5.1 Multithreaded and Multiprocess Designs
| Modern operating systems, and most embedded systems, support multiple processes or threads. A process is a standalone application that performs a particular purpose. A process can be as complicated as a word-processing package like Microsoft Word, or as simple as the following "Hello World" application: #include <iostream> int main () { std::cout << "Hello World" << std::endl; return 0; } Each process is insulated from all others, even in the case of multiple instances of the same application. As an application designer, you typically do not need to concern yourself with the details of what other applications or even what the operating system is doing. However, this does not imply that different processes cannot work in unison to perform a task. In this section, we explore how partitioning a problem into many separate pieces can create a solid design that helps decrease the development time and increase the robustness of your application. Unlike processes, threads are not insulated from each other. A process can consist of one or more threads that in many ways behave like separate processes. You can write a thread as though it exists by itself, but the operating system does not treat it this way. All threads in a process share the same memory space, which has both positive and negative effects. This means that the developer needs to decide when threads can and should be used to improve performance and reliability. Even if the operating system does not support threads natively, it is possible to use third-party packages to get this functionality. The techniques we discuss here are also applicable to embedded systems . The dynamics of embedded systems are different from those of full-blown operating systems, such as Microsoft Windows or the many UNIX variations. Most embedded systems are deterministic, meaning they have the ability to guarantee a certain response time or processing rate. They usually support processes and threads. Embedded systems often have a very simple user interface, or none at all. In addition, they often have limited memory and other resources. And, significantly, they are designed to run indefinitely without requiring rebooting. To use threads and processes successfully, you must be able to communicate between them, which is referred to as interprocess communication . Although the functionality differs among operating systems, we concern ourselves with the most important components :
In our discussion of these features, we focus on ways to improve reliability and decrease development time. We only use features if they offer a clear advantage for commercial software development. Consequently, we also talk about when these features should be avoided. 5.1.1 ThreadsThreads are one of the first elements to consider when designing an application. Many applications lend themselves well to this mechanism, and threads are widely available on most platforms. Still, we must consider whether or not to incorporate threads into a design. Debugging and correcting problems in a multithreaded application is usually more difficult than in a non-threaded application.
Full-blown operating systems, such as Microsoft Windows and many UNIX versions, offer a fully preemptive multithreaded environment . The operating system takes care of how and when each thread receives a slice of processing time. In other words, thread1() and thread2() can be written with very little knowledge about what the other thread function is doing. At the other end of the spectrum are cooperative multithreaded environments . In this environment, you must control when one thread stops and another thread runs. While this offers complete control over the switching from one thread to another, it also means that, if poorly written, one thread can consume 100% of the processor time. Cooperative multithreading is often found in small embedded systems or as third-party libraries for platforms that have no native multithreading. If you have the choice, use the preemptive model to ensure that deadlocks are minimized. A deadlock is a situation where no thread can continue executing, causing the system to effectively hang. Besides, you can always use thread priorities to make a preemptive multithreaded system behave like a cooperative system. On some systems, a high priority thread simply gets more processing time than lower priority threads. On other systems, a lower priority thread gets no processing time while a higher priority thread is running. The number of threading APIs has fortunately become much smaller in recent years . IEEE Standard 1003.1 (also known as POSIX) is available and defines a complete interface to thread functionality, including control and synchronization. The specification is available online (currently located at http://www.opengroup.org/onlinepubs/007904975/toc.htm). On most platforms with native thread support, a POSIX interface is available (on Win32 platforms, for example, a fairly complete interface can be found at http://sources.redhat.com/pthreads-win32). POSIX is complicated and somewhat intimidating. In keeping with our desire to keep things simple, we wrap the C interface in a simple class to handle our threading needs. If this simple interface is insufficient for your needs, you can extend it as necessary. We are not offering this sample as a class that can be used in all circumstances, but you may be surprised at how useful it is. We present two versions of this object: one for POSIX for UNIX platforms, and one for Win32 for Microsoft platforms. We keep our operating system-specific versions in different directories that are accessed by a top-level include file. The file hierarchy is: /include thread.h /win32 thread.h /unix thread.h The top-level version of thread.h loads the implementation-specific version of thread.h , or defines a default implementation of apThread . Although there is a pthreads compatibility library available on Microsoft Windows, we have chosen to use native Win32 calls because it is a simpler interface and is only going to be used in the Win32 environment. The Microsoft Win32 version of thread.h is as shown. class apThread { public: apThread () : threadid_ (-1) {} ~apThread () {if (threadid_ != -1) stop();} int threadid () const { return threadid_;} bool start () { threadid_ = _beginthreadex (NULL, 0, thread_, this, CREATE_SUSPENDED, (unsigned int*) &threadid_); if (threadid_ != 0) ResumeThread ((HANDLE)threadid_); return (threadid_ != 0); } // Start the thread running bool stop () { TerminateThread ((HANDLE) threadid_, -1); return true; } // Stop the thread bool wait (unsigned int seconds = 0) { DWORD wait = seconds * 1000; if (wait == 0) wait = INFINITE; DWORD status = WaitForSingleObject ((HANDLE) threadid_, wait); return (status != WAIT_TIMEOUT); } // Wait for thread to complete void sleep (unsigned int msec) { Sleep (msec);} // Sleep for the specified amount of time. protected: int threadid_; static unsigned int __stdcall thread_ (void* obj) { // Call the overriden thread function apThread* t = reinterpret_cast<apThread*>(obj); t->thread (); return 0; } virtual void thread () { _endthreadex (0); CloseHandle ((HANDLE) threadid_); } // Thread function, Override this in derived classes. }; Unlike previous examples where we define a base class and derive one or more implementations , only a single version of apThread is defined. If this file is included on a Win32 platform, the symbol WIN32 is defined, so that the class definition comes from win32/thread.h . On UNIX platforms that support pthreads, the makefile defines HasPTHREADS so that the file unix/thread.h is included. If neither is true, or the symbol AP_NOTHREADS is defined, the default implementation is used. If there was no default implementation, any objects derived from apThread will fail to compile. apThread is very easy to use. You can derive an object from apThread and then override the thread() member function. This function will execute when start() is called and continue executing until the application is finished, or the stop() method is called. The default implementation has the following behavior:
Obviously this is not the desired behavior, but without thread support you cannot expect the application to run properly. We originally thought about defining start() like this: bool start () { thread(); return true;} Doing so would cause nothing but trouble. If threading is not supported, the call to thread() will never complete, and hence start() will never return. It is much safer to just return false and hope the application fails gracefully.
The stop() method should be used very sparingly. Thread termination is very abrupt and can easily cause locking issues and other resource leakage. You should always provide a more graceful way to terminate your threads, such as using a flag to specify when a thread can safely shut down. The full UNIX and Win32 implementations can be found on the CD-ROM. Let's look at the start() and stop() methods for UNIX and Win32 implementations. The Microsoft Win32 API is as shown. bool start () { threadid_ = _beginthreadex (NULL, 0, thread_, this, CREATE_SUSPENDED, (unsigned int*) &threadid_); if (threadid_ != 0) ResumeThread ((HANDLE)threadid_); return (threadid_ != 0); } bool stop () { TerminateThread ((HANDLE) threadid_, -1); return true; } protected: int threadid_; static unsigned int __stdcall thread_ (void* obj) { apThread* t = reinterpret_cast<apThread*>(obj); t->thread (); return 0; } The pthreads implementation for UNIX is as shown. bool start () { int status; status = pthread_create (&threadid_, NULL, thread_, this); return (status == 0); } bool stop () { pthread_cancel (threadid_); return true; } protected: pthread_t threadid_; static void* thread_ (void* obj) { apThread* t = reinterpret_cast<apThread*>(obj); t->thread (); return 0; } With the implementation details hidden, let's look at a simple example: class thread1 : public apThread { void thread (); }; void thread1::thread () { for (int i=0; i<10; i++) { std::cout << threadid() << ": " << i << std::endl; sleep (100); } } int main() { thread1 thread1Inst, thread2Inst; thread1Inst.start (); thread2Inst.start (); thread1Inst.wait (); thread2Inst.wait (); return 0; } Two worker threads are created: each prints ten lines of output and then exits. Beyond that, it is difficult to predict what will actually be output. In addition, what will be output also depends upon the platform on which it runs. On Microsoft Windows, for example, the output is very orderly, as shown: 2020: 0 2024: 0 2020: 1 2024: 1 2020: 2 2024: 2 2020: 3 2024: 3 2020: 4 2024: 4 2020: 5 2024: 5 2020: 6 2024: 6 2020: 7 2024: 7 2020: 8 2024: 8 2020: 9 2024: 9 However, you can't rely upon the behavior of the operating system to control the output. For example, if sleep(100) is removed from the thread() definition, the output changes to be as shown: 2020: 0 2020: 1 2024: 0 2024: 1 2024: 2 2024: 3 20242020: 2 2020: 3 2020: 4 2020: 5 2020: 4 2024: 5 2024: 6 2024: 7 2024: 6 2020: 7 2020: 8 2020: 9 : 8 2024: 9 When the operating system decides to switch from one thread to another, it is usually after a thread has consumed a certain amount of processing time. This can happen any time, including in the middle of executing a line of code. If each thread was completely independent of the others, this would not be an issue. But even in our simple example, both threads use a common resource: they both generate output to the console. This example highlights the primary challenge when using threads. It is imperative that access to shared resources be carefully controlled. A shared resource can be more than just an input/output stream or file. It might be something as simple as a global variable that can be accessed by many threads. As the number of threads increases, the complexity of managing them increases as well. You might wonder why we always seem to encapsulate a functionality like threads into its own class. After all, if your application only ever runs on a single platform, you might consider using the native API calls directly. But encapsulation does serve another important purpose. In addition to ensuring that all users of our thread object get the same behavior, encapsulation allows us to use our debugging resources to observe what is happening. Most thread problems occur with missing or incorrect synchronization, an issue we will talk about shortly. But another common problem occurs when the thread itself goes out of scope and closes . Consider this example: class thread: public apThread { void thread () { while (true) { ... } } }; int main() { thread thread1; thread1.start (); { thread thread2; thread2.start (); } ... } thread2 goes out of scope when the closing brace is reached, causing the thread to stop running. Before you say that you would never write code like this, you need to realize how easy it is to write code that results in such behavior. For example:
One solution to the scoping problem is to allocate apThread objects on the heap with operator new . While you can be very careful not to delete heap-based objects prematurely, remembering to delete them at all is another matter. It is not uncommon for bad coding practices like this to surface in multithreaded code. Single-threaded applications often rely on the operating system to cleanly shut down an application, and therefore this issue is ignored. These practices do not work with multithreaded applications unless the lifetime of all threads is the same as that of the application itself. This demonstrates yet another benefit of encapsulating a thread in apThread . Your apThread -derived object can control the object lifetime of other components that exist only to serve a thread. Although you can do this inside the constructor and destructor of your derived object, we recommend overriding start() and stop() and taking care of it there. Doing so in these functions delays the construction and destruction of other components until they are needed, rather than when the apThread object is constructed . We recommend that Singleton objects be used for threads that persist for the entire lifetime of an application. Construction happens when the object is first referenced, presumably when the application begins execution.
Let's look at the following example: class thread: public apThread { public: static thread& gOnly(); void thread (); private: static thread* sOnly_; thread (); }; When the application starts: thread::gOnly().start (); it causes the thread to be constructed and begin execution. Applications that use threads, especially those that frequently create and destroy them, should be watched closely to detect problems during development and testing. You must make sure that global resources, such as heap, are properly allocated and freed by threads to prevent serious problems later. Heap leakage is one of the easier problems to find, but it usually takes more time to fix. You are far better off assuming that your thread has a memory problem than assuming that it does not. If you take this stance during the design, you will be very sensitive to memory allocation and deallocation. If your design calls for many threads to execute the same piece of code, you should account for this in your unit tests by creating at least as many threads as you expect to use in the actual application.
The execution of many threads consumes more than just heap memory. Other resources, both system- and user-defined, must be monitored to make sure they are properly allocated and freed. This is easy if you encapsulate your resources inside a Singleton object to manage them. Besides the obvious advantage of having a single point where resources are allocated and freed, the resource manager can keep track of how many, and to whom, each resource is allocated. If all the resources become exhausted, the list maintained by the resource manager can be examined to track down the culprit. 5.1.2 Thread SynchronizationIt is uncommon for threads in an application to be completely independent of each other. After all, if they were truly independent, they could be separate processes. Let's look at the example we first used when threads were introduced: class thread1 : public apThread { void thread (); }; void thread1::thread () { for (int i=0; i<10; i++) { std::cout << threadid() << ": " << i << std::endl; sleep (100); } } int main() { thread1 thread1Inst, thread2Inst; thread1Inst.start (); thread2Inst.start (); thread1Inst.wait (); thread2Inst.wait (); return 0; } This example creates two threads that both write to std::cout . The output from this example cannot be predicted because thread execution is dependent upon the operating system. The line that outputs information to the console: std::cout << threadid() << ": " << i << std::endl; is not atomic . This means that this line of code is not guaranteed to run as a unit because the operating system scheduler may switch control to another thread, which might also be sending output to std::cout . Unless you really understand how the scheduler works on your platforms, you should assume that no operation is atomic. This really isn't an issue until you start using threads that share resources. Resources can be:
Shared resources can also be less tangible things like bandwidth , the amount of information your application can send or receive per unit of time. For example, many threads can simultaneously request information from sockets, such as fetching web pages or other information. Most operating systems can manage hundreds or thousands of simultaneous connections and will patiently wait for information to arrive . The management is not the problem, but the timely receipt of information is. If the machine running your application needs a constant stream of information, you may find that you are trying to access more information than you have available bandwidth to receive. Before we discuss how to use synchronization to control access to shared resources, let us discuss something you should never (or almost never) do. Most operating systems can give an application almost complete control of a system. For example, a process can be made to consume most of the processor time, while other processes are made to wait. A single thread can be made to run such that no other thread will execute. This is extremely dangerous. If you are considering doing this because your existing machine is not fast enough, you probably should consider running on a faster machine. After all, if a machine can only execute N instructions per second and you must run N+1 instructions, no amount of optimization will help you. More likely, the current design is lacking the techniques to make the pieces interact properly. Threads can be made to interact nicely with each other by synchronizing access to any resources that are shared. Most operating systems support many types of synchronization objects, but we will only discuss one of them. The big difference among most synchronization methods is their scope. By scope, we mean whether shared resources can be accessed by different threads in the same process, different processes, or even different machines. Remember, the larger the scope, the more overhead that must be paid in order to use it. By restricting ourselves to communication between threads, we can add synchronization with very little cost. As we did when we presented threads, we will show two implementations of apLock : POSIX for UNIX platforms and Win32 for Microsoft platforms. The file hierarchy looks the same: /include lock.h /win32 lock.h /unix lock.h The locking metaphor is very descriptive of what this object does. When one thread obtains a lock, all other threads that wish to obtain the lock must wait for it to be freed. As with apThread , the top-level version of lock.h loads the appropriate version of lock.h , or a default version if necessary. // Decide which implementation to use // Defining AP_NOTHREADS will use the default implementation in // applications where threading isn't an issue. #if !defined(AP_NOTHREADS) && defined(WIN32) #include <win32/lock.h> #elif !defined(AP_NOTHREADS) && defined(HasPTHREADS) #include <unix/lock.h> #else class apLock { public: apLock () {} ~apLock () {} bool lock () { return true;} // Get the lock bool unlock () { return true;} // Release the lock }; #endif One apLock object is constructed for each resource whose access must be limited to one thread at a time. The default version always returns immediately as though the lock/unlock operation were successful. We can modify our previous example to include locking by creating a global object to control access to the console. To work correctly, the lock must be obtained before something is written to the console, and then unlocked when finished. apLock consoleLock; class thread1 : public apThread { void thread (); }; void thread1::thread () { for (int i=0; i<10; i++) { consoleLock.lock (); std::cout << threadid() << ": " << i << std::endl; consoleLock.unlock (); sleep (100); } } int main() { thread1 thread1Inst, thread2Inst; thread1Inst.start (); thread2Inst.start (); thread1Inst.wait (); thread2Inst.wait (); return 0; } The differences from our previous example are: apLock consoleLock; ... consoleLock.lock (); std::cout << threadid() << ": " << i << std::endl; consoleLock.unlock (); ... When this snippet of code executes, you will no longer see lines of output broken by output from another thread. It will produce output similar to this: 2020: 0 2024: 0 2020: 1 2024: 1 2024: 2 2020: 2 2024: 3 2020: 3 2020: 4 2024: 4 2020: 5 2024: 5 2024: 6 2020: 6 2024: 7 2020: 7 2020: 8 2024: 8 2020: 9 2024: 9 If this were actual production code, we never would have defined consoleLock as a global object. We probably would not use a Singleton object either, because consoleLock is used only for console I/O. The best solution is to define an apLock object in a class that manages console I/O. For instance, we could modify our debugging stream interface (see Section 4.3.1 on page 94) to include a lock so that the cdebug stream is synchronized between threads. To simplify the locking and unlocking required to use consoleLock , we can take advantage of a technique called Resource Acquisition Is Initialization, also referred to as RAII. To use this method, we define a simple wrapper object that guarantees the lock will be freed when the object is destroyed . We create a new object, apConsoleLocker , to manage and own the lock as shown. class apConsoleLocker { public: apConsoleLocker () { consoleLock_.lock();} ~apConsoleLocker () { consoleLock_.unlock();} private: static apLock consoleLock_; // Prohibit copy and assignment apConsoleLocker (const apConsoleLocker& src); apConsoleLocker& operator= (const apConsoleLocker& src); }; Our example, continued from the previous page, now looks like this: ... { apConsoleLocker lock; std::cout << threadid() << : << i << std::endl; } ... The use of braces is very important, as the destruction of apConsoleLocker is what releases the lock so that other threads can use the resource that the lock controls. If you do not want the lifetime of your apConsoleLocker object to match that of the function it is defined in, you can use braces to control its lifetime. The full UNIX and Win32 implementations are found on the CD-ROM, but the important sections are shown here. For our UNIX implementation with pthreads, we use a mutex object (named because it coordinates mutually exclusive access to a resource). Since only one thread at a time can own a mutex, this mechanism solves our problem nicely. Microsoft Windows has mutex support as well, but it also allows them to be used between processes. A slightly faster solution is to use a critical section , which performs the same job as a mutex, but can only be used within the same process. The pthreads definition on UNIX is as shown. class apLock { public: apLock () { pthread_mutex_init (&lock_, NULL);} ~apLock () { pthread_mutex_destroy (&lock_);} bool lock () const { return pthread_mutex_lock (&lock_) == 0;} bool unlock () const { return pthread_mutex_unlock (&lock_) == 0;} private: mutable pthread_mutex_t lock_; }; The Microsoft Windows Win32 API is as shown. class apLock { public: apLock () { InitializeCriticalSection (&lock_); } ~apLock () { DeleteCriticalSection (&lock_);} bool lock () const { EnterCriticalSection (&lock_); return true;} bool unlock () const { LeaveCriticalSection (&lock_); return true;} private: mutable CRITICAL_SECTION lock_; }; We made lock() and unlock() into const methods so that they can be used without restriction. To do this, we made our underlying synchronization object mutable so we could avoid any casts. When writing code like this, pay particular attention to the destructor to make sure it doesn't become the weakest part of your object. Your destructor must clean up after itself. It is a mistake to leave this task up to the operating system when the application terminates. Our discussion of synchronization is not complete until we discuss deadlocking. Deadlocking occurs when many threads hold locks on one or more resources, while attempting to obtain locks to other resources held by other threads. Consider this example: apLock lock1, lock2; void thread1 () { ... lock1.lock (); // Do something lock2.lock (); ... } void thread2 () { ... lock2.lock (); // Do something else lock1.lock (); ... } The following conditions will cause a deadlock:
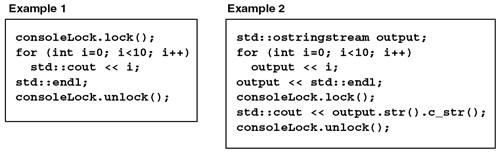
Both of these threads are now deadlocked and will never exit. While it is possible to write a lock() method that will time out if the lock cannot be obtained, you are still faced with an undesired situation (for pthreads, see pthread_mutex_trylock() ; for Win32, see TryEnterCriticalSection() or WaitForSingleObject() ). A better solution is to avoid deadlock conditions completely. Don't be fooled into thinking that you need many threads and many synchronization objects before you need to worry about deadlocks. If one thread forgets to release a synchronization object, you can easily face a partial deadlock when another thread waits for that lock. You will decrease the chances of a deadlock condition if you minimize the amount of code that must execute while you possess a lock. Consider these two examples: In Example 1, the console is locked while data is computed and written to the stream. In Example 2, the output data is computed first, then the lock is obtained for the shortest amount of time possible. Although this example is trivial, it does demonstrate how you can make simple changes to improve the dynamics of your application.
It may not be enough to simply reduce the chances for deadlocks; rather, using a simple rule can ensure that deadlocks are impossible . If each thread always locks items in the same order (such as, first lock A, then B, then C, ...), deadlocks can be completely avoided. Of course, such a strategy may involve more extra work than you are willing to do. See [Nichols97]. Now that we understand the issues of locking and unlocking, we can show a generic interface to the RAII technique. There are two steps: first we construct a global apLock object (see page 128) to control access to a resource; then, we define a class, apLocker , that locks the lock when it is constructed and unlocks the lock when it is destroyed. apLocker is shown here. class apLocker { public: apLocker (apLock& lock) : lock_ (lock) { lock_.lock();} ~apLocker () { lock_.unlock();} private: apLock& lock_; // Prohibit copy and assignment apLocker (const apLocker& src); apLocker& operator= (const apLocker& src); }; If you are not careful, you may discover that you are adding locking in places that do not need them. This may not break any code, but it can become confusing, or worse , cause an exhaustion of available locks. In Prototype 3 (see page 60) we used handles to take advantage of reference counting to minimize image duplication. But what happens if the representation objects are used by multiple threads? There is a potential bug inside apStorageRep because the reference count manipulation is not thread safe, as shown: void addRef () { ref_++;} void subRef () { if (--ref_ == 0) delete this;} Although a statement like ref_++ looks trivial, there is no guarantee that it is atomic. But before you go and rewrite this code to add locking, you need to understand how your application will use it. Although it is possible for multiple threads to create this situation, it is unlikely to occur. In this particular example, a bug is created if addRef() is called after subRef() has already decremented ref_ and deletes the object. This is no different than an application that attempts to use an object that goes out of scope. The problem is not missing locking; it is poor design. If an object must persist beyond the scope of a thread, it should be created and owned by a different thread that will not go out of scope. Please keep in mind that the Standard Template Library (STL) is not guaranteed to be thread safe. 5.1.3 ProcessesDepending upon the application, a problem can sometimes be divided into separate distinct pieces. Before all these pieces are committed to being separate threads, you should also consider if they should be separate processes. A process has its own address space and is completely insulated from other processes. In a multithreaded application, for example, an error in a thread can cause an entire application to shut down. However, an error in one process will not cause another process to shut down. To help you decide if you should be adding a thread or another process to your application, you should study what resources are needed and whether the application needs any information in a timely fashion. Choose threads when there is a tight coupling of resources, especially when timing is important. It is less clear-cut when there is a loose coupling between functions. For example, suppose an application generates a large volume of data by servicing requests by means of sockets or the Internet. Summary information is then written to a log file for each request. Every few minutes some statistics must be computed based on these results. If we implement this using only threads, it can be done without much difficulty, as follows :
Let's see how this changes when we use separate processes for the implementation:
This solution is clearly more work, but does it result in a more reliable solution? Although we left out many details, the answer is probably yes. There are two distinct pieces here: a request processor and a log analyzer, and they have separate requirements. We haven't said anything about throughput, but it is possible that requests for an imaging application must be processed at the rate of 50 or more requests per second. With other types of application, rates can be as high as hundreds or thousands of requests per second. The generation of statistics happens at a much slower rate; from every few minutes to every few hours. By writing the summary information to a file, we can share the necessary information so that these statistics can be computed by a separate process. Now let us consider what happens when an error condition occurs. If we used threads to implement our solution, an error in one thread can cause the entire application to shut down. Any incremental calculations will be lost and the application must be restarted. If we use separate processes to implement our solution, a failure of one process will not interfere with the other. The operating system will happily continue executing one of the processes, even though the other has stopped running. If the request processor dies, no data will be written to the summary file until it begins running again. The statistics process can still analyze this information and generate reports . If the statistics process dies, the requests will be processed and summary information will build up in one or more files for later processing. Another advantage of using processes to implement this solution is the well-defined interface between the two pieces. There are only so many ways that information can be transferred from one process to another. And in each of them, you transfer a discrete amount of information. Whether you are using the file system, sockets, or pipes, one process can transmit information to another process. This destination can also be on another machine entirely, but that is beyond the scope of this book. The point is that a rigid interface develops between the processes. If more information must be exchanged at a future point, this interface will be modified. With threads, there is a tendency for these interfaces to get blurred, because exchanging information is as easy as setting a variable. |

EAN: 2147483647
Pages: 59