The Data Mining Process
| | ||
| | ||
| | ||
There are probably as many ways to approach data mining as there are data mining practitioners . Much like dimensional modeling, starting with the goal of adding business value leads to a clear series of steps that just make sense.
Youll be shocked to hear that our data mining process begins with an understanding of the business opportunities. Figure 10.3 shows the three major phases of the data mining process and the major task areas within those phases.
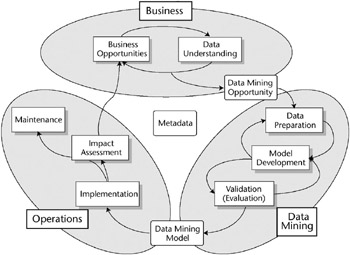
Figure 10.3: The data mining process
| |
We didnt invent this process; we just stumbled on it through trial and error. Others whove spent their careers entirely on data mining have arrived at similar approaches to data mining. Were fortunate that they have documented their processes in detail in their own publications . In particular, three sources have been valuable to us. The book Data Mining Techniques , 2nd Ed. by Michael J. A. Berry and Gordon S. Linoff (Wiley, 2004) describes a process Berry and Linoff call the Virtuous Cycle of Data Mining. Another, similar approach comes from a special interest group that was formed in the late 1990s to define a data mining process. The result was published as Cross Industry Standard Process for Data Mining (CRISP). Visit www.crisp-dm.org for more information. Also, the SQL Server Books Online topic The Data Mining Process presents a similar approach.
| |
Like most of the processes in the DW/BI system, the data mining process is iterative. The arrows that point back to previous processes in Figure 10.3 are the most common iteration points. There are additional iteration points; for instance, it is also common to return to the Business phase tasks based on what is learned in the Data Mining phase. In this section, we examine the three phases and their task areas in order, beginning with the Business phase.
The Business Phase
The business phase is a much more focused version of the overall requirements gathering process. The goal is to identify an opportunity, or a list of opportunities and their relative priorities, that can have a significant impact on the business. The Business Opportunities and Data Understanding tasks in Figure 10.3 connect to each other because the process of identifying opportunities must be bounded by the realities of the data world. By the same token, the data itself may suggest business opportunities.
Identifying Business Opportunities
As always, the most important step in successful business intelligence is not about technology; its about understanding the business. In data mining, this usually takes the form of a set of discussions between the business folks and the data miner about potential opportunities, and the associated relationships and behaviors that are captured in the data. The purpose of these meetings is to identify several high-value opportunities and think through each one carefully . First, identify the overall business value goal of the data mining project. It helps to describe this in as narrow and measurable a way as possible. A goal like increase sales is too broad. A goal like reduce the monthly churn rate is a bit more manageable. Next , think about what factors influence the goal. What might indicate that someone is likely to churn, or how can we tell if someone would be interested in a given product? While youre discussing these factors, try to translate them into specific attributes and behaviors that are known to exist in a usable, accessible form. The data miner may hold several of these meetings with different groups to identify a range of opportunities. At the end of these meetings, the data miner should work with the business folks to prioritize the various opportunities based on the estimated potential for business impact and the difficulty of implementation. These priorities will change as you learn more about the data, but this is an important starting point.
The data miner then takes the top-priority business opportunity and its associated list of potential variables back to the BI Studio for further exploration.
Understanding the Data
The data miner typically spends a significant amount of time exploring the various datasets that might be relevant to the business opportunities discussed. At this stage, the goal is to be reasonably confident that the data needed to support the business opportunity is available and clean enough to be usable. This exploration is generally not much more complex than the data exploration and data profiling that took place during the data modeling step in Chapter 2, and in designing the ETL process in Chapter 5. Any problems identified at this point should be noted so they can be included in the Data Mining Opportunity document.
Describing the Data Mining Opportunity
The data mining opportunity is a document that describes the top-priority opportunity discussed with the business folks. The opportunity description should include the following sections:
-
Business Opportunity Description
-
Expected Data Issues
-
Modeling Process Description
-
Implementation Plan
-
Maintenance Plan
Its important to document the opportunity, and have the business folks review it to make sure you understand their needs, and they understand how you intend to meet them. The data mining opportunity document is also a milestone in the data mining process. Once the data miner has a solid, clearly described, approved business opportunity, the data mining process enters the second phase: the data mining phase.
The Data Mining Phase
Once you understand the business opportunities and data structures, you can move into the data mining phase of the project. The data mining phase is where you build the data mining model. The data miner works through the tasks of preparing the data, developing alternative models, comparing their accuracy, and validating the final model. As Figure 10.3 shows, this is a highly iterative process. Data preparation feeds the model development task, which often identifies the need for further data preparation. By the same token, the process of validating a model commonly indicates the need for further improvements, which loops the data miner right back to the model development task, and potentially back to data preparation. In some cases, when serious problems arise, the loop goes all the way back to the business opportunity step. We ignore all this iteration in our description and move sequentially through the tasks.
Data Preparation
The first task in the data mining phase is to build the data mining case sets. Recall that a case set includes one row per instance or event. For many data mining models, this means a dataset with one row per customer. Models based on simple customer attributes, like gender and marital status, work at the one-row-per-customer level. Models that include behaviors like purchasing work at the one-row-per-event level. A case set for customer purchases would have one row for each product purchased by a customer. This is called a nested case set with two components the customer case set with one row per customer and all the applicable customer attributes, and the product case set, which includes the customer key and the products purchased by the given customer. Building the case set involves creating SQL scripts, MDX scripts, and/or Integration Services packages to clean and transform the data, and copy it into the datasets needed to support the model building process.
Cleansing and Transforming
Ideally, the variables in the case set are fully populated with only the appropriate values and no outliers or null values. The bulk of this book describes the incredible amount of work it takes to create that cleaned, conformed information infrastructure we call the data warehouse. This is why the data warehouse is the ideal source for data mining case data. In the easiest case, many of the variables identified in the business opportunity already exist as attributes in the data warehouse database. This is often true with fields like CustomerType, or ProductColor. The data miners world gets even better when demographics and other external data are already loaded as part of the standard ETL process. While these variables can be directly extracted, it is always a good idea to verify that basic data quality rules have been appropriately applied.
Unfortunately, directly selecting variables from the data warehouse database rarely provides us with a rich enough dataset to build a solid mining model. You may have to transform the data to make it more relevant to the business opportunity. This might include converting variables into more useful forms, like using standard discrete ranges for continuous variables if your industry has themaudience age range in television programming and advertising is a common discrete range. If no standard ranges exist, the data mining designer can be used to automatically discretize these variables based on different methods , like a histogram of the values, or an even distribution. This can also be done in a SQL statement using the CASE function. Some attributes might need multiple conversions, like birth date might be converted to age, which could then be converted to age range. There are several common conversions, like combining fields and discretizing.
Unfortunately, these descriptive variables are generally not enough for many mining models, even after they have been transformed into more relevant forms. The most influential variables in a data mining model are typically behavior-based, not descriptive. Behaviors are generally captured as facts. What did customers do, how often did they do it, how much did they do it, and when did they do it are basic behavior questions. For example, knowing which web pages someone has viewed , what products they bought, what services they used, what problems they complained about, when the last time they complained was, and how many complaints they had in the last two months can help you build a clear picture of the status of your relationship with that customer.
These behavioral variables are painstakingly extracted from the detailed fact tables as part of the data preparation process. The choice of which behavioral variables to create is based on the businesss understanding of behavior. Note that many of these behavior-based attributes require full table scans of the fact tables to create.
Integrating External Variables
Unfortunately, behavioral variables may still not be enough. Building an effective model often means bringing in additional data. These attributes, like demographics, come from various systems around the company or even from external sources. They will need to be merged together to make a single case set. When the source tables share a common key, this typically means joining them together to create a single row per case (usually per customer). However, it is not uncommon to have to map keys from the external source to the transaction systems natural keys, and then to the dimensions surrogate keys. In the worst case, the external data will not have a known key that ties to any field in the data warehouse database. When this happens, the relationship will need to be determined using matching tools. This is a tedious process, and its another argument for using Integration Services and its fuzzy matching task for data mining data preparation.
| Warning | Accurately tracking history is critical to successful data mining. If your DW/BI system or external sources overwrite changes in a Type 1 fashion, your model will be associating current attribute values with historical behavior. This is particularly dangerous when integrating external data that might have only current attribute values. See the section Slowly Changing Dimensions in Chapter 2 for an example of how this might create problems. |
Building the Case Sets
Build these datasets by defining data cleansing and transformation steps that build a data structure made up of individual observations or cases. Cases often contain repeating nested or child structures. These case sets are then fed into the data mining service. Its helpful to manage these tables independent of the data warehouse itself. Keep the data mining case sets in their own database, on their own server if necessary. The process of building the case sets is typically very similar to the regular ETL process. It usually involves a set of transformations and full table scans that actually generate a resulting dataset that gets loaded into the data mining database.
There are two main approaches to data preparation in the SQL Server 2005 environment. Folks who come from an SQL/relational background will be inclined to write SQL scripts, saving the results to separate case set tables that become inputs to the DM process.
| Note | Creating case sets can also be done through views if you are creative enough with your SQL. We dont recommend this because if underlying data changes (like when new rows are added), the mining model may change for no apparent reason. |
Folks who come from an ETL background will be more comfortable using Integration Services to merge, cleanse and prepare the data mining case sets. The Integration Services approach has some advantages in that there are many transformation components built into the Integration Services toolbox. Integration Services can also more easily pull data from external sources and in different formats and can be used to deposit the prepared case set wherever it is needed, in a variety of formats.
Depending on the business opportunity and the data mining algorithms employed, creating the initial datasets often involves creating separate subsets of the data for different purposes. Table 10.2 lists three common datasets used for data mining. The Percentage Sampling, Row Sampling, and Conditional Split tasks are particularly well suited to creating the training and test case sets. For example, use the Row Sampling transform to grab a random sample of 10,000 rows from a large dataset. Then use the Percentage Sampling transform to send 80 percent to the training set and 20 percent to the test set.
| SET | PURPOSE |
|---|---|
| Training | Used as input to the algorithm to develop the initial model. |
| Validation | Used to make sure the algorithm has created a model that is broadly applicable rather than tightly tied to the training set. (Used in certain circumstances only.) |
| Test | Data not included in the training setsoften called holdout data. Used to verify the accuracy or effectiveness of the model. |
Most of the models we describe use only the training and test datasets. Working with the validation set requires an additional degree of data mining expertise.
One last advantage of Integration Services is that it allows you to build a package or project that contains all of the steps needed to prepare data for a given data mining project. Put this Integration Services project under source control, and re-use it to create new datasets to keep the model current. In our opinion, Integration Services is the best choice for data mining data preparation. SQL plays a role in defining the initial extracts and some of the transformations, and will be part of any data preparation effort, but building the whole flow generally works best in Integration Services.
Model Development
The first step in developing the data mining model is to create the mining model structure in the BI Studio. The mining model structure is essentially a metadata layer that separates the data from the algorithms. The data mining wizard creates the initial mining model structure which can then be edited as needed.
Once the mining structure is defined, the data miner builds as many mining models and versions as time allows, trying different algorithms, parameters, and variables to see which one yields the greatest impact or is most accurate. Usually this involves going back and redefining the data preparation task to add new variables or change existing transformations. These iterations are where SQL Server Data Mining shines. The flexibility, ease of use, range of algorithms, and integration with the rest of the SQL Server toolset allows the data miner to run through more variations than many other data mining environments. Generally, the more variations tested , the better the final model.
Model Validation (Evaluation)
There are two kinds of model validation in data mining. The first involves comparing models created with different algorithms, parameters, and inputs to see which is most effective at predicting the target variable. The second is a business review of the proposed model to examine its contents and assess its value. We will examine both validation steps in this section.
Comparing Models
Creating the best data mining model is a process of triangulation. Attack the data with several algorithms like decision tree, neural net, and memory-based reasoning. Youd like to see several models point to similar results. This is especially helpful in those cases where the tool spits out an answer but doesnt provide an intuitive foundation for why the answer was chosen . Neural nets are notorious for this kind of result. Triangulation gives all the observers (especially end users and management) confidence that the predictions mean something.
Analysis Services Data Mining provides two common tools for comparing the effectiveness of certain types of data mining modelsa lift chart and a classification matrix. These can be found under the Mining Model Accuracy tab in the data mining designer. To use the Accuracy tab tools, first select the mining structure that supports the models you want to compare and join it to your test dataset. The lift chart works in a couple of different ways, depending on the models being compared. The basic idea is to run the test cases through all of the models, and compare the predicted results with the known actual results from the test dataset. The lift chart then plots the percentage of correct predictions for a given percentage of the overall test population, beginning with the most accurate portions of the model (the cases with the highest predicted probability). Figure 10.4 shows a lift chart that compares two simple models used to predict Income Range based on the other non-income demographics in the AdventureWorksDW Customer table.
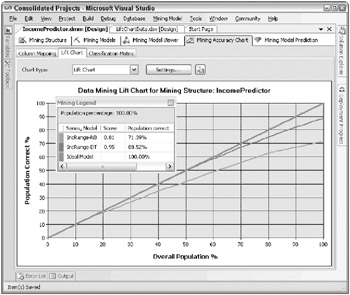
Figure 10.4: An example lift chart comparing two models designed to predict Income Range
The lines representing the two models are bounded by an upper limit that represents the best possible prediction. In the best case, the model would be 100 percent right for whatever percent of the population it processed . The best case is represented by the heavy, straight line between 0 and 100. The worst case would be a random guess. Because this model has only six possible values of predicted income ranges, a random guess would be right 16.67 percent of the time. The Decision Trees model called IncRange-DT is clearly more predictive than the Nave Bayes model called IncRange-NB. At the 100 percent point, the Decision Trees model accurately predicts 88.52 percent of the cases while the Nave Bayes predicts only 71.39 percent of the cases.
The second tool, called the classification matrix, is a matrix with the predicted values on the rows and the actual values on the columns . Ideally, youd like to see a single vector down the diagonal of the matrix with values, and the rest of the cells should be zeros. This would represent the outcome where all of the cases the model predicted to be in a certain Income Range actually were in that Income Range. Figure 10.5 shows the classification matrix for the same Decision Trees and Nave Bayes models.
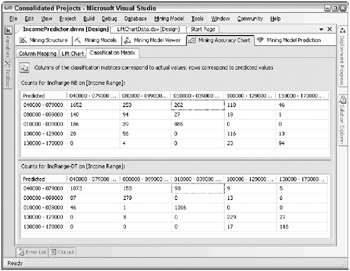
Figure 10.5: Example classification matrices for the Income Range models
In this example, the Nave Bayes model clearly is incorrect more often than the Decision Trees model. For example, for cases where the actual range is 10,000-39,000 (the third data column), the Nave Bayes model predicts an Income Range of 40,000-79,000 for 202 cases, while the Decision Trees model makes this error only 98 times.
Unfortunately, the Mining Model Accuracy tools work only for single-valued results in the initial release. They dont work for result lists, like recommendation lists. In those cases, you will need to build your own comparison tests using the Integration Services tasks to query the mining model with the test dataset and compare the results. We show an example of this in one of the case studies later in this chapter.
| Reference | For more information about using lift charts and classification matrices, see Validating Data Mining Models in SQL Server Books Online. |
Business Review
The data mining phase ends with the selection of the best model based on its performance in the model comparison process. Ultimately this is a business decision, so you need to review the contents and performance of the model with the business folks to make sure that it makes sense.
Prepare for this review by carefully combing through the selected model to understand and document the rules it uses, the relationships it defines, and the impact you expect it to have. The various tabs in the data mining designer are particularly helpful in developing this understanding. Present this documentation to the business users and carefully walk them through the logic behind the model. This presentation also includes evidence of the models performance from the Mining Accuracy Chart tab tools and other sources. This helps all participants understand the expected impact of the model. Once the business review is complete, the next step is to move the model out into the real world.
The Operations Phase
The Operations phase is where the rubber meets the road. At this point, you have the best possible model (given the time, data, and technology constraints) and you have business approval to proceed. Now you get to put it into production and see what kind of impact it has. The Operations phase involves three main tasks: implementation, impact assessment, and maintenance.
Implementation
After all participants have approved the final model and the implementation plan, the team can move the model into production in the implementation task. Production can range from using the model once a quarter to assess the effectiveness of various promotions, to classifying customers as part of the nightly ETL process, to interactively making product recommendations as part of the web server or customer care transaction system.
Each of these alternatives involves a different cast of characters . At one end of the spectrum, the quarterly update of the customer dimension may involve only the data miner and the ETL developer. At the other end of the spectrum, making online recommendations will clearly involve the production systems folks. And, depending on the transaction volume, they will likely want a production Analysis Services server (or cluster) dedicated to providing recommendations. Moving the data mining model into production also involves significant changes to the transaction system applications to incorporate the data mining query and results into the business process and user interface. This is usually a big deal. You must figure out who needs to be involved in the implementation task for your data mining model and let them know as early as possible, so they can help determine the appropriate timeframes and resources. Deploy in phases, starting with a test version, to make sure the data mining server doesnt gum up the transaction process.
Assess Impact
Determining the impact of the data mining model can be high art. In some areas, like direct mail, the process of tuning and testing the marketing offers and collateral and the target prospect lists is often full-time work for a large team. They do test and control sets with different versions of the mailing before they do the full mass mailing. Even in the full campaign, often several phases with different versions and control sets are built in. The results of each phase help the team tweak subsequent phases for best results.
In general, the data miner should adopt as much of this careful assessment process as possible.
Maintain the Model
Almost all data mining models will need to be re-trained, or to be completely rebuilt over some period of time. As the world changes, the behaviors that have been captured in the model become outdated . This is particularly noticeable in a fast-changing industry like retail where new fashions , products, and models are announced on a daily basis. A recommendation engine that didnt include the most recent behavior and latest models would be less than useful to the customer. In a case like this, the basic model structure may still apply, but the rules and relationships must be re-generated based on new behavior data.
Metadata
In the best of all possible worlds , the final data mining model should be documented with a detailed history of how it came into being. What sources contributed to the case set? What kinds of transformations were applied to the variables, and at what points in the process were they applied? What was the initial model and what were the intermediate versions considered and discarded? What parameter values were used for which versions of the model? A professional data miner will want to know exactly what went into creating a model in order to explain its value, to avoid repeating the same errors, and to re-create it if need be. The data miner should also keep track of how and when the model is used, and when it should be maintained .
The problem with tracking the history of a mining model is that because Analysis Services makes it so easy to create additional versions of the model, it takes much more time to document each iteration than it does to actually do the work. Nonetheless, you still need to keep track of what you have and where it came from. We recommend keeping a basic set of metadata to track the contents and derivation of all the transformed datasets and resulting mining models you decide to keep around. This can get much more complex if you like, but the simplest approach is to use a spreadsheet, as pictured in Figure 10.6.
| Data Mining Project Documentation Sheet | ||||||||
|---|---|---|---|---|---|---|---|---|
| Project Information | Data Preparation SSIS Package Information | |||||||
| Project Name : | Package Name: | |||||||
| Project Owner: | Package Location: | |||||||
| Business Contact: | Data Mining Server Name: | |||||||
| Start Date: | Data Mining Database Name: | |||||||
| Expiration Date: | ||||||||
| Project Description: | ||||||||
| Data Mining Data Sources | ||||||||
| Source Name | Type | Create step | Version | Version date | Xforms and changes | |||
|
| ||||||||
| Data Mining Structures | ||||||||
| Structure Name | Version | Version Date | Xforms and changes | |||||
|
| ||||||||
| Data Mining Models | ||||||||
| Model Name | Parent Structure | DM Algorithm | Version | Version date | Input Vars | Predict Vars | Parameter settings | Results |
|
| ||||||||
Figure 10.6: A simple spreadsheet for tracking data mining models
| |
The data mining process takes place across the various DW/BI system platforms and relies on their security mechanisms. The data miner needs to have enough privileges on the data source servers to create new tables and/or cubes. Additionally, to create and modify data mining models, the data miner must be a member of the Analysis Services Administrators group on the data mining computer.
| |
| | ||
| | ||
| | ||
EAN: N/A
Pages: 125