Chapter3.Processes: The Principal Model of Execution
Chapter 3. Processes: The Principal Model of ExecutionIn this chapter
The term process, defined here as the basic unit of execution of a program, is perhaps the most important concept to understand when learning how an operating system works. It is essential to understand the difference between a program and a process. Therefore, we refer to a program as an executable file that contains a set of functions, and we refer to a process as a single instantiation of a particular program. A process is the unit of operation that uses resources provided by the hardware and executes according to the orders of the program it instantiates. The operating system facilitates and manages the system's resources as the process requires. Computers do many things. Processes can perform tasks ranging from executing user commands and managing system resources to accessing hardware. In part, a process is defined by the set of instructions it is to execute, the contents of the registers and program counter when the program is in execution, and its state. A process, like any dynamic entity, goes through various states. In fact, a process has a lifecycle: After a process is created, it lives for a variable time span during which it goes through a number of state changes and then dies. Figure 3.1 shows the process lifecycle from a high-level view. Figure 3.1. Process Lifecycle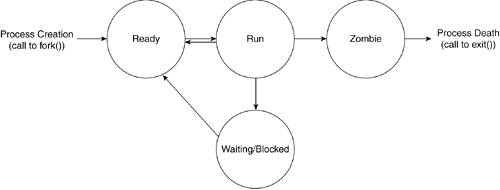 When a Linux system is powered on, the number of processes it will need is undetermined. Processes need to be created and destroyed when they are needed. A process is created by a previously existing process with a call to fork(). Forked processes are referred to as the child processes, and the process that creates them is referred to as the parent process. The child and parent processes continue to run in parallel. If the parent continues to spawn more child processes, these processes are sibling processes to the original child. The children may in turn spawn off child processes of their own. This creates a hierarchical relationship among processes that define their relationship. After a process is created, it is ready to become the running process. This means that the kernel has set up all the structures and acquired all the necessary information for the CPU to execute the process. When a process is prepared to become the running process but has not been selected to run, it is in a ready state. After the task becomes the running process, it can
This chapter looks closely at all these states and transitions. The scheduler handles the selection and deselection of processes to be executed by the CPU. Chapter 7, "Scheduling and Kernel Synchronization," covers the scheduler in great detail. A program contains a number of components that are laid out in memory and accessed by the process that executes the program. This includes a text segment, which holds the instructions that are executed by the CPU; the data segments, which hold all the data variables manipulated by the process; the stack, which holds automatic variables and function data; and a heap, which holds dynamic memory allocations. When a process is created, the child process receives a copy of the parent's data space, heap, stack, and process descriptor. The next section provides a more detailed description of the Linux process descriptor. There are many ways to explain a process. The approach we take is to start with a high-level view of the execution of a process and follow it into the kernel, periodically explaining the kernel support structures that sustain it. As programmers, we are familiar with writing, compiling, and executing programs. But how does this tie into a process? We discuss an example program throughout this chapter that we will follow from its creation through its performance of some key tasks. In our case, the Bash shell process will create the process that instantiates our program; in turn, our program instantiates another child process. Before we proceed to the discussion of processes, a few naming conventions need to be clarified. Often, we use the word process and the word task to refer to the same thing. When we refer to the running process, we refer to the process that the CPU is currently executing.
|
EAN: N/A
Pages: 134