Differences in Database Design Philosophies
| There is a completely different design philosophy behind BI target databases as compared with operational databases. Table 8.1 summarizes the differences between these two types of databases. Operational DatabasesThe intent of operational database design is to prevent the storage of the same data attributes in multiple places and thus to avoid the update anomalies caused by redundancy. In other words, from an operational perspective you want to avoid storing the same data in multiple columns in multiple tables so they do not get out of synch. Designing normalized database structures is key for developing relational databases in support of that intent. Normalization ensures that the data is created, stored, and modified in a consistent, nonredundant way. Table 8.1. Operational Databases versus BI Target Databases
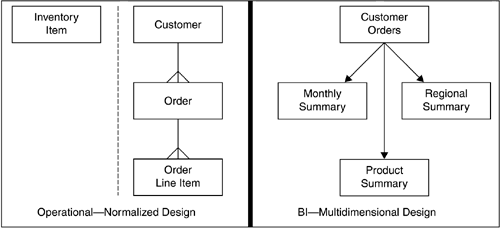
Most operational systems are designed with a data-in philosophy (data entry), not a data-out philosophy (reporting and querying). The objective of a data-in philosophy is to make data entry as efficient as possible, running hundreds of thousands of transactions per day, while eliminating or minimizing redundancies in the data. Data redundancy leads to inconsistencies, and inconsistencies are often the reason for poor-quality data. Therefore, in trying to solve the enormous data quality and data redundancy problems in operational systems, the goal is to avoid redundancy (except for key redundancy, which is unavoidable). This goal is achieved through normalization. While normalization works well for operational systems, the requirements for reporting are different from the requirements for data entry. Reporting uses data that has already been created, which means update anomalies cannot occur. While it is of great benefit that the data is consistent and nonredundant as a result of a normalized database design, that same design makes reporting difficult. For example, to create strategic trend analysis reports, many tables have to be accessed, and every row in those tables has to be read. This is not only complex but also extremely inefficient when run against a normalized database design because it requires scanning tables and performing large multi-table JOINs. For that reason, most BI target databases are based on a multidimensional design, in which the data for the strategic trend analysis reports is stored in a precalculated and presummarized way. Figure 8.1 illustrates the general difference between an operational normalized design and a BI multidimensional design. Figure 8.1. Operational normalized versus BI Multidimensional Designs In this example, the operational database design shows an Order database where customers are associated with orders, and each order is composed of many line items. With each placed order, the line items have to be subtracted from a separate Inventory database. The BI target database design shows a database with summaries that are used to identify trends over time. In this design, the same data about orders, line items, and inventory may exist in multiple tables (Monthly Summary, Regional Summary, Product Summary), albeit summarized by different dimensions. While operational databases generally store granular (atomic) data, BI target databases, for the most part, store summarized data. BI Target DatabasesContrary to the data-in philosophy (data entry) of operational systems, the data-out philosophy (reporting and querying) of BI applications includes the following design considerations.
A key decision for all BI applications is whether or not, and at what level, to store summarized data in the BI target databases. The database administrator and the lead developer may decide to store both detailed data and summarized data, either together in the same BI target database or in different BI target databases. This database design decision must be based on access and usage requirements. |
EAN: 2147483647
Pages: 202