicode

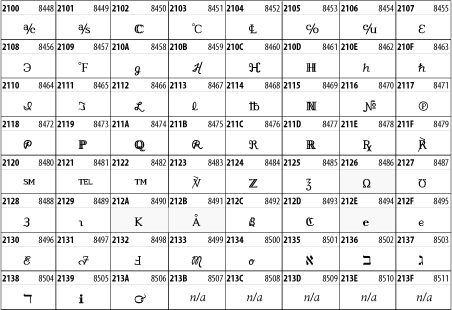
26.3.19 Letter-Like Symbols
The Letter-Like Symbols block covers characters that look like letters, but really aren't, such as the ![]() symbol used to represent a prescription. See Figure 26-25.
symbol used to represent a prescription. See Figure 26-25.
Figure 26-25. The Letter-Like Symbols block of Unicode
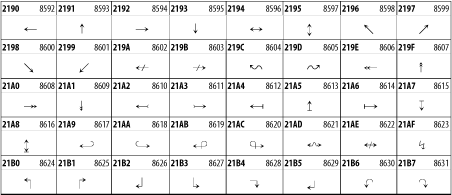
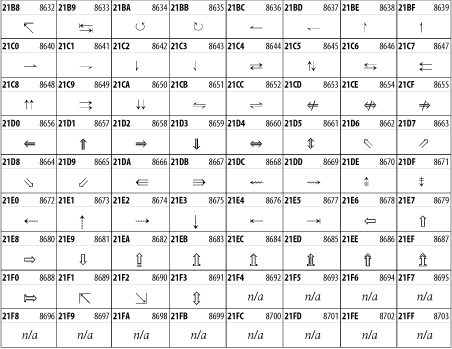
26.3.20 Arrows
The Arrows block contains commonly needed arrow characters, as shown in Figure 26-26.
Figure 26-26. The Arrows block of Unicode
26.3.21 Mathematical Operators
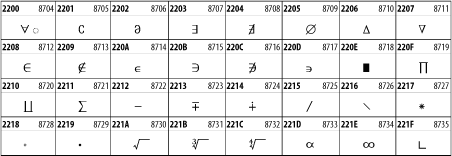
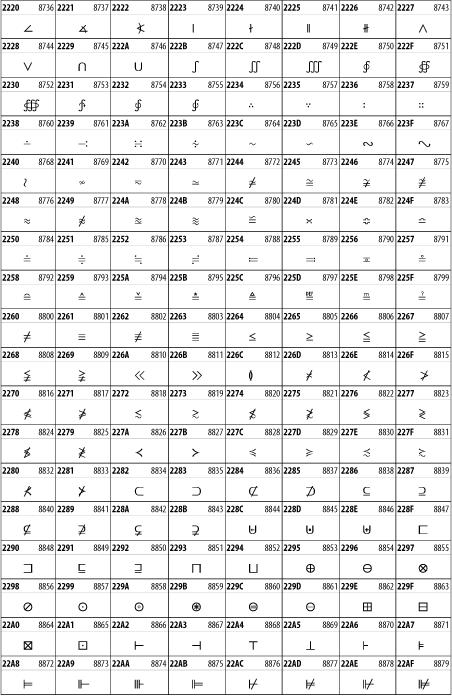
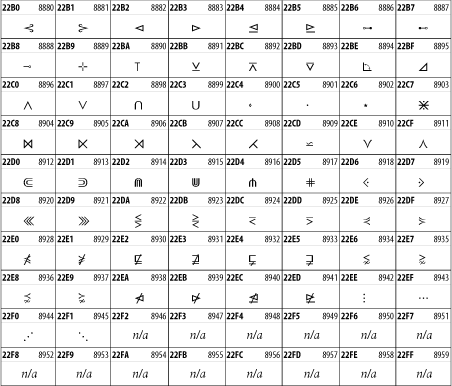
The Mathematical Operators block shown in Figure 26-27 contains a wide variety of symbols used in higher mathematics. A few of these symbols superficially resemble letters in other blocks. For instance, in most fonts character 2206, ![]() , is virtually identical to the Greek capital letter delta. However, using characters in this block is preferable for mathematical expressions, as it allows software to distinguish between letters and mathematical symbols. Fonts may use the same glyph to represent different code points in cases like this.
, is virtually identical to the Greek capital letter delta. However, using characters in this block is preferable for mathematical expressions, as it allows software to distinguish between letters and mathematical symbols. Fonts may use the same glyph to represent different code points in cases like this.
Figure 26-27. The Mathematical Operators block of Unicode
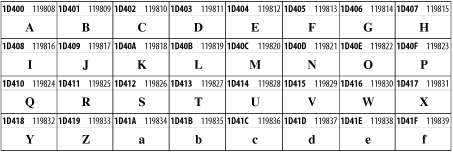
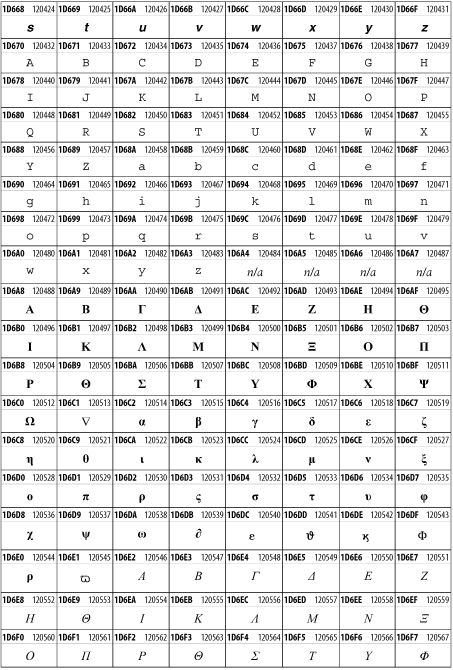
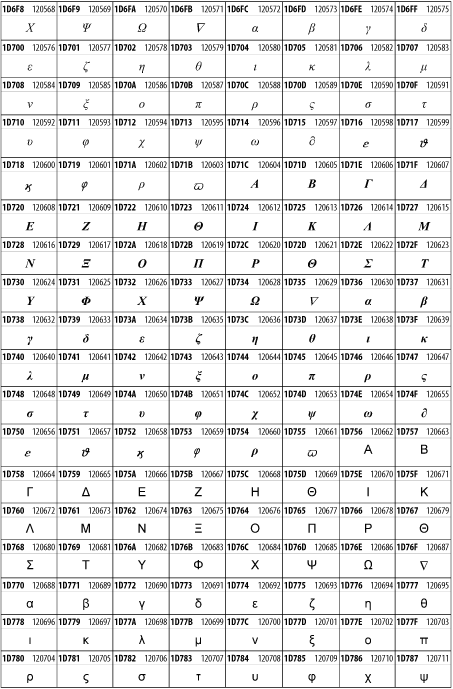
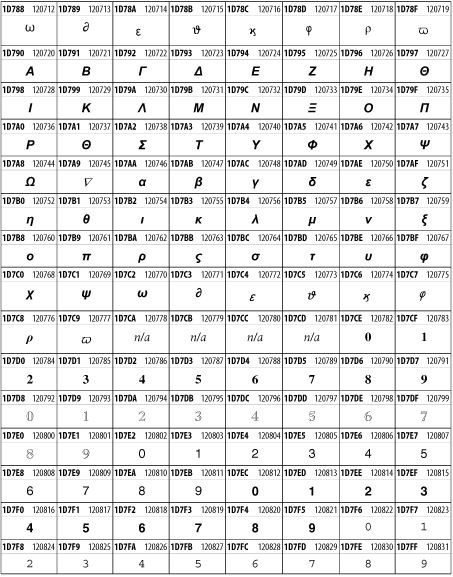
Unicode 3.1.1 adds one more block of mathematical alphanumeric symbols in Plane 1 between 0x1D400 and 0x1D7FF as shown in Figure 26-28. Mostly these are repetitions of the ASCII and Greek letters and digits in what would normally be considered font variations. For instance, 0x1D400 is mathematical bold capital A. The justification for these is that when used in an equation, they really aren't the same characters as the equivalent glyphs in text.
Figure 26-28. The Mathematical Alphanumeric Symbols block of Unicode
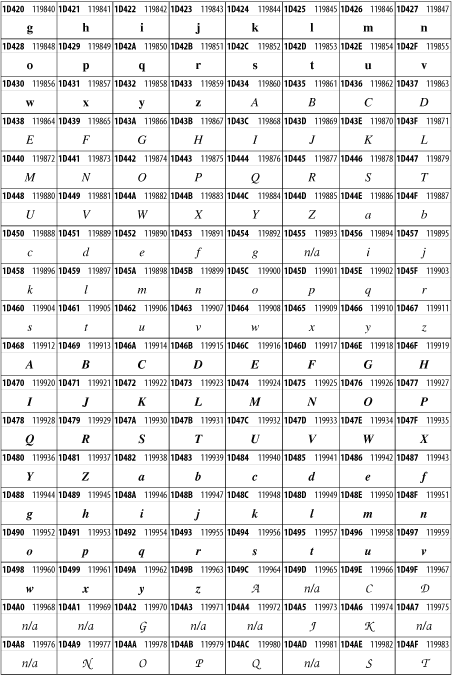
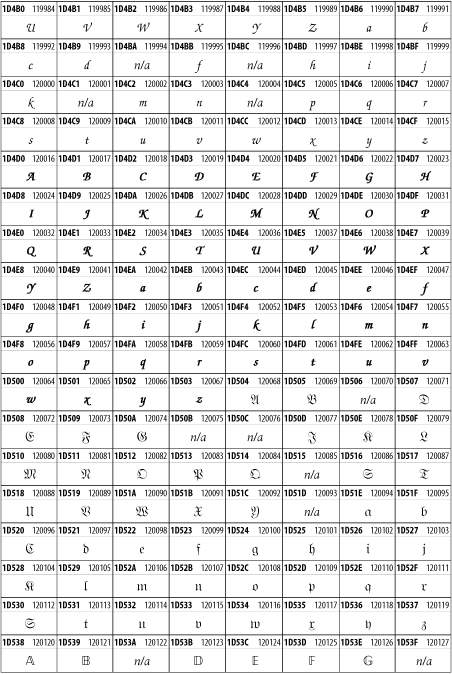
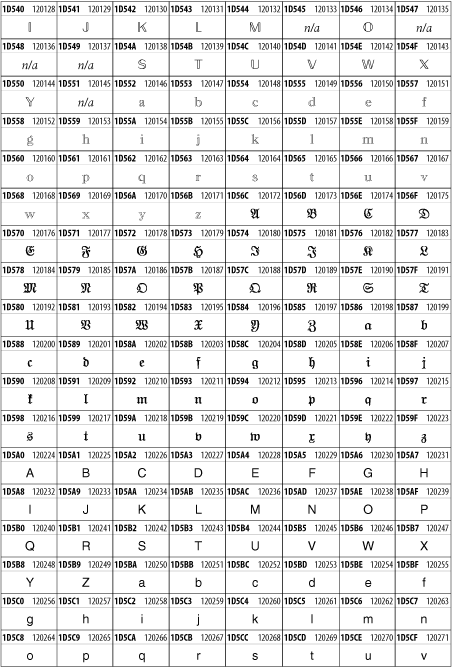
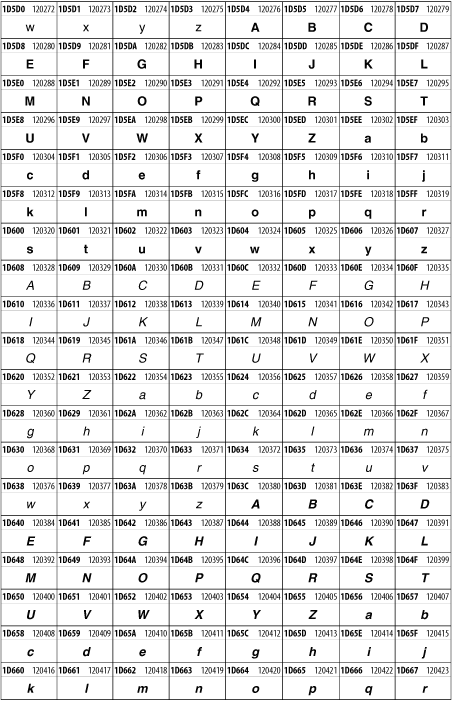
26.3.22 Miscellaneous Technical
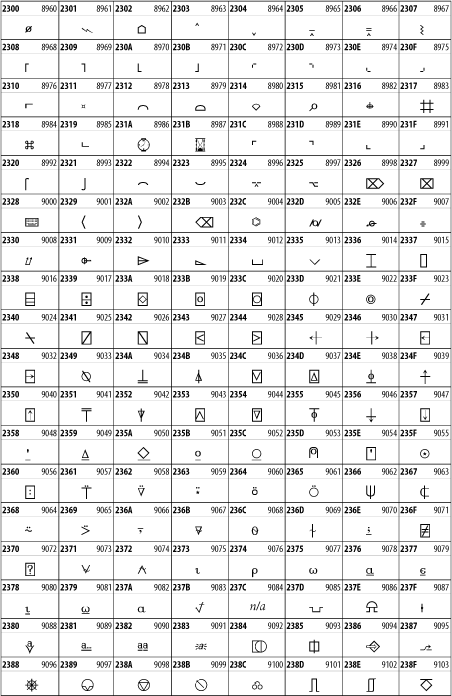
The Miscellaneous Technical block shown in Figure 26-29 contains an assortment of symbols taken from electronics, quantum mechanics, the APL programming language, the ISO-9995-7 standard for language-neutral keyboard pictograms, and other sources.
Figure 26-29. The Miscellaneous Technical block of Unicode

26.3.23 Optical Character Recognition
The Optical Character Recognition (OCR) block shown in Figure 26-30 includes the OCR-A characters that are not already encoded as ASCII and magnetic-ink character-recognition symbols used on checks.
Figure 26-30. The Optical Character Recognition block of Unicode

26.3.24 Geometric Shapes
The Geometric Shapes block combines simple triangles, squares, circles, and other shapes found in various characters sets Unicode attempts to superset. See Figure 26-31.
Figure 26-31. The Geometric Shapes block of Unicode
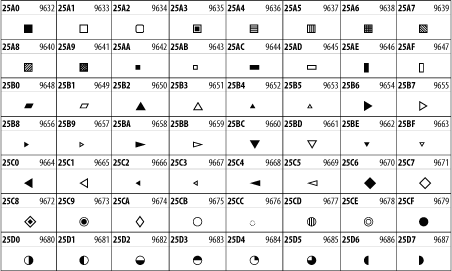
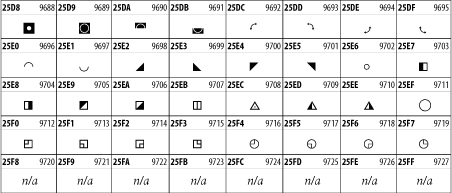
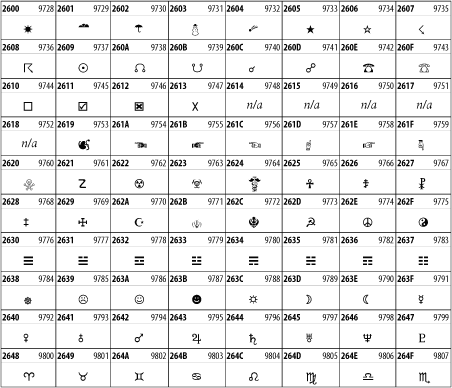
26.3.25 Miscellaneous Symbols
The Miscellaneous Symbols block contains mostly pictographic symbols found in vendor and national character sets that preceded Unicode. See Figure 26-32.
Figure 26-32. The Miscellaneous Symbols block of Unicode
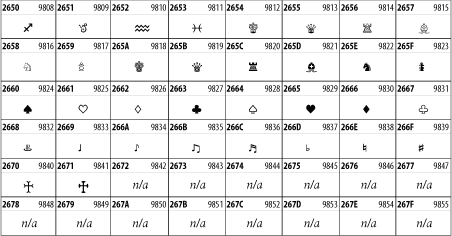
26.3.26 Dingbats
The Dingbats block shown in Figure 26-33 is based on characters in the popular Adobe Zapf Dingbats font.
Figure 26-33. The Dingbats block of Unicode
| CONTENTS |
EAN: 2147483647
Pages: 28