6.2 Software Science Metrics
|
|
6.2 Software Science Metrics
Halstead was one of the pioneers in the field of software measurement. He is responsible for a set of metrics known as the Halstead software science metrics. These metrics can be divided into two distinct sets: primitive metrics and derived metrics. He observed that a compiler could parse program tokens into the two sets of operators and operands. Complicated algorithms could be seen to require more operators and operands than more straightforward algorithms. Hence, the count of operators and operands was quite relevant to the underlying complexity of the program. The Halstead primitives discussed in Chapter 5 are:
-
η1 is the cardinality of the set of operator tokens in a program module.
-
η2 is the cardinality of the set of operand tokens in a program module.
-
N1 is the cardinality of the bag of operator tokens in a program module.
-
N2 is the cardinality of the bag of operand tokens in a program module.
These basic metrics are of real value in understanding the complexity of a program. They are really related to software quality criterion measures. We can learn a lot from them. Now the fun really begins and the science ends.
Halstead set about to extract more information from the basic set of metric primitives that he derived from the program tokens, beginning with the follow two new metrics:
-
η = η1 + η2 is defined as the vocabulary of the program.
-
N = N1 + N2 is defined as the implementation length of the program.
Here, common sense should prevail. If you knew that there are 5000 undergraduates and 1000 graduate students at State University, it would be completely redundant to say that there are 6000 students at State University. There is no new information in their sum. By the same reasoning, there is simply no information in the vocabulary or length of a program. No new sources of variation have been added to these new metrics. We can learn nothing new from their sum.
When all else fails, it is a tradition in the discipline of computer science to take the log to the base two of a value. This will surely create new information content. Observe the following:
-
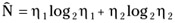 is the calculated length of the program.
is the calculated length of the program. -
V = N log2 η is the volume of the program.
Again, there are no new sources of variation being evaluated, nor did we learn anything new. Principal component analysis will show us that ![]() and V always vary in the same manner as the metric primitives.
and V always vary in the same manner as the metric primitives.
Now it gets really interesting. Two new potential sources of variation enter the problem space. These are:
-
η1*, the minimum number of unique or distinct operators for the algorithm being implemented
-
η2*, the minimum number of unique or distinct operands for the algorithm being implemented
It would appear that we are plowing new ground here. Unfortunately, the new sources of variation introduced by η1* and η2* are probably noise. There are no real precise rules for measuring these attributes. They cannot be measured accurately or unambiguously. They will vary differently from the token primitives but not because they represent new information, only because there are measurement discrepancies in them. There are a host of derived metrics that are based on the new metrics of η1* and η2*. They are as follows:
-
V* = η* log2 η* is the potential volume of the program.
-
V** = (2 +η2* log2 η2*)log2(2 + η2*) is the boundary volume of the program.
-
L = V*/V is the program level of the implementation of a program.
-
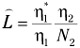 is an alternate representation for program level.
is an alternate representation for program level. -
D = 1/L is the difficulty in implementing a program.
-
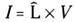 represents the intelligence content of the program.
represents the intelligence content of the program. -
E = V/L is the total number of elementary mental discriminations required to generate a given program. This is generally called Halstead's effort.
These metrics have proven very popular with software metricians over the years. This in itself is a very sad fact. There have been no efforts to validate these metrics. Had there been, they would never have seen the light of day.
Now we move rapidly into the area of pseudoscience. Once upon a time there was a man by the name of Stroud who published an obscure piece of research in an equally obscure journal of psychology. That article was Stroud's only real publication and was dutifully ignored by the psychology community. The work reported by Stroud was purely speculative and certainly not validated empirically. He thought that people could make about ten elementary mental discriminations per second. Unfortunately, we do not know what an elementary mental discrimination was, nor was Stroud able to convey this idea in his article. Halstead found this article in the psychological literature and incorporated Stroud's concept of elementary mental discriminations into his emerging software science metrics. This yields a new set of metrics as follows:
-
S is an arbitrary random variable such that 5 ≤ S ≤ 20 Stroud moments per second.
-
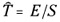 is the estimated implementation time for a program.
is the estimated implementation time for a program. -
λ = LV* is the language level of a program.
-
v is a count of the number of transfers of control flow both conditional and unconditional in a program.
-
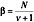 is the average block size.
is the average block size. -
E0 is the mean number of elementary discriminations between potential errors in programming.
-
B = E2/3/E0 is the number of delivered errors in a program.
-
M is the number of modules in a program.
-
Vm* = (η1* + η2*/M)log2(η1* + η2*/M) is the individual potential volume of a program module.
-
VM* = MVm* + M log2 M is the combined potential volume of a fully modularized program.
-
M = η2*/6 is the ideal number of modules in a program.
We have every reason to believe that Halstead had his heart in the right place but the overwhelming majority of these metrics are just not woven out of whole cloth. There are some real conceptual problems with those metrics that are associated with the Stroud number, S. [1], [2] Each of the Halstead metrics theoretically represents a unique program attribute. This being the case, there should be a distinct source of variance contributed by each of the metrics when we observe them at work measuring a program. This is simply not the case. The four primitive metrics of operator and operand count account for essentially the variation in all of the rest of the metrics.
[1]Coulter, N.S., Software Science and Cognitive Psychology, IEEE Transactions on Software Engineering, 9(2), 166–171, 1983.
[2]Munson, J.C. and Khoshgoftaar, T.M., The Dimensionality of Program Complexity, Proceedings of the 11th Annual International Conference on Software Engineering, IEEE Computer Society Press, Los Alamitos, CA, 1989, pp. 245–253.
|
|
EAN: 2147483647
Pages: 139