Defining Data Mining
| Data mining capability is not something you can buy off the shelf. Data mining requires building a BI decision-support application, specifically a data mining application, using a data mining tool. The data mining application can then use a sophisticated blend of classical and advanced components like artificial intelligence, pattern recognition, databases, traditional statistics, and graphics to present hidden relationships and patterns found in the organization's data pool. Data mining is the analysis of data with the intent to discover gems of hidden information in the vast quantity of data that has been captured in the normal course of running the business. Data mining is different from conventional statistical analysis, as indicated in Table 13.1. They both have strengths and weaknesses. Table 13.1. Statistical Analysis versus Data Mining
Tables 13.2 and 13.3 use specific examples (insurance fraud and market segmentation, respectively) to illustrate the differences between traditional analysis techniques and discovery-driven data mining. Table 13.2. Example of Insurance Fraud Analysis
Table 13.3. Example of Market Segmentation Analysis
The Importance of Data MiningDiscovery-driven data mining finds answers to questions that decision- makers do not know to ask. Because of this powerful capability, data mining is an important component of business intelligence. One may even say that data mining, also called knowledge discovery, is a breakthrough in providing business intelligence to strategic decision-makers. At first glance, this claim may seem excessive. After all, many current decision-support applications provide business intelligence and insights.
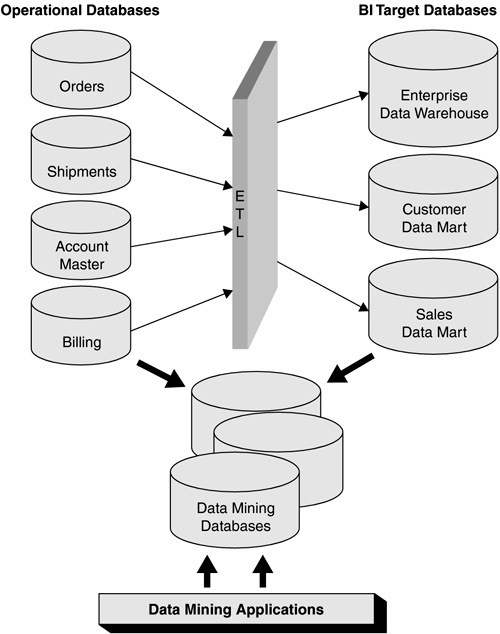
Many of these tools work with BI applications and can sift through vast amounts of data. Given this abundance of tools, what is so different about discovery-driven data mining? The big difference is that traditional analysis techniques, even sophisticated ones, rely on the analyst to know what to look for in the data. The analyst creates and runs queries based on some hypotheses and guesses about possible relationships, trends, and correlations thought to be present in the data. Similarly, the executive relies on the business views built into the EIS tool, which can examine only the factors the tool is programmed to review. As problems become more complex and involve more variables to analyze, these traditional analysis techniques can fall short. In contrast, discovery-driven data mining supports very subtle and complex investigations. Data Sources for Data MiningBI target databases are popular sources for data mining applications. They contain a wealth of internal data that was gathered and consolidated across business boundaries, validated , and cleansed in the extract/transform/load (ETL) process. BI target databases may also contain valuable external data, such as regulations, demographics , or geographic information. Combining external data with internal organizational data offers a splendid foundation for data mining. The drawback of multidimensional BI target databases is that since the data has been summarized, hidden data patterns, data relationships, and data associations are often no longer discernable from that data pool. For example, the data mining tool may not be able to perform the common data mining task of market basket analysis (also called associations discovery, described in the next section) based on summarized sales data because some detailed data pattern about each sale may have gotten lost in the summarization. Therefore, operational files and databases are also popular sources for data mining applications, especially because they contain transaction-level detailed data with a myriad of hidden data patterns, data relationships, and data associations.
Data mining tools could theoretically access the operational databases and BI target databases directly without building data mining databases first, as long as the database structures are supported by the tool (e.g., relational like Oracle, hierarchical like IMS, or even a flat file like VSAM). However, this is not an advisable practice for several reasons.
Therefore, organizations often extract data for data mining as needed from their BI target databases and from their operational files and databases into special-purpose data mining databases (Figure 13.1). Figure 13.1. Data Sources for Data Mining Applications |
EAN: 2147483647
Pages: 202