4.1 Coding Guidelines
| Before going much further, we should discuss naming conventions and other coding conventions or standards. This is often a controversial subject, especially when the development team is more than just a couple of people. From the standpoint of the company, having very specific coding standards is an attractive proposition. Standards can help create very uniform software that developers, as well as customers, can rely upon to describe the code. It is not uncommon to have coding standards that require more than 50 pages to describe. The more complicated the standards, the more complex the bureaucracy is that supports it, and this translates into a productivity loss. Before an organization plunges into a complicated standards document, these trade-offs should be examined to make sure the final result is positive. From our own experience, we have found that balancing the needs of the organization without suppressing the creativity of the developers can be achieved. A standards document that addresses the most important issues, as well as guidelines for other issues, is a workable compromise. Developers can be challenged during code reviews if the software deviates from the standards, and any changes needed are agreed upon by those present. A coding standard should be thought of as a set of coding guidelines. Guidelines should be agreed upon by the team before starting a project. If a company-wide standard exists, it should be reviewed to make sure the guidelines are applicable . Make the guidelines simple and easy to follow, and keep in mind their purpose: you want software that is readable and maintainable , and you want development to progress smoothly and efficiently . Guidelines should, at a minimum, include such items as:
4.1.1 Changes to Existing SoftwareFirst, be consistent. Whatever guidelines you follow, you should strive to be consistent across all source files, or at least within a single translation unit. If you are starting a new project, all source files should meet these guidelines. If you are adding functionality to existing products, any new files should meet these guidelines. However, if you are adding functionality to an existing file, you need to examine how extensive the changes are. If the changes affect more than half of the lines of code, you should consider modifying all source lines to meet the new guidelines. But if you are making only smaller changes, such as bug fixes or simple enhancements, you are best served by adapting to whatever standard is used by the code. For example, consider a small change you need to make to some code: the fixed coordinates are to be replaced by the actual coordinates of the image. The existing code looks like this: /* Step through every pixel in the image and clear each pixel. */ for (int y=0; y<256; y++) { for (int x=0; x<256; x++) { ... } } You should avoid changing the style of the code while making the changes. Instead of changing the code to look like this,
you should keep the original code consistent by making the changes like this: /* Step through every pixel in the image and clear each pixel. */ for (int y=0; y<height(); y++) { for (int x=0; x<width(); x++) { ... } } If you decide to change the coding style or apply other formatting changes, you should make these changes before applying any functional changes. In addition, you should make sure the formatting changes pass all applicable unit tests and system tests before making any functional changes. Most developers (and we are no exception) like to work with a certain coding style, but that is not a sufficient reason to change any more lines of code than are necessary. Legacy code should always be viewed as fragile, and making any unnecessary changes should be avoided. We recommend using a system utility, such as diff , to view the changes made to a file, diff version1.cpp version2.cpp where version1.cpp and version2.cpp are placeholders for the files you want to compare. If we did this for the changes mentioned earlier, the output of the diff would be as follows : < for (int y=0; y<256; y++) --- > for (int y=0; y<height(); y++) 5c5 < for (int x=0; x<256; x++) --- > for (int x=0; x<width(); x++) It is very clear what changes have been made; the < character precedes the original line of code, and the > character precedes the modified line of code. But if we use diff to look at the original code and the nonrecommended modifications mentioned earlier, the output would be as follows: 1,6c1,4 < /* Step through every pixel in the image and < clear each pixel. */ < for (int y=0; y<256; y++) < { < for (int x=0; x<256; x++) < { --- > // Step through every pixel in the image and > // clear each pixel. > for (int y=0; y<height(); y++) { > for (int x=0; x<width(); x++) { The changes are much less clear in this example. These modifications would certainly complicate the review process and delay the software release. 4.1.2 Naming ConventionsWhat do you name a variable or a class? Do you use underscores in names , or capitalization? These are a matter of style and should be covered in the coding guidelines. Regardless of what style is applied, variable and class naming should always be descriptive. For example, instead of naming index variables i or j (a holdover from the days of Fortran) you should consider using x and y if these indices are used to represent coordinates. In this case, a single letter name is more descriptive than if these were called xCoordinate and yCoordinate . We have found that choosing short, descriptive names is better than choosing longer, even more descriptive names. When you look at our code, you will see variables x , y refer to coordinates, and x0 , y0 refer to the origin of the image. The first time you see this variable, you might have to look at the header file to see its meaning, but afterwards it is easy to remember. Traditional C code has used the underscore character to construct long variable names. For example, total_count and max_size are variable names that are both descriptive and readable. But just as readable are names like totalCount and maxSize . We prefer to use capitalization, but both methods work better as names than totalcount and maxsize . Consider a better example: compare bigE , and big_e , and bige . Naming conventions are numerous . We will look at two sets of them in a little more detail: one is the set of conventions used in this book, while the other is popular among Microsoft developers. The Microsoft convention defines class names using the prefix C . For example, the Microsoft Foundation Classes (MFC) contains the classes CPen , CBrush , and CFont . Our code examples use an ap prefix to avoid name collisions with other classes, as in the examples apRect and apException . If we had used the Microsoft convention, we would have wanted to call our classes CRect and CException , but both are already defined in the MFC (and probably countless other C++ libraries). Feel free to choose whatever prefix you want, but it is important to distinguish class names (and structs) from other identifiers. Namespaces were added to the language to prevent name collisions, but aside from their use in the standard C++ library, we have seen little use of this feature elsewhere. There is a common habit among developers to effectively disable namespaces by adding using namespace std; . We do not recommend this approach. Namespaces are important. It is not difficult to get into the habit of writing std:: when you want to access a feature from the standard library. For a nice description of how to safely migrate software toward using namespaces, see [Sutter02]. Member variables should also be distinguishable from other variables, such as local variables or arguments. The Microsoft convention adds two pieces of information to a variable name. The first is an m_ prefix to indicate a member variable, and the second group of letters , such as str , indicates the type of variable. Examples include: m_bUpdatable boolean m_nQuery short m_lCollatingOrder long m_strConnect CString m_pvData void* pointer Our convention is to add a simple underscore _ suffix to identify member variables. While not as descriptive as the other convention, it also doesn't tie our variable name to a specific data type. The variable name without the underscore remains available for other uses, such as a local variable. We also apply this convention to internal class names that are included in the API, but are never called directly by the API's clients . Using the underscore suffix, the variables from the previous example become: updatable_ query_ collatingOrder_ connect_ data_ Here's a simple example: class apExample { public: apExample (int size) : size_ (size) {} int size () const { return size_;} private: int size_; }; Our convention also includes a few other rules, as shown in Table 4.1. Table 4.1. Naming Conventions
We can demonstrate all of these rules in the following simple example: class apExample { public: enum eTypes {eNone, eSome, eAll}; static apExample& gOnly() { if (!sOnly_) sOnly_ = new apExample(); return *sOnly_;} eTypes type () const { return type_;} private: static apExample* sOnly_; eTypes type_; apExample () : type_ (eNone) {} }; apExample* apExample::sOnly_ = 0; This object may not do anything interesting, but it does show that with just a few simple rules, a piece of code can become quite readable. apExample is a singleton object. Access to member functions is through gOnly() , which returns a reference to the only instance of apExample . One last area we mention is template type arguments. Expressive names for templates are nice, but they consume a lot of space. Consider this example, where we define the copy constructor: template<class Type,class Storage> class apImage { apImage (const apImage<Type,Storage>& src); ... }; template<class Type,class Storage> apImage<Type,Storage>::apImage (const apImage<Type,Storage>& src) { ... } Because there is so much repetition of type names in the syntax, you can use shorter names, yet the clarity isn't compromised. We can simplify the above example by doing this: template<class T,class S> class apImage { apImage (const apImage<T,S>& src); ... }; template<class T,class S> apImage<T,S>::apImage (const apImage<T,S>& src) { ... } In this example, the expressive names only increased the complexity of the code. We prefer the single letter names, although we occasionally use two letter names (i.e., T1 , S1 ). Note that in Standard Template Library (STL), the template parameter names are very long because they form an API, and the use of long names is very descriptive. 4.1.3 IndentationIndentation is also a controversial issue. If you are designing a class library that you intend to sell to other developers, consistent indentation across all files is expected. However, if you are developing an application where only in-house developers have access to the sources, you can relax this standard to keep the indentation style consistent across a file (instead of ideally across all sources). Like we demonstrated earlier, modifications to an existing indentation style should be avoided unless most of the contents of a file are being rewritten. Otherwise, many unnecessary changes result that could delay releasing the code, as each difference has to be examined and tested . We strongly recommend using program editors that can be configured to many desired styles, reducing the number of keystrokes necessary to use any particular style. For example, our preferred style is: void function (std::string name) { if (test) { doSomething (name); doSomethingElse (); } else doNothing (); } This is the K&R (Kernighan & Ritchie) style, with indentation of two spaces. It is a compact style with the goal of keeping the code readable but dense. We prefer using spaces rather than tabs, since it is more platform- and editor-independent. It is much more difficult to make the style platform-independent if tabs are used. For example, software displayed under Microsoft Developer Studio might have tabs every two spaces, but your favorite Unix editor might have tabs every eight spaces (and printers often print plain text files assuming a tab size of eight). Not only will the display look strange , but if you edit the code on both platforms, you will not be happy with the results. 4.1.4 CommentsYes - and the more the better! Comments are almost always a good thing, as long as they accurately represent what the code does. Someone unfamiliar with a piece of software will usually look at the comments before looking at the code itself. And just like it takes some time to learn how to write good software, it does take time to learn how to write good comments. It is not the length of the comments, or the style in which you write them; rather it is the information they contain. Comments are more than just a written explanation of what the software does. They also contain thoughts and ideas that the developer noted while the code was being written. A casual observer may not understand the complexity of a block of code or the limitations that were added because of scheduling or other factors. Block comments are usually placed at the beginning of the file or before any piece of code that is not obvious. The length is not important, as long as the block comment conveys:
We will discuss our recommendations for header file comments in the next section, but first, look at an example of right ways and wrong ways to document.
Taken out of context, it is not clear what this code does. From the member name, apCache::clear , one could deduce that this code is deleting information from a cache object, but it requires a bit of study to figure out what this code is doing in all cases. Developers write code like this all the time. When it was written, it was very clear to the developer how and why it was written this way. But to other observers, or perhaps even the developer after a few weeks, the subtleties of this code might be lost. Now let's look at this example again, but with a very concise comment: void apCache::clear (eDeletion deletion) { // Delete some or all of our objects. This loop is different // because we can't delete the iterator we're on. // See Meyers, Effective STL, Item 9 Cache::iterator i; for (i=cache_.begin(); i!=cache_.end();) { apCacheEntryBase* entry = i->second; if (deletion == eAll entry->deletion() == eAll entry->deletion() == deletion) { delete (i->second); cache_.erase (i++); } else ++i; } } This comment does not attempt to explain the purpose of every line of code, but it does describe why this iterator loop differs from most others. It even includes a reference to a better description of the problem. There is no need to comment something that is obvious, such as the following: apRGBTmpl& operator= (const T& c) { red = c; green = c; blue = c; return *this; } Even taken out of context, it is clear that this member function sets the color components of an RGB pixel to the same value. Comments should also be added to single lines in order to clarify what is happening, or remind the reader why something is being done. It is a good idea to use this for conditional statements, as shown: void function () { if (isRunning()) { ... } else { // We're not running so use default values ... } } It is very clear after the conditional statement what the block of code is doing, but this thought might be lost when the else code is reached. Adding a comment here is a good idea just to get the readers mind back in sync with the code. Each file should have comments at the beginning containing any copyright information required by the company. Even if you are writing software for yourself, you should get in the habit of adding a standard block to all files. Following this, you should have at least a one-line description of what the file contains. Our files look like this: // bstring.cpp // // Copyright (c) 2002 by Philip Romanik, Amy Muntz // All rights reserved. This material contains unpublished, // copyrighted work, which includes confidential and proprietary // information. // // Created 1/22/2002 // // Binary string class The copyright block is often much longer than this, but it is surprising how much proprietary software contains no copyright information at all. If you are in the business of writing commercial software, no software you create should be missing this block. Even free software contains an extensive copyright notice, an assignment of rights, and a list of any restrictions placed on the code. Adding a line to tell when the file was created helps to distinguish older implementations from one another. Developers will often add a change list to describe all changes made to the file since it was created. There is nothing wrong with this, although its use has dwindled since version control systems have become popular. 4.1.5 Header File IssuesHeader files describe the public and private interface of an object. You should strive to make header files consistent and descriptive of all public member functions. It is also useful to describe most private members, as well as member variables. Whenever there is confusion about what a piece of code does, the header file can be consulted to describe the purpose of each function and the meaning of each variable. Include guards will prevent a header file from being included more than once during the compilation of a source file. Your symbol names should be unique, and we recommend choosing the name based on the name of the file. For example, our file, cache.h , contains this include guard: #ifndef _cache_h_ #define _cache_h_ ... #endif // _cache_h_ Lakos describes using redundant include guards to speed up compilation. See [Lakos96]. For large projects, it takes time to open each file, only to find that the include guard symbol is already defined (i.e., the file has already been included). The effects on compilation time can be dramatic, and Lakos shows a possible 20x increase in compilation times when only standard include guards are used. Since the header file is the public interface to an object, it makes sense to document each member function here with a simple description. We also recommend adjusting the alignment of similar lines of code to make it easy to see the differences. For example, here are two inline member functions: bool lockImage () const { return storage_.lock ();} bool unlockImage () const { return storage_.unlock ();} // Lock/unlock our image state (and our storage) Aligning your code in this way also makes it easier to spot mistakes in the code. It is very clear when you use the following formatting: bool isNull () const { return storage_.isNull();} int ref () const { return storage_.ref();} int bytesPerPixel () const { return storage_.bytesPerPixel();} int rowSpacing () const { return storage_.rowSpacing();} It is much harder to read the very same statements in this different format:
In these examples, we didn't include any documentation because the member name and inline definition are self-describing . Other member functions, however, may need more documentation. A comment should describe not only what a function does, but also its parameters and side effects. For example: int substitute (std::string src, std::string replacement, bool replaceAll = false); //Description String replacement of our internal string //Parameters src String to replace // replacement Replacement string // replaceAll false to replace only first occurrence //Returns Number of replacements made, 0 if none A consistent ordering of functions in a class definition is also important. It makes it easier to find and locate functions while looking at a header file. For each class, we use the following order:
For any class that does not require a user -written copy constructor or assignment operator, place a comment in the header file stating that it was a conscious decision to omit it. The absence of either a copy constructor or a comment saying that one is not necessary is a warning sign that the object needs to be checked. 4.1.6 RestrictionsThe C++ standard defines the capabilities of the language, but just because a compiler allows a certain syntax or feature, does not mean that you should be using it. Organizations and projects have very good reasons, such as multi-platform or legacy concerns, to restrict the use of features. The compiler used to produce a piece of software, or any tool used for development, should be controlled during the development and maintenance cycle of a project. You must not just change to a more recent version of the compiler without the same amount of testing done for a general release. It is very common for software released on multiple platforms or embedded platforms to use a specific language subset. With multi-platform releases, you are faced with designing to the least-common denominator (i.e., you build to the most restrictive features of each compiler). With embedded platforms, you have to deal with memory and performance issues that may force certain features to be avoided. A good example is exception handling. As the C++ standard library has evolved, so have many semi-compatible or outright incompatible library versions out there. But replacing these older libraries has a cost associated with it. And, since the performance of exception handling can vary greatly on different platforms (see Item 15 in [Meyers96]), your organization may decide that exception handling should not be used. Templates are another issue. When compilers first started to support templates, the level of support varied greatly by compiler vendor. Even today, some compilers have limitations regarding function templates and partial specialization. We were quite surprised when we took some of our code samples and compiled them on different platforms. We found that some compilers were able to figure out which template function or conversion to apply, while others gave up because of ambiguity. It turns out that the ambiguous template instantiation error is the correct behavior, according to the C++ standard. The standard describes a scoring method to deduce template parameters and to decide which template to instantiate. If there is more than one template definition producing an equally good score, an error is produced because of the ambiguity. For example, consider this function template: template<class T1, class T2, class T3> void add2 (const T1& s1, const T2& s2, T3& d1) { d1 = s1 + s2; } It is obvious what this function is doing, and we need to use these templates for built-in types (like unsigned char or int ). In order to get well-defined results from some of our image processing functions, we use functions like add2() . But there is no way to say that this template should only be applied to built-in types. Our code defines an RGB data type ( apRGB<> ) to specify the contents of a color pixel. So, elsewhere in the code we have defined the following function: template<class T1, class T2, class T3> void add2 (const apRGBTmpl<T1>& s1, const apRGBTmpl<T2>& s2, apRGBTmpl<T3>& d1) { ... } This version of add2() adds the red, green, and blue components separately to the output pixel (we aren't showing the definition now because we have to deal with some special overflow issues that we have not yet introduced). So now consider this snippet of code: int s1, s2, d1; apRGB<int> rgb1, rgb2, rgb3; ... add2 (s1, s2, d1); add2 (rgb1, rgb2, rgb3); It is pretty obvious to us what should happen; however, compilers that comply with the C++ standard will generate an error, because both templates are considered equally good for many data types. Our workaround is using a macro to selectively compile code and to define specific versions, such as those shown below: void add2 (int s1, int s2, int& d1); void add2 (int s1, int s2, unsigned char& d1); void add2 (int s1, int s2, unsigned short& d1); Another issue involving the use of templates or the C++ standard library is code bloat. Every instantiation of a template comes at a cost, because the compiler must produce a different implementation for each template object or function. Stroustrup shows how to use template specialization to help reduce code bloat when the template parameters are pointers. See [Stroustrup00]. In his example, template parameters for a class Vector , such as Vector<Shape*> and Vector<char*> , share a partial specialization, Vector<T*> . This method can prove very effective for curbing code bloat, since containers of pointers are very common. But even with such ways to curb the size of applications using templates, some organizations will simply choose to avoid the issue by eliminating or restricting the use of templates. For example, a single instance of std::vector<void*> can be used to handle a list of pointers. The main disadvantage of this is that casting will be needed when pointers are extracted from this container. It does not have to be a maintenance nightmare if all access to this object happens from a single function to handle the cast: class apImageList{ public: ... const apImage* operator[] (unsigned int index) const { return reinterpret_cast<const apImage*>(list_[index]);} private: std::vector<void*> list_; }; We could use the same template instantiation many times with complete safety, because access to the container passes through the necessary casting. Any use of casting should be documented in the code to explain why it is done. |
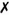 // Step through every pixel in the image and // clear each pixel. for (int y=0; y<height(); y++) { for (int x=0; x<width(); x++) { ... } }
// Step through every pixel in the image and // clear each pixel. for (int y=0; y<height(); y++) { for (int x=0; x<width(); x++) { ... } } EAN: 2147483647
Pages: 59