Design Considerations for Legacy Integration
There's a plethora of legacy systems in data centers around the globe. Some of these are old workhorses, and some of these are the more recent and sophisticated systems such as Portal Infranet, Seibel, and SAP. Obviously, I can't discuss all of them ”that would entail a series of books! However, what I'll cover are some of the more common approaches being used globally to interface nonproprietary systems to WebSphere.
| Note | When I say nonproprietary , I'm referring to systems that are custom developed. |
Generally , the most common way to interface WebSphere-based J2EE applications is via the Java Message Service (JMS). However, Extensible Markup Language (XML) via Simple Object Access Protocol (SOAP) is fast becoming a more distributed flavor of legacy integration over that of JMS.
Essentially , you could use JMS for short hop communications ”such as Local Area Network (LAN) or high-speed Wide Area Network (WAN) ”or where the legacy system can talk via JMS. You'll find that many legacy systems are starting to appear with Web Service engines so that you can communicate with them via XML over SOAP ”or XML Remote Procedure Call (XML RPC), the open -source flavor.
As you've seen throughout the book, Web Services are a growing yet immature technology. I have no doubt that Web Services will eventually provide foundational intersystem communications; however, while it's still an emerging technology with many of the core stack and standards yet to be ratified, you should be cognizant of other, possibly equally sound, distributed computing communications technologies.
JMS can use MQ Series from IBM that provides the low-level queue communications. You can use this form of communication internally to your application or for true legacy systems interconnection. Essentially what you want is system and application interoperability and its continuous evolvement. It'd appear that as each new interconnection technology matures and comes onto the market, critics find holes and limitations in it and move on to design another technology.
I'm a firm believer in the mantra of "Use the best tool for the job." If you find that plain-old socket communication is sufficient for your needs, then why implement something complex such as CORBA? Don't be afraid to use anything that fits the job well ”the only caveat is to be sure that whatever technology you use, you consider future scalability and capability needs. Don't lock yourself into something limited that you'll only throw out later.
You'll now look at the more common legacy systems interconnection methods .
CORBA Integration
CORBA 1.0 was released in 1990 and is one of the most powerful and popular distributed communications architectures available. Inherently used in online systems operating C++ and Java runtimes , it can also be used in non-object-oriented technologies such as COBOL and C. CORBA provides a non-language- affiliated distributing computing architecture that gives it its distributed computing flexibility.
Unlike Java Remote Method Invocation (RMI) ”which is used for Enterprise JavaBean (EJB) communications, among other things ”CORBA is truly platform and language independent.
CORBA operates using an application protocol known as Internet Inter Orb Protocol (IIOP) as its primary application protocol. The power and flexibility of CORBA are further realized because variations of CORBA can communicate over protocols that aren't based on Transmission Control Protocol/Internet Protocol (TCP/IP) such as Asynchronous Transfer Mode (ATM). Overall, CORBA allows disparate systems to communicate with one another using myriad protocols and communications technologies.
Because CORBA is language independent, it also enables you to communicate between different systems running different runtime bases. Integrating CORBA into your application environment isn't hard. In fact, many subsystems of WebSphere use CORBA-like communications and communicate using IIOP.
| Note | There's a difference between RMI-IIOP and IIOP in Java-speak. RMI-IIOP is where RMI communications are handled over IIOP instead of plain RMI. IIOP by itself is typically associated with pure CORBA communications. |
Figure 12-2 shows how a CORBA implementation may look within a WebSphere platform.
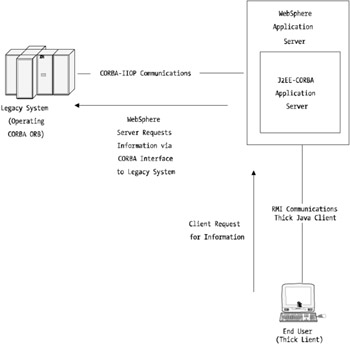
Figure 12-2: Example CORBA and WebSphere implementation
This figure shows a basic WebSphere implementation operating a CORBA interface to a legacy system. The legacy system in this example could be literally any form of host ”mainframe, Unix, Windows, or something in-between.
A classic example of this type of implementation is where an object-oriented CORBA implementation may have been implemented some years back before Java really gained enterprise acceptance. In this case, it may have been more cost efficient to leave the existing legacy system where it was and simply interface with it using a CORBA interface from the WebSphere platform. What's important to note is where WebSphere starts to communicate with the CORBA legacy system.
Consider that your J2EE-based application server needs to be well designed because inbound communications will be RMI/RMI-IIOP and outbound requests will be pure IIOP. Both these protocols utilize the centralized Object Request Broker (ORB).
The ORB is essentially the listening server for these types of distributed communications. In CORBA, the ORB is the distributed server. In J2EE, the ORB provides the same concept of technology except there's less reliance on it for RMI-IIOP communications because the RMI layer is more tightly integrated at the Java Virtual Machine (JVM) level via the appropriate Java classes.
You now look at Figure 12-2 at another layer down. Figure 12-3 shows an example transaction taking place from a request from a client (via RMI), which in turn triggers a request to the legacy CORBA system via IIOP.
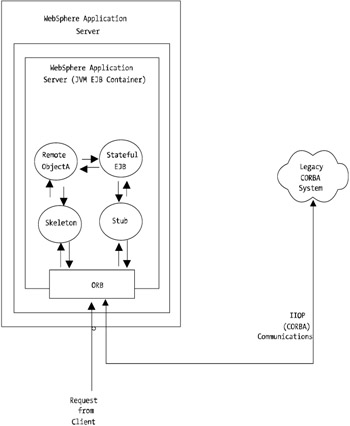
Figure 12-3: Example CORBA and WebSphere transaction
In a situation such as the one presented in Figure 12-3 where you may have a single application server servicing the requests, it may be advantageous to compartmentalize your components and ensure that your developers or application architects are splitting the Java RMI and CORBA components . Having both contained within a singular application server, under load, could introduce performance problems because the ORB needs to service requests for both the RMI communications and the IIOP/CORBA communications.
For each transaction, you're effectively doubling your threading overhead. Of course, you can contain all this within a singular application server if you want to avoid having to communicate to another EJB container within another application server. Using local transactions within WebSphere does decrease your RMI call overhead (except network calls, all calls to remote objects are referenced internally to the same application server).
| Note | Be aware that local transactions aren't J2EE compliant. By default your WebSphere application server will have local transactions disabled. |
If you need to have all the components within a shared application server, be sure to model and tune the number of threads allocated to the ORB. You'll find that you may quickly run out of threads within your ORB if you haven't modeled this correctly.
Again, my recommendation is to compartmentalize your components. It's better to take a small hit on overhead for the network RMI calls between application servers than it is to keep your CORBA components within the same application server. This provides a best practice approach at compartmentalizing your components ”creating somewhat of an abstraction layer.
Like RMI/RMI-IIOP communications, CORBA communications can become network intensive if there's a high transaction rate occurring. Ensure that your network sizing has adequately accounted for your CORBA overheads, especially if you're trying to route IIOP traffic through firewalls. Because the IIOP payloads (as opposed to the IP packets) contain information about source and destination ORB servers, IIOP can wreak havoc with Network Address Translation (NAT) and similar forms of firewall routing.
In fact, nowadays, it's possible to tunnel and encapsulate many application protocols such as IIOP within more simplistic network technologies such as Hypertext Transfer Protocol (HTTP). In addition, many products provide CORBA proxy servers. These aid security devices as well as route CORBA traffic from public to private or between nonvisible subnets without the pain of double-NAT firewalls and so on.
Always ensure that there are enough network ports and sockets available on both the client and server side of the transaction loop. Also, consider using connection pools for your communications to help alleviate the overhead of starting up and shutting down IIOP communications. Avoid having a new IIOP connection established for each client connection because this will quickly saturate the CORBA server's (and possibly your client's) TCP network services.
Generally, if you're in a position to influence the architecture of the application and your traffic needs to go via a firewall, consider some form of proxy so that you don't have to deal with the complexities of IIOP through firewalls. This may be either one of the aforementioned CORBA proxy server products or a secondary WebSphere application server tier that communicates with the primary WebSphere application server tier via some other protocol that's more firewall friendly (for example, SOAP, sockets/RPC, or RMI).
MQ Series Integration
MQ Series is a powerful host for a multihost architecture used for distributing computing. As discussed earlier during the chapter, MQ Series was originally developed by IBM to allow its host-based systems to be able to communicate with one another.
MQ also inherently provided an implementation that allowed disparate platforms to be able to communicate with a degree of service quality and robustness. The basic architecture behind MQ Series is that it's a message-based (listen and publish/subscribe) architecture. Communications between systems is conducted via an asynchronous queue system. Hosts place messages onto specific queues that are either subscribed or listened to by other systems. Listening servers monitor the configured queues for messages addressed appropriately.
Once a message has been received on a queue, the receiving MQ client or server acts on the message contents like any other form of distributed communications.
Unlike most other forms of distributing communications, MQ Series is an asynchronous architecture. Messages are placed onto queues by clients . After placing a message onto a queue, the client listens for a resulting message on the queue.
The development paradigm is slightly different from most other architectures, so developers need to change the way in which they think about sending and receiving data within their applications.
As an example, the following pseudo-code is an example of how this may be implemented:
Public static ActivateQueue(); { While true { NewMessage = getMesssage(); PutMessageOnQueue(hostname, queue name, newMessage); MQResult = ListenToQueue(transactionID); } // do something with queue results } public static PutMessageOnQueue(string, string, string); { transactionID = SendMessagetoQueue(message); return transactionID; } public static ListenToQueue(int); { while true { // mq code to listen to queue rsults sleep 5; } return result; } Ignoring the syntax, the basic flow of this code should provide an example of one way to implement MQ asynchronous transactions. There are many ways you can do this; this merely provides an example.
The need for thread-aware application design with MQ transactions is obvious. Because you have no result guarantee and there may be a need to resend the put message onto the queue if a timeout has been reached, the application will need to retry the request. If threading isn't implemented correctly in an environment where the returned MQ data is large or the remote system (MQ Server) is under load, the MQ transaction could take some time to complete.
Generally, using the MQ series will mostly be limited to mainframe or similar legacy host systems. There are other platform distributed architectures available that suit online systems better; however, with MQ, you'll be typically talking to batch-based systems.
The whole architecture of a batch-based system is typically asynchronous. The distributed communications as well as the internal system processing scheduler operate using a queue architecture. Therefore, you need to consider these factors.
With no real control over when results of queries will be returned, you face an interesting model with which to work. Although MQ architecture is out of the scope of this book, it's important you understand it at a high level. In Figure 12-4, there's a five-stage process where a client request initiates an MQ call to a host-based server. Step 2, as depicted in the figure, places a query onto the query queue. The listening-based host server picks up the addressed message and commences processing (step 3).
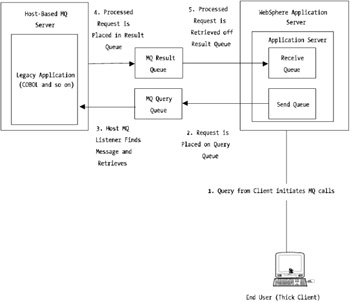
Figure 12-4: MQ Series communications with WebSphere
The result of the query is placed on another queue, which in this example is called the result queue (step 4). The calling J2EE-based application then in turn is also listening on the result queue for the query result (step 5). The result is obtained and processed accordingly within the J2EE-based WebSphere application. Although this is a simplistic view of how the technology works, it should provide you with an idea of the transaction flow.
I recommend that if you're requiring communication with an MQ-enabled legacy host system, consider using WebSphere/J2EE based on JMS for more simple environments. I'll discuss this later in the chapter, but JMS provides a cleaner and more robust way of communicating to an MQ-enabled host system.
However, there are factors you need to consider when using JMS if you're looking for high-availability configurations. I discussed this in more detail in Chapter 8. If you're bound to communicate using native MQ Series components without the advanced features such as MQ queue managers for high availability and clustering, consider the following:
-
Have a low-latency network architecture: Having a low-latency network environment helps with the performance of the messaging-type architecture of MQ Series. If you need a wide area or highly distributed messaging mechanism, consider using Web Services with MQ. I'll discuss this in later sections.
-
Design your MQ queries tightly: Don't overload your MQ Series host systems. Chances are that it'll be more costly to upgrade these legacy systems than it is for Unix or Wintel environments. Make an effort to ensure that your developers only obtain the data they need in queries rather than getting everything back in a query and filtering it.
-
Consider preemptive MQ queries: Given the asynchronous nature of MQ Series, the nature of the put and receive messages can introduce unwanted delays in your customers and users sessions. Consider prefetching data you think you may require during the user 's session from the legacy MQ host to save delays.
-
Be aware of thread exhaustion with pending MQ results: Because your applications may be waiting around for results back from MQ hosts, be sure that your WebSphere-based applications don't starve the thread pool of available threads.
Always ensure that your MQ-based applications are using connection pools. It's important to use these pooled connections to help with the performance of both the remote MQ host as well as the local WebSphere-based application server. Code examples for this are provided and discussed in Chapter 11.
Web Services Integration
Web Services are a quickly maturing distributed computing paradigm that provide an efficient and platform agnostic communications approach. Web Services provide a truly decoupled distributing computing architecture. Previous distributing architectures are well suited to specific same-host-to-same-host paradigms ; however, through typical Information Technology (IT) industry perseverance , people have extended those architectures to fit their needs rather than developing something from scratch that's truly distributable.
For example, CORBA, although good for distributed communications for the specific host types that it's available on, does fall short for complex environments where firewalls and or WANs are involved. It's what I call a heavyweight application protocol. The costs of communication startup and message transformation are quite high compared to that of something such as Web Services.
Web services will, more and more, become the way that distributed, disparate, legacy, and J2EE-based applications will communicate. Unlike previous distributing computing paradigms, Web Services are a model that follows a dynamic, loosely coupled application communications architecture, based on services rather than implementation type.
That is, with Web Services, you interface to the service you want to use. This is different from other distributing computing architectures because you implement the interface once with a Web Service provider and, via that singular interface, can instantiate any exposed data into objects. There's no need to create separate interfaces for separate object or query types.
Web Services typically use SOAP. Usually, SOAP operates over the standard HTTP or HTTPS port, which makes it easy to "massage" through a corporate firewall. Figure 12-5 provides a high-level diagram of how Web Services integrate within WebSphere.
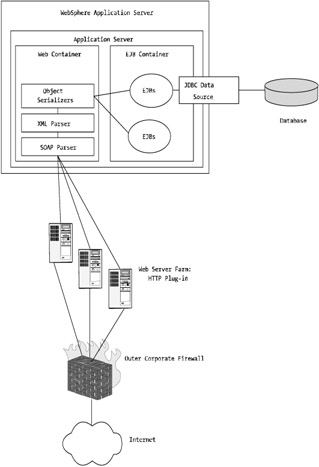
Figure 12-5: Web Service communications with WebSphere
Figure 12-5 highlights how Web Services may be implemented within a WebSphere application server. As you can see, the main area for integration is a Web container, and as such, you can apply many of the rules and recommendations covered in Chapter 7 to Web Services.
In fact, Web Services, from the point of view of the systems or WebSphere architect, isn't that different from any other form of Java Server Page (JSP) or servlet communications. Although the actual logic that handled much of the Web Service communication is different, the same fundamental WebSphere processes and engine dynamics are being used in the same way that JSPs and servlets are using them.
However, again, like the previous legacy distributed application architectures discussed in this chapter, the full architectural overview of Web Services is beyond the scope of this book. The purpose here is to discuss Web Services from a performance implementation perspective.
I'll discuss Web Services based on a HTTP Web Service stack:
-
Web Service directory ”Universal, Description, Discovery, and Integration (UDDI)
-
Web Services description ”Web Services Description Language (WSDL)
-
XML-based messaging ”SOAP
-
Network ”HTTP
The following are some Web Service performance and scalability tips:
-
Try to use standard SOAP data types: Using remote data types, for example, will decrease performance and scalability of your WebSphere application using Web Services.
-
Consider whether you need XML validation: WebSphere application server performance can be increased with XML validation turned off.
-
If using WSDL, consider caching this document type: Reduces reread frequency during a Web Service transaction and increases overall application performance.
-
Use internal rather than external schema sites: Improves application performance.
You'll now look at each of those items in more detail.
Using Standard SOAP Data Types
SOAP provides several simple data types for use in SOAP envelopes:
-
Int (Integer)
-
NegativeInteger
-
String
-
Float
It's also possible to implement your own data types. For example, if you have a need to access a data type such as a binary format (for example, bitmap, image, raw data, and so on), you can reference an external or nonstandard data type by referencing a different xsd element type. For example:
<message name = "getImageCount"> <part name = "imageCount" type = "xsd:int "/> </message> <message name = "getImage"> <part name = "name" type = "xsd:string"/> <part name = "size" type = "xsd:int"/> <part name = "image" type = "xsd:http://www.myWebServiceSite.com/imageMapType"/> </message>
As you can see, in the last part directive, there's a data type of http://www. myWebServiceSite.com /imageMapType . This data type is obviously on an external site.
This introduces an element in your WebSphere environment that's probably out of your operational control. The server running that site may be slow, poorly managed, or not highly available. Also, the route path in-between your site and the remote site could be high latency or overloaded. Either way, this introduces a point of performance contention in your environment.
As much as possible, use the standard data types and only use external schema reference sites if required.
| Note | See the" Internet vs. External Schema Site" section for more information on this robust improvement approach. |
XML Validation
XML validation is another aspect of Web Services that can introduce overhead. When a remote application requests data from an exposed Web Service, the serving or calling application can validate the request and receive streams against the service's Document Type Definition (DTD). Although validation is a satisfactory step in providing an error-free application environment, if you know the data types that are being presented, you can usually pretty safely assume that the data being returned will always be of the type you're expecting.
I say this because, generally, the data being requested via the Web Service will be sourced from a database or some form of data store. In this case, the database and data store loading and retrieval is already mastered by a level of data validation. For example, if you created a relational schema for a database that had a data field named MyValue with the data type Integer(2) , you could safely assume that if you retrieved that data from that field, you'd get back an integer with two digits.
Therefore, if you're querying a Web Service from a system that you know, trust, or operate yourself, you could possibly do away with this level of data type validation.
Caching of WSDL
It's not uncommon to find this same problem cropping up with standard XML-based or EJB specification DTDs in Java code. Sometimes beans are provided from open-source sites or from packages provided by vendors that reference remote DTDs on external sites such as http:/ /java.sun.com .
This is great for managing changes to application components but awful for performance! You can find the same issue with the WSDL in Web Services. Quite often, WSDL definition files are located on the Web, especially if they're from public Web Service sites.
For high-volume environments, this isn't a good move. Quite similar to the next section's issue, the number-one rule in gaining performance for XML or Web Service environments is to build in some form of XML, DTD, or WSDL caching. I've seen cases where the WSDL is loaded into shared memory and available to all calling applications as well as loading the WSDL into a database and periodically synchronized with the live or Internet-based WSDL template. In the case of the in-memory WSDL concept, a relatively straightforward caching mechanism could read the schema into memory during the application server's bootstrap, and all WSDL lookups could be performed from there.
It's possible to even use the Java Naming and Directory (JNDI) tree to store information such as this. Given that JNDI is distributed between clustered or workload-management-aware WebSphere servers, it provides a straightforward way of exposing this type of data to your Web Service server applications.
The bottom line is this: You want to minimize the end-to-end transaction time for your application server's transactions. By bringing in the WSDL to be local, you reduce the chance of your WebSphere-based application performing badly because of Internet performance or the potential poor performance of the site hosting the remote WSDL template.
Internet vs. External Schema Sites
Similar to the previous recommendation, hosting DTD schemas on remote sites isn't a good solution for a high-performance, high-volume application. Because there's usually a lot of latency between Wide Area Internetworks, the end-to-end transaction time for your customers or users making Web Services calls can vary widely. By using remote, organization-managed components, you're compromising your overall environment from either a security or stability point of view.
Although it'd be hard for it to occur, if a site housing a remotely exposed XML schema was compromised and the XML schema modified, it could easily cause problems with your Web Service transactions if the robustness of the remote system development and testing or even security methodologies were questionable. You don't want to spend countless hours and who knows how many millions of dollars on a high-availability infrastructure and have it completely degraded by components that are out of your sphere of influence.
My recommendation is that all remotely provided XML, WSDL, and other DTD schemas and templates are mirrored locally and are checked through some form of manual validation or automated checking tool. Your application should only reference a copy-managed instance of those schemas locally to your WebSphere environment, and, through a synchronization validation process, you should only introduce the updated schemas once testing and self-validation have taken place.
This flies in the face of one of the key ideals behind Web Services in that exposed services are on the Internet to be used. However, until Web Services become more mature and tighter controls are implemented, my recommendation is that you don't risk your site's integrity. House locally, and validate any changes.
As the Web Service stack becomes more mature, sites will start to expose business data. Without mature security, transaction support, and service quality, Web Services currently shouldn't be used "out of the box." One option to get around this current standards and stack limitation is to consider implementing a homegrown XML parsing-based implementation with homegrown security (in other words, authorization and authentication) such as XML-RPC, with SSL-based Web Servers if you're exposing content.
Batch Components and External Applications
Many components within a WebSphere environment, both locally and on remote legacy systems, may not be all that clever in terms of distributed computing but may in fact be simply batch-based tools operating behind the scenes. This includes things such as native Java code, Perl applications, C applications, and even shell scripts. You'll now look at some of the more common forms of batch components and some considerations for ensuring performance.
Many systems implement system-level batch scripts. In Unix, this is typically shell scripts (for example, sh , bash , zsh , csh , ksh , and so on), and for Windows systems, this is DOS batch scripts. These types of scripts are used predominately for simple tasks that just don't warrant their own full-blown application and may typically consist of many other smaller applications.
Mostly, these scripts are called via the exec () method in Java where it's important for the developers to handle the exit codes of those scripts carefully . In the following sections, you'll see some important considerations for running batch scripts and external applications within your WebSphere application environment.
Make Your Scripts Thread-Safe
If you have a J2EE-based application that's fairly dependant on a script such as one of the aforementioned Unix shell or batch scripts, consider placing it in another thread and compartmentalizing it from the rest of the running Java applications. Because these scripts tend to be dangerous and can quite easily bring down an entire system with an incorrect command or entry, you want to be sure that the Java application code can handle errors and critical failures of these scripts.
Compartmentalize Your Scripts
Remember also that these types of scripts run close to the operating system, similar to that of the JVM from within they're called. Therefore, because the script isn't insulated or managed by the container or a JVM, it has the potential to do damage to your system's performance.
Manage the Operating Priority
Consider running your scripts with a lower operating system priority (in Unix) to ensure that you don't have runaway processes. This will eliminate the possibility of a single process consuming too much Central Processing Unit (CPU) power.
Consider Having a Script Manager Factory
If you have 1,000 users online, with all sessions kicking off a particular script, you'll have that many scripts running within the operating system. Imagine the Input/Output (I/O) overhead if you were running a find command for a particular file from all 1,000 scripts! Your WebSphere performance would quickly turn to mush.
Additionally, if your script location (or the script itself) is exposed to users, it won't take long for some unwanted hacker to "Trojan horse" that script for something else. Never (ever!) expose your operating system directly to the end users. Whether it's intranet or Internet based, if you do need to run scripts as part of your application, always implement a script factory to place a layer of abstraction between your present runtime and your operating system.
If you have to run something such as this within your WebSphere environment, consider a manager class of some sorts that executes these scripts and monitors how many are active at any one time. This type of JavaBean would could be set to only maintain or allow the concurrent execution of "x" many scripts at any one time or only kick off more scripts if the overall system load is less than, let's say, 40 percent. The same class would be responsible for passing results back and forth to the calling objects.
This approach ensures that there's some element of management and control of these scripts. Although it's not perfect, it does provide a reasonable level of operational integrity.
Don't Use All Your Memory!
If you have 8 gigabytes (GB) of memory in your WebSphere server, and 6GB is already consumed by operating system processes and WebSphere components, you want to make sure that whatever scripts you're kicking off don't exceed 2GB ”the available memory left in the server! Doing so will force processes such as JVMs to start using swap memory, which will bring the system's performance to a halt.
Perl is a good example where you may need to do large file manipulation. Perl developers typically have to read the file into memory to be able to manipulate it back and forth, and therefore, the amount of memory consumed by the Perl processes will be the sum of the file plus the Perl runtime and some additional overhead.
Don't Use Java Native Interface (JNI)
Unless you have a specific or architecturally sound reason to do so (and this goes for all batch components), don't use Java Native Interface (JNI). JNI on its own is a sound piece of Java technology; however, it breaks the EJB specification when used from within an EJB container and can lead to many problems that the JVM can't handle.
Fatal errors within a JNI-called application can easily cause a JVM to crash. Although WebSphere is configured by default to restart the JVM (the application server) after a crash, it means that while the restart it occurring, customers and users can't use the application. Or, if you're running multiple application servers, the performance of the overall system will be degraded.
For this reason, and as discussed in Chapter 6, consider operating any batch or external (non-customer- facing ) application components on separate tiers. This way, you can be confident that if you need to run these types of components, live customers won't be greatly affected if they fail and cause a JVM to crash.
Java Application Clients (JACs)
Java application clients are Java applications that you run from the command line. These are useful to be called from other non-Java applications (such as shell scripts) that may need to obtain data from a Java-based object repository.
For example, imagine you had a shell script that needed to create directories for log files but the name of those directories were based on unique ID numbers that were created and mastered by a J2EE-based application. By using a JAC, you're able to load specific WebSphere and J2EE-based Java Archives (JARs) and access WebSphere running applications.
In this example, you could operate a Java Application Client (JAC) that obtained the Java Database Connectivity (JDBC) data source context from an operating WebSphere environment, then run a query against the database via the JDBC connection pool, and return the result. Of course, it's probably easier to run a direct JDBC connection from the JAC and bypass the WebSphere JNDI context lookups, but the example suits this discussion!
JACs run in their own JVM. As such, the JAC is constrained by the same attributes as normal Java and J2EE applications are ”that is, by JVM heap and various other profiling settings.
It's important that if you're running many JACs in your application environment, you don't have each of them firing up with a large amount of Java heap space. As you can appreciate, if your application architecture saw that you had a JAC launch on a regular basis with Java heap allocation sizes of the initial being 128 megabytes (MB) and the maximum being 384MB, it'd only take a handful of active JACs to consume all available memory!
The key here is to ensure the following:
-
Ensure that proper modeling of memory heap allocations are performed. In my experience, JACs don't typically need much more than an initial heap of 16MB to 32MB and a maximum heap of 32MB to 64MB. Occasionally, greater memory will be required, but in this case, set the initial to always be something low such as 16MB and the maximum to be what you think your maximum JAC memory requirements will be. Monitor this application code carefully to ensure that you don't have memory leaks.
-
Be sure that the JAC calling mechanism is controlled and tested . You don't want an error to occur within the calling mechanism that in turn goes into a loop and launches a new JAC every second.
-
Finally, test, test, test.
EAN: 2147483647
Pages: 111