JIT Compilation: Verification and Validation
We are now going to examine aspects of the operation of the JIT compiler. In particular, we will cover the principles behind how it validates and verifies code before executing it.
In the last chapter we indicated that the errors that could prevent managed code from executing include invalid code and unverifiable code. If the JIT compiler detects invalid code, it will fail the JIT for that method, causing an exception to be thrown, whereas if it detects unverifiable code it will merely insert some extra code into the relevant block of code, which will generate an exception if code does not have permission to skip verification. If the code does have SkipVerification permission, it will run without the exception, and the user has to hope that this trust in the unverifiable code is justified and it won't accidentally trash the system. In this section, we will examine in more detail what requirements a program must satisfy if it is to pass the valid code and verifiable code tests.
Validating Code
There are really two requirements for IL code to be considered valid:
-
Certain instructions require particular data types to be on the evaluation stack.
-
It must be possible to work out the state of the evaluation stack at each point in the code in a single pass.
In Chapter 2, we saw a couple of examples that illustrate the first requirement: the ret command expects the evaluation stack to be empty for a void method, or to contain one item, the return value, for a non-void method. Similarly, the mul command and other arithmetic commands require the top two data items on the stack to be consistent types. For example, an attempt to multiply an int32 by a float32 is considered invalid code.
It should be self-evident that the two above-listed requirements are closely related: if you can't work out the state of the evaluation stack, then you can't test whether the stack is in an appropriate condition for instructions such as a mul. However, the second requirement is a much more general condition, since it requires that even for instructions such as ldloc.0 and br.s, which don't care what's on the evaluation stack, the JIT compiler must still be able to establish the state of the stack at that point.
We also shouldn't forget those last few words on the second condition: 'in a single pass'. These words are added in order to ensure that the IL language supports very simple JIT compilers. The CLR's JIT compiler is quite sophisticated and makes multiple passes, including passes to optimize the code. However, it will still fail as invalid any code that doesn't satisfy the formal definition of valid code (even where it, as a more sophisticated compiler that makes multiple passes, would have been able to compile that code). That requirement is the reason for the .maxstack directive at the beginning of each method that indicates the maximum number of items that will simultaneously be on the stack.
An important point about valid code is that all we are effectively testing for when we test for validity is that the JIT compiler can work out what's on the stack. If it can't do that, then there are various reasons why it wouldn't be able to run the code in the .NET environment - for example, it wouldn't be able to generate the tables of which types occupy which memory that the garbage collector needs. That's why code has to be validated before it can run. By validating code, we are testing whether it is going to be possible in principle to compile and execute that code. However, what we are not testing is whether the types are used in a consistent way (other than for certain specific IL instructions that require it). For example, if you try to pass an object reference to a method that is expecting a managed pointer, that won't be detected - for the simple reason that that might give you unexpected results but doesn't in principle stop the code from being executed. That type of condition will be tested for when we attempt to verify the code - we'll look at this shortly.
In order to test the condition of the evaluation stack, the ECMA standard specifies that the JIT compiler follows a simple algorithm: starting with the very first instruction in a method (for which the evaluation stack is empty), it follows every possible path from one instruction to the next, working out the effect that each instruction has on the evaluation stack, and checking that the resultant stack state for the next instruction is consistent with that obtained from any other path that leads to that instruction. Described like that, the algorithm might sound hard to grasp, but it is actually roughly what we've done ourselves several times in the last couple of chapters - whenever I've presented a code sample and listed the state of the evaluation stack beside each line of code. When reading through the list, you'll almost certainly have gone through virtually the exact same process in your head - the process of saying, "this instruction does that to the stack, which means the next instruction will find this data on it." The only difference is that in the examples in the last chapter, I occasionally inserted data values. The JIT compiler won't do that. When validating code, all it is interested in is what types will be placed on the stack - at this point in time it has no way of knowing and doesn't care anyway what values those types might contain.
In order to illustrate how validation works in practice, we're going to go through an example, and manually validate some code, just the way the JIT compiler would do it. This should make it clear what the validation involves and what kinds of situation can cause a program to be invalid.
Although I will describe some algorithmic details here, I don't as it happens have access to the code for the JIT compiler (much as I would like to!). I can't say whether Microsoft's implementation follows how I do it here, but I can tell you that, however Microsoft has done it, it will be logically equivalent to the algorithm we're going to work through.
Here's the method we are going to validate:
.method public static int32 GetNumber() cil managed { .maxstack 1 .locals init (int32) ldc.14.s 23 br.s JumpThere BackHere: ldloc.0 ret JumpThere: brtrue.s BackHere ldl0c.0 ldc.i4.1 add ret }
This is actually a rather silly implementation of a method - all it does is return the value 0 - but the code manages to jump all over the place in the process of getting the value. But then I've designed this method to illustrate a couple of points about validation, not as an example of good programming! Do you think this method will pass? Well, let's see. First, let's imagine some conceptual boxes, one for each instruction. The JIT compiler wants to put in each box the details it's worked out of what type will be on the stack at that point.
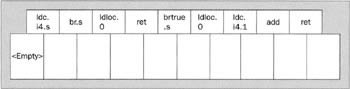
At present almost all the boxes are blank, indicating that we don't yet know what type goes in any of them, although we do know from the .maxstack directive that there will be at most one data item in each box. The only exception is that we know the first box contains nothing (I've written <empty> to indicate the fact). This box represents the start of the method and methods always start with a clean evaluation stack.
The first instruction the JIT compiler examines is ldc.i4.s. That puts an int32 onto the stack. We know the value is 23, but all the validation algorithm cares about is that it's an int32. So int32 can go in the second box. Then we have a br.s instruction. That doesn't change the contents of the stack, but it does transfer control. So we need to pop the correct stack contents in the box representing the target of the branch. At this stage our diagram looks like this:
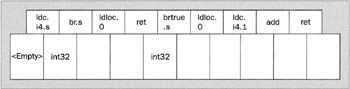
Now we have a problem. Remember we are not following execution flow - instead we are doing a forward pass through the code, so the next instruction we need to consider is the first ldloc.0 command, the one that immediately follows the br.s and is attached to the BackHere label. What's the state of the stack that this command sees? We have no way of knowing, since we've not yet seen any command that branches to here. So we are going to have to assume the stack is empty at this point. The ECMA specifications actually say that if you hit a situation like this, then you must assume that the evaluation stack is empty, and any later instructions that branch back here will have to live with that and be consistent with it. So we follow ldloc.0 - that places an int32 on the stack, since local variable zero is of type int32. Next we come to the ret statement. This is the first statement for which the opcode has a requirement of its own about the stack contents. Since this is a non-void method, ret expects to find one item on the stack. Luckily that's what we have, so everything is consistent. Now our diagram looks like this:
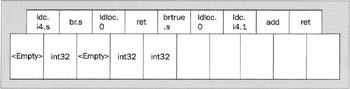
Now we have to consider the brtrue.s instruction, which branches if the top item of the stack is nonzero. And this instruction is an interesting one: brtrue.s expects to find at least one item of an integer type on the stack, and, since it's a conditional branch, it might theoretically send the control flow to either of two locations. (Yes, I know that you and I can tell just by looking at the code that the stack contains '23', the non-zero condition will always be satisfied and the branch will always occur. But the JIT compiler can't tell that yet. Remember, it's looking at types, not values.)
To sort out this opcode, we first need to confirm the stack starts off with an integer type as the topmost element. As it happens, we've already filled in the stack contents for this instruction - we did it when we analyzed the br.s. It's got one int32 in it, which is fine. brtrue.s will pop that off the stack, leaving it empty. So let's look at the two instructions that might get executed next. Firstly, the following instruction (if the branch doesn't happen) - so we place <Empty> into the next box. Next the target of the branch, the BackHere label. Ah - potential problem. We've already filled in a stack contents for that point in the code. It'd better match. Luckily we filled in that box as <Empty>, which is what we want. If there had been an inconsistency here, then the method would be deemed invalid on the grounds that it's failed the test of being able to work out uniquely and consistently what data type occupies the stack at each point in the code.
Finally, we trawl on linearly through the code. We hit the last ldloc.0, which puts an int32 onto the stack. Then we hit ldc.i4.1, which puts another int32 onto the stack and - wait - that's torn it. The .maxstack directive told us we only needed to reserve space for one item on the stack. There's no room for the new int32. So close to the end, and we've failed the test. This method is not valid code, and will be rejected by the Microsoft JIT compiler, as and by any JIT compiler that conforms to the ECMA standard. Though, as you can probably see, if we'd said .maxstack 2 instead, then the method would have passed:
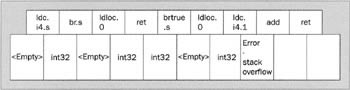
The irony is that the code has failed because of some instructions that a cursory examination of the code tells us will never actually get executed anyway. But because we need to support a basic JIT compiler that wouldn't be able to spot things like that, we still have to decree that this code is not correct, valid, IL.
Going through this has given us a feel for most of the issues that the JIT compiler will face when testing whether code is valid. Other than .maxstack problems, I'd imagine the most common reason for handwritten IL code not being valid is an inconsistency in the stack state detected at a branch target. For example, a loop that on balance adds one item to the stack on each iteration will cause this problem.
Incidentally, checking that types match on a branch target is a slightly more complex problem than the above example illustrates. Suppose you have two branches that both target the same instruction. Clearly, for valid code, the number of items on the evaluation stack at the target must be the same for each branch. But what about the types? Suppose one branch instruction branches with a System.Windows.Forms.Control reference on the stack, where the other has a System.Windows.Forms.Form reference. Will that count as valid? The answer is "yes" in this case. The JIT compiler, if it sees different types, will try to find one type that can encompass both possibilities. In this example, there is no problem if we assume that the type on the stack is Control - Form is derived from Control, so a Control reference can happily refer to a Form object. On the other hand, if one branch instruction had Form on the stack, and the other had a System.Drawing.Color instance, that wouldn't be valid. There's no type you can use to store both a Control reference and a Color instance - not even System.Object, since Color is a value type. (Of course, if it had been a reference to a boxed Color instance then Object would do nicely, and the code would be valid.) I could go on with examples, but I think you get the picture. The Partition III document lists a complicated set of formal rules for resolving type discrepancies, but the rules just boil down to the common-sense criteria I've been using here.
By now you'll have a very good idea of the principles used to identify valid code. It may look a bit remote from your high-level language programming - after all, all the Microsoft compilers will only generate valid IL code (if one of them did ever emit some invalid code even just once, I'd imagine there'd be some pretty red faces at Microsoft and some very frantic efforts to fix the bug in the compiler!) However, if you do ever write your own IL code, I can virtually guarantee you'll very quickly find yourself trying to work out why the JIT compiler has claimed your code is invalid when it looked perfectly logical to you. That's when you'll need to have understood the contents of this section. You'll also need it if you ever do compiler writing. Also, it may come in useful if you look at the IL code emitted by your favorite compiler and wonder why the IL seems to be going through some unnecessary hoops in its control flow when you can see some obvious optimizations. There's a good chance it's because of the need to keep to valid code.
Don't forget peverify.exe. This tool can be a great help, since it will point out exactly the reasons why code fails validity as well as verifiability.
Verifying Type Safety
Now we are going to examine in detail how .NET enforces type safety, and for that matter what type safety actually means. We'll see that the verification algorithm is very similar to the validation algorithm, but imposes more stringent conditions on the state of the evaluation stack.
Type Safety - The Theory
I can't help thinking that the name 'type safety' is in some ways a slightly unfortunate choice, because it immediately makes you think of the type safety restrictions enforced by many languages, whose aim is to ensure you know at all times what data type you are dealing with. The kind of type safety that says that if you load an integer, you shouldn't manipulate it as if it were a floating-point number. Although that kind of type safety is very important in .NET, and is indeed the basis of the verification algorithm, it is more a means to an end. When we talk about verifying type safety what we are actually talking about is verifying that an application is well-behaved, and more specifically that it cannot manipulate any memory that does not belong to it. In fact, enforcing classic type safety is one of the main weapons that ensures that this cannot happen. So somewhere along the line the terminology has arisen whereby we speak of managed code as type-safe, when what we actually mean is that it won't try to do anything naughty as far as accessing memory that doesn't belong to it is concerned (because it doesn't misinterpret types in a way that could allow that to happen). But since type-safe is the terminology in use, we'll stick to it here.
Type safety is in fact just one of two weapons in .NET's armory against badly behaved programs. There are two issues, and we will deal with them separately.
-
Is the code in the assembly explicitly going to do things like write to the Registry, write to your file system, or do some other potentially dangerous action that you might not want it to? This is really an issue of security.
-
Is the code in the assembly going to do some unfortunate pointer arithmetic or something similar that results in it corrupting your memory or doing something to damage other applications, even though it hasn't explicitly instantiated those .NET classes that are intended to do that sort of thing? This is the concern of type safety.
Many versions of Windows, of course, have in-built native security checks that will prevent code accessing some areas of memory or the file system to which the user account does not have access - but this security is based on the user ID of the process in which the code is running, and so can't help you if you are, say, the administrator, wanting to run some code that you're not sure if you trust totally. For this reason we'll concentrate here on the additional security features built into the CLR.
Security against things like the program explicitly and openly using the Registry or the file system is fairly easy to achieve. It's done by the simple device of CIL not having any instructions in its instruction set that can do those sorts of operations. Instead, such actions need to be done by instantiating various .NET Framework classes supplied by Microsoft, which will handle those tasks (internally using native code which has been thoroughly tested). The CLR will of course prevent an assembly from accessing those classes unless it believes the code has sufficient security permissions (in .NET terms, evidence) to do so. We'll look in detail at how this security mechanism works in Chapter 12.
Incidentally, the ability to call into unmanaged code is covered by this same security mechanism. An assembly must have the UnmanagedCode permission in order to do that. Microsoft's assemblies such as mscorlib.dll always have this permission, because they have been strongly signed by Microsoft. But other assemblies might not have this permission - that depends on your security policy and on where those other assemblies have come from.
Security against the program corrupting memory or doing something else bad, simply because it uses poor (or malicious) coding practices, is a lot harder to achieve. This doesn't only mean corrupting memory or accessing memory belonging to a different process. If an assembly can start freely tampering with memory in its own process space, then it can in principle do just about anything else. For example, the CLR might have deemed that an assembly is not sufficiently trusted to use the Microsoft.Win32 classes to write to the Registry. But that by itself won't stop a malicious assembly from using some clever pointer arithmetic from locating the IL code for those classes in mscorlib.dll (which will almost certainly be loaded in the running process), then using some IL command such as the indirect call command (calli) to invoke the code without the CLR having any means to identify which classes and methods this malicious code is actually invoking.
In order to guard against that, we need to be able to guarantee that code in an assembly will not under any circumstances:
-
Access any memory other than the variables which it has itself instantiated on the stack frame and managed heap.
-
Call into code in another assembly other than by using instructions such as call or callvirt, which allow the CLR to see at JIT-compile time what methods are being called, and therefore to judge whether the assembly is trusted to call those methods.
And this is where we hit our problem. In an ideal world, a computer would be able to tell with 100 percent accuracy whether a particular program complied with the above conditions. Unfortunately, in the real world that is simply not possible. There is a lot of mathematical theory behind computability, and it has been proven mathematically that it is impossible to come up with an algorithm that can in a finite time work out with 100% accuracy whether any program is type-safe. Such an algorithm would be a mathematical impossibility, given the rich range of instructions available in CIL. The only way to tell for certain exactly what every program is going to do is to run it - and of course by then it's too late.
So we have to come up with the nearest best solution that is practical to achieve, and accept that our solution will inevitably be imperfect. Any realistic solution is going to have to involve making some guesses about whether a given program is or is not going to behave, and therefore whether it is OK to run it. And performance is at a premium as well: this process of figuring out whether it is OK to run a program has to happen at JIT compilation time, which means it has to put as little overhead as possible on the JIT compiler.
Having established that there is going to have to be some approximation involved, what approximations can we make? If we're going to start guessing, then it's pretty clear that there are going to be times when we will guess wrong. It should also be clear that it would be completely unacceptable if there were any possibility of our algorithm passing a program that is in fact not type-safe. If that happened, even once, it would completely invalidate all the careful security systems that Microsoft has built up around .NET. So the algorithm has to err on the side of caution. And from this arises the concept of verifiably type-safe. We come up with some algorithm that tests whether code is type-safe. That algorithm is imperfect, and will quite often fail code that would have been perfectly safe to run. But it will never pass any code that isn't type-safe. Code that the algorithm passes is, at least as far as that algorithm is concerned, known as verifiably type-safe, or more commonly simply as verifiable. The situation looks like this Venn diagram:
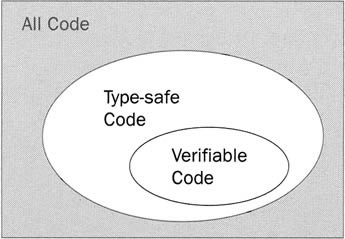
The simplest such algorithm would be one that failed every program. An algorithm like that would be very quick to run, too! But unfortunately it wouldn't be very useful. However, from that trivially simple starting point, we can start to build tests into the algorithm - conditions that will prove that the code is type-safe if it passes them. It should be clear that by making the algorithm more and more sophisticated, you can make the set of verifiably type-safe code come closer and closer to matching the set of genuinely type-safe code. You can never get an exact match - that's mathematically impossible. And in any case, at some point the trade-off between how accurate you'd like the algorithm to be and how quickly you want it to run comes into play.
So that's the principle. Unfortunately, there's another potential problem. Although Microsoft has come up with an algorithm to test type safety, what happens if some other company implements a CLI, say, on Linux, and they don't use the same algorithm? You could end up in a situation in which code that is actually type-safe gets verified on one platform but not on another platform. To avoid this situation, the ECMA standard for the CLI contains a specification of the algorithm to be used to test type safety. And it is a requirement that if some piece of code will pass verification using this standard algorithm, then any conforming implementation of the CLI must also pass that code. Notice my careful wording here. I haven't said that any conforming implementation of the CLI must actually use this algorithm. It is perfectly acceptable for some organization to develop a CLI implementation that uses a more sophisticated algorithm, which is capable of identifying type-safe code that would fail the ECMA algorithm, provided that algorithm doesn't fail any code that would pass the ECMA algorithm. And it is likely that this will happen in future releases of the .NET Framework as Microsoft develops the verification process performed by the JIT compiler. So now the situation looks more like this:
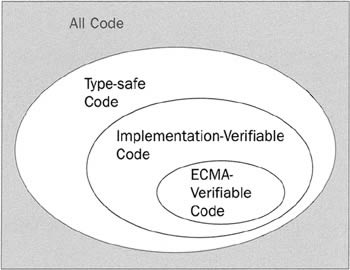
The existence of this standard algorithm is very important. It means that it is possible to design compilers that will only ever emit code that passes this algorithm (such as the VB compiler, or the C# compiler when the source code it processes doesn't have any unsafe blocks). It is then possible to guarantee that code generated by those compilers will pass type safety on any future implementation of the CLI.
The peverify.exe tool in theory uses the ECMA definition of verifiability when it checks your code. That's why peverify is such an important tool: if your code passes peverify, you know it will run on any compliant implementation of the CLI. However, as of version 1.0, there are some problems with peverify not picking up all errors (for example, it won't tell you if an explicit layout allows object references inside a type to overlap). For an absolutely complete check, you'll therefore need to run peverify, and run an assembly in a manner that does not give it SkipVerification permission (with the default security policy, this could be from a network share, for example).
Implementing Type Safety - The Practice
Now we've seen the theory of what verifying type safety should achieve, let's look at what the ECMA algorithm actually involves. We don't have space here to go into any rigorous kind of analysis - what I describe here is somewhat simplified, but it should give you an idea of how the verification process works. There are two aspects to the algorithm:
-
Checking evaluation stack types
-
Checking individual instructions Let's look at these separately.
Checking Evaluation Stack Types
This ensures that no problems can occur through one type being interpreted as another type. This is a classic way in which memory can become corrupted. For example, suppose that a slot in local memory has been declared as holding object, and we try to store an int32 in it:
.locals init (object, int32) // Other code ldloc.1 stloc.0
This code is syntactically correct IL, and it will pass validation. But the stloc.0 instruction will cause the int32 to be stored in a location that is supposed to hold an object reference. We now have an object reference that almost certainly does not now point to any valid object, since that int32 could have been storing any value. And the cause of the problem is clearly wrong types: the above code will fail verification at the stloc.0 instruction, on the grounds that the wrong data type is on the stack.
The great thing about this check is that it's really just an extension of the checks on evaluation stack state that are performed by the JIT compiler in order to validate code anyway. Recall that to validate code, the JIT compiler makes sure that it can identify the stack state at each point in the code, but it doesn't worry about whether that state is being used consistently. Hence adding this check in for verifiability doesn't add too much overhead to the JIT-compilation process.
Checking Individual Instructions
Checking an individual IL instruction is more interesting. Microsoft has carefully studied all the IL commands, to check all the possible effects of these commands. And the commands can be divided into three categories:
-
Some commands can never cause a program to violate memory. As an example, the ldloc.0 command is always type-safe. There is no way that the action of loading the first local variable onto the evaluation stack can possibly compromise memory integrity.
-
Some commands can in principle cause memory to be violated if they are used in a certain way, but it's easy to identify conditions under which those commands will always be safe.
-
There is a small group of commands that may violate memory, and for which there's no simple test that can be applied to how they are being used that will guarantee their safety. An example of this is the initblk command. initblk initializes a block of memory of a given size. Since the size is taken from the evaluation stack and could be huge, initblk could easily overwrite variables that it shouldn't be writing to.
You can probably guess what happens now. The verifier ignores instructions in the first category above. If it sees an instruction in the second category, then it checks if it has been used in one of the ways it knows about that guarantees type safety. If the instruction fails this test, then the method fails verification. And of course, if the verifier sees an instruction in the third category, then that's it. That block of code has failed verification straight away. In that case, as I mentioned earlier, what will happen is that the JIT compiler will insert code that will throw an exception if we do not have SkipVerification permission. Incidentally, that does mean that the method might be able to execute without this permission, provided that the flow of execution avoids the particular block of code in question.
We don't have space here to list details of which IL instruction falls into which category, but some information about each instruction is provided in the downloadable appendix. In addition, the Partition III document formally lists the exact situation in which each IL instruction is considered type-safe.
Note that, just as for validating code, the verification algorithm only examines types - it never considers values. It has to be this way, because verification happens at JIT-compile time, not when the code is being executed. So there's no easy way to tell what the values might be. For example, initblk might be being used in a context in which only a few bytes of memory to a particular local variable are being written. But the verifier has no way of knowing that.
One other point - you may wonder why we've not mentioned anything about arrays in connection with type safety. After all, array indices out of bounds represent one of the most common reasons for memory corruption. The reason is that array access in IL is controlled either through the array-related commands, newarr, ldelem.*, stelem.*, and ldlen, which perform their own bounds checking and throw an exception if an index out of bounds is detected, or through the System.Array class. Most of the methods of this class are internalcall methods (implemented within the CLR and similarly implemented to perform bounds checking). Either way, there is no danger of memory violations caused by array overruns. Hence arrays are simply not an issue as far as type safety is concerned.
EAN: 2147483647
Pages: 124