Section 3.2. Process Descriptor
3.2. Process DescriptorIn the kernel, the process descriptor is a structure called task_struct, which keeps track of process attributes and information. All kernel information regarding a process is found there. Throughout a process' lifecycle, a process interacts with many aspects of the kernel, such as memory management and scheduling. The process descriptor keeps track of information regarding these interactions, as well as the standard UNIX process attributes. The kernel stores all the process descriptors in a circular doubly linked list called the task_list. The kernel also keeps a reference to the currently running process' task_struct by means of the global variable current. (We refer to current throughout this book to indicate the process descriptor of the currently running process.) A process may be comprised of one or more threads. Each thread has a task_struct associated with it, including a unique thread ID. Threads in a common process share the same memory address space. The following categories describe some of the types of things a process descriptor must keep track of during a process' lifespan:
We now closely look at the fields in the task_struct structure. This section describes what they do and refers to the actual processing with which the field is involved. Although many of the fields are used for activities related to the aforementioned categories, some are beyond the scope of this book. The task_struct structure is defined in include/linux/sched.h: ----------------------------------------------------------------------- include/linux/sched.h 384 struct task_struct { 385 volatile long state; 386 struct thread_info *thread_info; 387 atomic_t usage; 388 unsigned long flags; 389 unsigned long ptrace; 390 391 int lock_depth; 392 393 int prio, static_prio; 394 struct list_head run_list; 395 prio_array_t *array; 396 397 unsigned long sleep_avg; 398 long interactive_credit; 399 unsigned long long timestamp; 400 int activated; 401 302 unsigned long policy; 403 cpumask_t cpus_allowed; 404 unsigned int time_slice, first_time_slice; 405 406 struct list_head tasks; 407 struct list_head ptrace_children; 408 struct list_head ptrace_list; 409 410 struct mm_struct *mm, *active_mm; ... 413 struct linux_binfmt *binfmt; 414 int exit_code, exit_signal; 415 int pdeath_signal; ... 419 pid_t pid; 420 pid_t tgid; ... 426 struct task_struct *real_parent; 427 struct task_struct *parent; 428 struct list_head children; 429 struct list_head sibling; 430 struct task_struct *group_leader; ... 433 struct pid_link pids[PIDTYPE_MAX]; 434 435 wait_queue_head_t wait_chldexit; 436 struct completion *vfork_done; 437 int __user *set_child_tid; 438 int __user *clear_child_tid; 439 440 unsigned long rt_priority; 441 unsigned long it_real_value, it_prof_value, it_virt_value; 442 unsigned long it_real_incr, it_prof_incr, it_virt_incr; 443 struct timer_list real_timer; 444 unsigned long utime, stime, cutime, cstime; 445 unsigned long nvcsw, nivcsw, cnvcsw, cnivcsw; 446 u64 start_time; ... 450 uid_t uid,euid,suid,fsuid; 451 gid_t gid,egid,sgid,fsgid; 452 struct group_info *group_info; 453 kernel_cap_t cap_effective, cap_inheritable, cap_permitted; 454 int keep_capabilities:1; 455 struct user_struct *user; ... 457 struct rlimit rlim[RLIM_NLIMITS]; 458 unsigned short used_math; 459 char comm[16]; ... 461 int link_count, total_link_count; ... 467 struct fs_struct *fs; ... 469 struct files_struct *files; ... 509 unsigned long ptrace_message; 510 siginfo_t *last_siginfo; ... 516 }; ----------------------------------------------------------------------- 3.2.1. Process AttributeRelated FieldsThe process attribute category is a catch-all category we defined for task characteristics related to the state and identification of a task. Examining these fields' values at any time gives the kernel hacker an idea of the current status of a process. Figure 3.2 illustrates the process attributerelated fields of the task_struct. Figure 3.2. Process AttributeRelated Fields
3.2.1.1. stateThe state field keeps track of the state a process finds itself in during its execution lifecycle. Possible values it can hold are TASK_RUNNING, TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_ZOMBIE, TASK_STOPPED, and TASK_DEAD (see the "Process Lifespan" section in this chapter for more detail). 3.2.1.2. pidIn Linux, each process has a unique process identifier (pid). This pid is stored in the task_struct as a type pid_t. Although this type can be traced back to an integer type, the default maximum value of a pid is 32,768 (the value pertaining to a short int). 3.2.1.3. flagsFlags define special attributes that belong to the task. Per process flags are defined in include/linux/sched.h and include those flags listed in Table 3.1. The flag's value provides the kernel hacker with more information regarding what the task is undergoing.
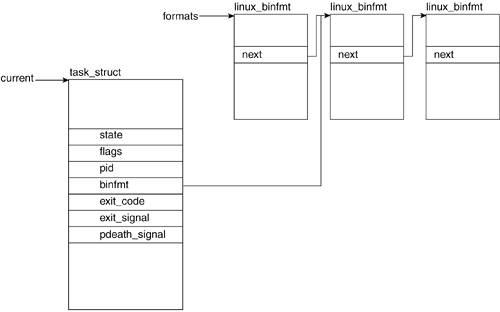
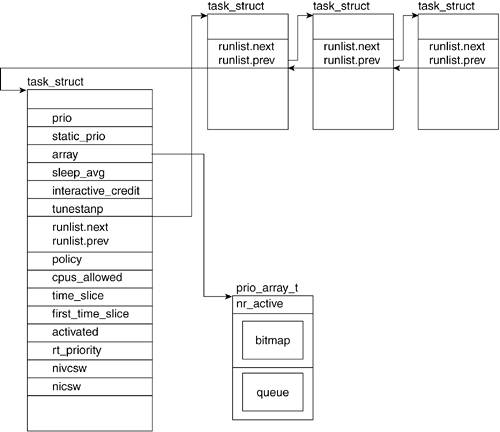
3.2.1.4. binfmtLinux supports a number of executable formats. An executable format is what defines the structure of how your program code is to be loaded into memory. Figure 3.2 illustrates the association between the task_struct and the linux_binfmt struct, the structure that contains all the information related to a particular binary format (see Chapter 9 for more detail). 3.2.1.5. exit_code and exit_signalThe exit_code and exit_signal fields hold a task's exit value and the terminating signal (if one was used). This is the way a child's exit value is passed to its parent. 3.2.1.6. pdeath_signalpdeath_signal is a signal sent upon the parent's death. 3.2.1.7. commA process is often created by means of a command-line call to an executable. The comm field holds the name of the executable as it is called on the command line. 3.2.1.8. ptraceptrace is set when the ptrace() system call is called on the process for performance measurements. Possible ptrace() flags are defined in include/ linux/ptrace.h. 3.2.2. Scheduling Related FieldsA process operates as though it has its own virtual CPU. However, in reality, it shares the CPU with other processes. To sustain the switching between process executions, each process closely interrelates with the scheduler (see Chapter 7 for more detail). However, to understand some of these fields, you need to understand a few basic scheduling concepts. When more than one process is ready to run, the scheduler decides which one runs first and for how long. The scheduler achieves fairness and efficiency by allotting each process a timeslice and a priority. The timeslice defines the amount of time the process is allowed to execute before it is switched off for another process. The priority of a process is a value that defines the relative order in which it will be allowed to be executed with respect to other waiting processesthe higher the priority, the sooner it is scheduled to run. The fields shown in Figure 3.3 keep track of the values necessary for scheduling purposes. Figure 3.3. Scheduling Related Fields
3.2.2.1. prioIn Chapter 7, we see that the dynamic priority of a process is a value that depends on the processes' scheduling history and the specified nice value. (See the following sidebar for more information about nice values.) It is updated at sleep time, which is when the process is not being executed and when timeslice is used up. This value, prio, is related to the value of the static_prio field described next. The prio field holds +/- 5 of the value of static_prio, depending on the process' history; it will get a +5 bonus if it has slept a lot and a -5 handicap if it has been a processing hog and used up its timeslice. 3.2.2.2. static_priostatic_prio is equivalent to the nice value. The default value of static_prio is MAX_PRIO-20. In our kernel, MAX_PRIO defaults to 140.
3.2.2.3. run_listThe run_list field points to the runqueue. A runqueue holds a list of all the processes to run. See the "Basic Structure" section for more information on the runqueue struct. 3.2.2.4. arrayThe array field points to the priority array of a runqueue. The "Keeping Track of Processes: Basic Scheduler Construction" section in this chapter explains this array in detail. 3.2.2.5. sleep_avgThe sleep_avg field is used to calculate the effective priority of the task, which is the average amount of clock ticks the task has spent sleeping. 3.2.2.6. timestampThe timestamp field is used to calculate the sleep_avg for when a task sleeps or yields. 3.2.2.7. interactive_creditThe interactive_credit field is used along with the sleep_avg and activated fields to calculate sleep_avg. 3.2.2.8. policyThe policy determines the type of process (for example, time sharing or real time). The type of a process heavily influences the priority scheduling. For more information on this field, see Chapter 7. 3.2.2.9. cpus_allowedThe cpus_allowed field specifies which CPUs might handle a task. This is one way in which we can specify which CPU a particular task can run on when in a multiprocessor system. 3.2.2.10. time_sliceThe time_slice field defines the maximum amount of time the task is allowed to run. 3.2.2.11. first_time_sliceThe first_time_slice field is repeatedly set to 0 and keeps track of the scheduling time. 3.2.2.12. activatedThe activated field keeps track of the incrementing and decrementing of sleep averages. If an uninterruptible task gets woken, this field gets set to -1. 3.2.2.13. rt_priorityrt_priority is a static value that can only be updated through schedule(). This value is necessary to support real-time tasks. 3.2.2.14. nivcsw and nvcswDifferent kinds of context switches exist. The kernel keeps track of these for profiling reasons. A global switch count gets set to one of the four different context switch counts, depending on the kind of transition involved in the context switch (see Chapter 7 for more information on context switch). These are the counters for the basic context switch:
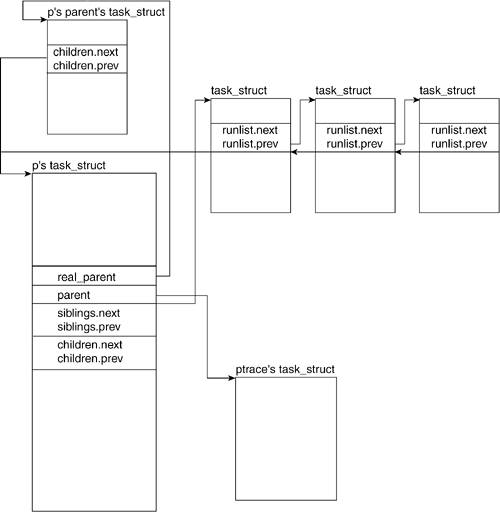
3.2.3. Process RelationsRelated FieldsThe following fields of the task_struct are those related to process relationships. Each task or process p has a parent that created it. Process p can also create processes and, therefore, might have children. Because p's parent could have created more than one process, it is possible that process p might have siblings. Figure 3.4 illustrates how the task_structs of all these processes relate. Figure 3.4. Process RelationsRelated Fields
3.2.3.1. real_parentreal_parent points to the current process' parent's description. It will point to the process descriptor of init() if the original parent of our current process has been destroyed. In previous kernels, this was known as p_opptr. 3.2.3.2. parentparent is a pointer to the descriptor of the parent process. In Figure 3.4, we see that this points to the ptrace task_struct. When ptrace is run on a process, the parent field of task_struct points to the ptrace process. 3.2.3.3. childrenchildren is the struct that points to the list of our current process' children. 3.2.3.4. siblingsibling is the struct that points to the list of the current process' siblings. 3.2.3.5. group_leaderA process can be a member of a group of processes, and each group has one process defined as the group leader. If our process is a member of a group, group_leader is a pointer to the descriptor of the leader of that group. A group leader generally owns the tty from which the process was created, called the controlling terminal. 3.2.4. Process CredentialsRelated FieldsIn multiuser systems, it is necessary to distinguish among processes that are created by different users. This is necessary for the security and protection of user data. To this end, each process has credentials that help the system determine what it can and cannot access. Figure 3.5 illustrates the fields in the task_struct related to process credentials. Figure 3.5. Process CredentialsRelated Fields
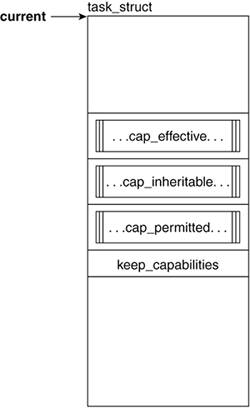
3.2.4.1. uid and gidThe uid field holds the user ID number of the user who created the process. This field is used for protection and security purposes. Likewise, the gid field holds the group ID of the group who owns the process. A uid or gid of 0 corresponds to the root user and group. 3.2.4.2. euid and egidThe effective user ID usually holds the same value as the user ID field. This changes if the executed program has the set UID (SUID) bit on. In this case, the effective user ID is that of the owner of the program file. Generally, this is used to allow any user to run a particular program with the same permissions as another user (for example, root). The effective group ID works in much the same way, holding a value different from the gid field only if the set group ID (SGID) bit is on. 3.2.4.3. suid and sgidsuid (saved user ID) and sgid (saved group ID) are used in the setuid() system calls. 3.2.4.4. fsuid and fsgidThe fsuid and fsgid values are checked specifically for filesystem checks. They generally hold the same values as uid and gid except for when a setuid() system call is made. 3.2.4.5. group_infoIn Linux, a user may be part of more than one group. These groups may have varying permissions with respect to system and data accesses. For this reason, the processes need to inherit this credential. The group_info field is a pointer to a structure of type group_info, which holds all the information regarding the various groups of which the process can be a member. The group_info structure allows a process to associate with a number of groups that is bound by available memory. In Figure 3.5, you can see that a field of group_info called small_block is an array of NGROUPS_SMALL (in our case, 32) gid_t units. If a task belongs to more than 32 groups, the kernel can allocate blocks or pages that hold the necessary number of gid_ts beyond NGROUPS_SMALL. The field nblocks holds the number of blocks allocated, while ngroups holds the value of units in the small_block array that hold a gid_t value. 3.2.5. Process CapabilitiesRelated FieldsTraditionally, UNIX systems offer process-related protection of certain accesses and actions by defining any given process as privileged (super user or UID = 0) or unprivileged (any other process). In Linux, capabilities were introduced to partition the activities previously available only to the superuser; that is, capabilities are individual "privileges" that may be conferred upon a process independently of each other and of its UID. In this manner, particular processes can be given permission to perform particular administrative tasks without necessarily getting all the privileges or having to be owned by the superuser. A capability is thus defined as a given administrative operation. Figure 3.6 shows the fields that are related to process capabilities. Figure 3.6. Process CapabilitiesRelated Fields
3.2.5.1. cap_effective, cap_inheritable, cap_permitted, and keep_capabilitiesThe structure used to support the capabilities model is defined in include/linux/security.h as an unsigned 32-bit value. Each 32-bit mask corresponds to a capability set; each capability is assigned a bit in each of:
Table 3.2 lists some of the supported capabilities that are defined in include/linux/capability.h.
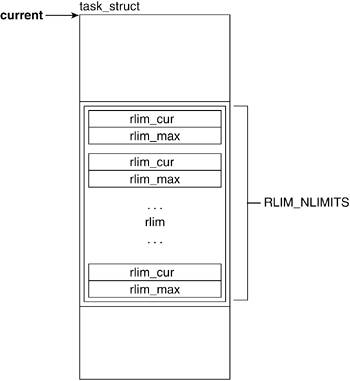
The kernel checks if a particular capability is set with a call to capable() passing as a parameter the capability variable. Generally, the function checks to see whether the capability bit is set in the cap_effective set; if so, it sets current->flags to PF_SUPERPRIV, which indicates that the capability is granted. The function returns a 1 if the capability is granted and 0 if capability is not granted. Three system calls are associated with the manipulation of capabilities: capget(), capset(), and prctl(). The first two allow a process to get and set its capabilities, while the prctl() system call allows manipulation of current->keep_capabilities. 3.2.6. Process LimitationsRelated FieldsA task uses a number of the resources made available by hardware and the scheduler. To keep track of how they are used and any limitations that might be applied to a process, we have the following fields. 3.2.6.1. rlimThe rlim field holds an array that provides for resource control and accounting by maintaining resource limit values. Figure 3.7 illustrates the rlim field of the task_struct. Figure 3.7. task_struct Resource Limits
Linux recognizes the need to limit the amount of certain resources that a process is allowed to use. Because the kinds and amounts of resources processes might use varies from process to process, it is necessary to keep this information on a per process basis. What better place than to keep a reference to it in the process descriptor? The rlimit descriptor (include/linux/resource.h) has the fields rlim_cur and rlim_max, which are the current and maximum limits that apply to that resource. The limit "units" vary by the kind of resource to which the structure refers. ----------------------------------------------------------------------- include/linux/resource.h struct rlimit { unsigned long rlim_cur; unsigned long rlim_max; }; ----------------------------------------------------------------------- Table 3.3 lists the resources upon which their limits are defined in include/asm/resource.h. However, both x86 and PPC have the same resource limits list and default values.
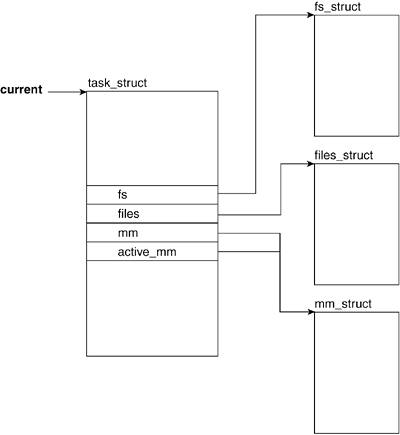
When a value is set to RLIM_INFINITY, the resource is unlimited for that process. The current limit (rlim_cur) is a soft limit that can be changed via a call to setrlimit(). The maximum limit is defined by rlim_max and cannot be exceeded by an unprivileged process. The geTRlimit() system call returns the value of the resource limits. Both setrlimit() and getrlimit() take as parameters the resource name and a pointer to a structure of type rlimit. 3.2.7. Filesystem- and Address SpaceRelated FieldsProcesses can be heavily involved with files throughout their lifecycle, performing tasks such as opening, closing, reading, and writing. The task_struct has two fields that are associated with file- and filesystem-related data: fs and files (see Chapter 6, "Filesystems," for more detail). The two fields related to address space are active_mm and mm (see Chapter 4, "Memory Management," for more detail on mm_struct). Figure 3.8 shows the filesystem- and address spacerelated fields of the task_struct. Figure 3.8. Filesystem- and Address SpaceRelated Fields
3.2.7.1. fsThe fs field holds a pointer to filesystem information. 3.2.7.2. filesThe files field holds a pointer to the file descriptor table for the task. This file descriptor holds pointers to files (more specifically, to their descriptors) that the task has open. 3.2.7.3. mmmm points to address-space and memory-managementrelated information. 3.2.7.4. active_mmactive_mm is a pointer to the most recently accessed address space. Both the mm and active_mm fields start pointing at the same mm_struct. Evaluating the process descriptor gives us an idea of the type of data that a process is involved with throughout its lifetime. Now, we can look at what happens throughout the lifespan of a process. The following sections explain the various stages and states of a process and go through the sample program line by line to explain what happens in the kernel. |

EAN: N/A
Pages: 134