The ValueReference Type System
The Value/Reference Type System
In this section, we will delve into the .NET type system, focusing on the differences between value and reference types. We assume you're familiar with the basic principles of value and reference types, and examine how the two categories of types are actually implemented.
Reference Types
One of the important features of .NET is that reference types are self-describing. This means that in principle, the CLR need only have the address of an object in the managed heap in order to be able to find out everything about that object, including its type, what fields and methods it implements, how much memory the object occupies and how those fields are laid out in memory. This self-describing feature is important, and it is the reason why code like this will work:
// C# code object obj = GetSomeObjectFromSomewhere(); Type type = obj.GetType();
If you actually look at an object in memory you'll see it looks rather like this:

Note that this diagram is correct for version 1 of the framework. Microsoft does reserve the right to change the details in future versions, though the basic concepts as explained in this chapter are unlikely to change.
The reference to an object actually contains the first byte of a method table pointer - that is a four-byte address that points to something called a method table. Details of the method table are not documented, but we can expect that it is something like the vtable of unmanaged code. The method table is dependent only on the type, not the instance. Hence two instances of the same class will contain identical values for the method table pointer. The method table will contain addresses that allow the CLR to locate the entry points of methods implemented by this type, and in particular to invoke the correct override for virtual methods. It also permits the CLR to look up the information concerning the type and size of the object. It is this pointer to the method table that enables the object to be self-describing.
Immediately before the method table pointer we find another word, which is occupied by something called a sync block index. This is an index into a table of sync blocks that is used for synchronizing threads. We'll cover the full theory of how this works in Chapter 9. Suffice to say that if any thread requests a lock on this object then that object's sync block index will be modified to index into the table. In most cases, if you have not created a sync block, this word will contain zero (in fact, I'd say that for most applications, virtually all objects will have this word set to zero most of the time - most real applications have vast numbers of objects but only a few locks active at any one time).
Value Types
A value type is much simpler than a reference type and occupies less memory. It can be located either somewhere on the stack frame or, if it is declared to be a member field of a reference type, then it will be stored inline in the managed heap inside that reference type. In terms of memory layout it looks like this:
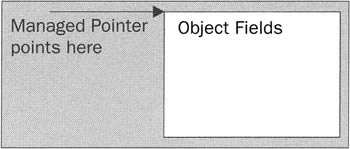
As the diagram shows, the value type contains only its fields. Compared to a reference type that contains the same fields, a value type saves 12 bytes: the method table pointer, the sync block index, and the object reference. 12 bytes might not be significant by itself, but if you have a lot of objects, those bytes can add up. This makes value types much more efficient for storing and manipulating data. There is also the saving that value types don't need to be garbage collected. But that all comes at the expense that these data structures are not self-describing. This fact might come as a surprise - after all, we have pretty much been brought up to believe that all .NET types are self-describing; that's a fundamental principle of .NET and .NET type safety. However, in the case of value types, the CLR has other means to find out what is occupying the memory:
-
For a value type that exists inline inside a reference type, the reference type is self-describing, and part of its definition will include the fact that this value type occupies a certain area of memory inside the reference object.
-
For a value type that exists on the stack frame, the class loader, as part of the JIT compilation process, emits tables that indicate what data types will be occupying what memory at various points in the code (these points are known as safe points for garbage collection). Recall that in the last chapter we emphasized that a requirement of valid IL is that the JIT compiler should be able to work out what's on the evaluation stack at each point in the code? Given that the JIT compiler has this information, you can probably see that emitting tables of what types occupy what memory isn't going to be that hard a task. When required, the CLR uses these tables to identify types. One example of where this facility is used is during garbage collection: the garbage collector needs to know what value types are stored where, so that it can locate references to objects that may be contained in those types. This all means, incidentally, that value types do still each have a method table, but there is no need for each instance to contain a pointer to it.
Boxed Types
Boxed types are formally recognized as a reference types, and in almost all respects they are treated as such. It's also important to understand that for many purposes the boxed type is regarded as a different type from the underlying value type, even though it will share the same metadata. You even declare a boxed type in IL in the same way as you declare an object; the following .locals directive declares two locals, a System.Drawing.Point instance, and a boxed instance of the same struct. The declaration of the reference to the boxed object uses the object keyword, in exactly the same manner as for declaring an object reference:
.locals(valuetype, [System.Drawing]System.Drawing.Point, object [System.Drawing]System.Drawing.Point)
There is one aspect in which boxed types are different from normal reference types, however. In general, instance and virtual methods on reference types are expected to be implemented on the assumption that the first parameter passed in (in other words, the this reference) is an object reference. On the other hand, instance methods on value types are expected to be implemented on the assumption that the first parameter is a managed pointer to the first item of data in the type itself. Since boxed types share the implementations of all their methods with the corresponding unboxed value types, this means, as we saw in the previous chapter, that you should not pass an object reference to a method on a boxed type. Instead, you should unbox the reference and pass in a managed pointer:
// stack contains a boxed reference to a Point instance unbox call string [System.Drawing]Point.ToString()
System.ValueType and System.Enum
System.ValueType and System.Enum have quite a strange status in .NET. The framework has a special knowledge of these types, and treats types derived from them in a way that is quite peculiar if you think about it. Derive from any other type and you get the reference type you've defined. But derive from either of these two classes and you get a (boxed) reference type and a stack-based value type. And although high-level programmers are accustomed to thinking of the value type as the 'real' type and the boxed type as some kind of rarely used mutation, at the IL/CLR level, you'd probably get a better understanding of what's really going on if you look at it the other way around - and view the boxed type as the genuine type that has been derived from ValueType or Enum, and the unboxed struct as a strange freeloader that you happen to get as a by-product.
For a start, as we mentioned briefly in Chapter 2, System.ValueType and System.Enum are actually reference types! This is a fact that often comes as a surprise to people exploring IL for the first time. However, it does make a lot of sense. For simplicity, we'll examine the situation for ValueType here, but exactly the same principles apply to System.Enum.
Moreover, since boxed types are derived from ValueType, we can do all the normal reference tricks with them. For example, a ValueType reference can refer to a boxed type:
.locals (valuetype int32, object [mscorlib]System.ValueType) ldloc.0 box int32 stloc.s 1 // Valid and verifiable
You can also call virtual methods, just as you would for a class. The only restriction, of course, is that the only virtual methods that can possibly exist on the boxed type are the ones defined in System.Object/System.ValueType:Equals(), GetHashCode(), and ToString().(Finalize() is also virtual, but you shouldn't be explicitly calling that method.)
ldc.i4.s 43 box int32 callvirt [mscorlib]System.ValueType.ToString() // Places the string "43" // on the stack ldc.i4.s 43 box int32 callvirt [mscorlib]System.Object.ToString() // Places the string "43" // on the stack ldc.i4.s 43 box int32 call [mscorlib]System.Object.ToString() // Places the string // "System.Object" on stack
But beware of this:
ldc.i4.s 43 box int32 unbox // You MUST unbox in this case callvirt [mscorlib]int32.ToString() // Places the string "43" on the stack
If we explicitly specify the method as a member of int32, we need to pass a managed pointer, not an object reference, to the method. And not only that - this last construct will fail verifiability. All this despite the fact that it's the same method that ultimately gets called.
The above code snippets show that having ValueType as a reference type works quite well. Indeed, if Microsoft had done the opposite and made ValueType a genuine value type, it would have actually constituted a syntax error in mscorlib.dll. The reason? The CLR requires all value types to have some finite non-zero size, since otherwise it would have - shall we say - an interesting task, figuring out how to reserve memory for them! Hence, you'll get a syntax error if you try to declare a value type that doesn't either have at least one field, or have a size specified with the .size directive. ValueType, of course, has neither.
Another corollary of this is that an unboxed value type doesn't really behave as if it derives from anything at all. It is simply a plain set of fields, along with some metadata that allows you to call methods against this set of fields. This is in marked contrast to the boxed type, which derives from ValueType, and has its own method table index and sync block index, just like a proper class.
Field Alignment
So far we have covered the overall view of what types look like in memory, but we haven't said anything about how the individual fields of a type are organized. This clearly will depend on the layout flag that is indicated for the class in the assembly - whether the class is marked as explicit, sequential, or auto. (Or, equivalently, if you are using a high-level language: whether the type has been decorated with StructLayoutAttribute, and what value the StructLayoutAttribute. Value property has been set to.)
Explicit layout is syntactically the most complicated to code up, but conceptually the simplest: the fields will be laid out at exactly the locations you specify in your code. The only proviso is that specifying offsets that overlap object references with other types will cause the class loader to refuse to load the type. Since this chapter is about concepts, not syntax, and since you can look up the syntax for the Struct Layout Attribute very easily in MSDN, we won't consider it further.
If you specify sequential layout, the fields will be laid out in the exact order of the class definition. However, they will not necessarily be packed next to each other: there may be some space between them. The reason for this is to do with something that is known as the byte alignment. The way modern hardware works, it is more efficient to load any primitive data type from memory into or from a register in the CPU if the data is aligned in a certain way in memory. And the rule is that the starting address of the data should be a multiple of the size of the data. What that means is that if you are trying to load an int16 (which occupies two bytes) from memory, then it's better if the starting address of that int16 is, for example, 2, 4, 6, 8, etc. If the data type is an int32 (four bytes) then it should be stored at an address 4, 8, 12, 16, etc., while an int64 or float64 (eight bytes) should be stored at locations 8, 16, 24, 32 etc. Values that are located at these optimal addresses are referred to as being naturally aligned or as having the correct byte alignment. If a machine needs to load or store data that is not aligned correctly (for example, if it needs to load an int16 that is located at address 36917), then the load process will take longer and might not be atomic. If a type is to be laid out sequentially, that means that the fields will appear in the same order in which they have been defined, but that padding may be inserted between them in order to ensure that each individual field is naturally aligned. This is the same scheme that is used by the VC6 compiler, which means that if you want types to be able to be passed directly to unmanaged code compiled from Visual C++ without having to be marshaled, sequential layout is the way to do it. (However, this isn't guaranteed to work with code compiled with other compilers, since other compilers might not lay out structures in the same way.) Types that have been laid out so that they require no marshaling are termed isomorphic.
Auto layout is very similar to sequential, except that the class loader will not feel under any obligation to lay out the fields in the order in which they were defined. Instead, it will reorder them to find a layout that maintains byte alignment while minimizing the amount of memory that is wasted on padding.
Generally speaking, if your application only uses managed code, you will usually get the best performance using the auto layout. On the other hand, if you're calling into unmanaged code, you may find that sequential layout for the types being passed to the unmanaged code serves you better because of the saving in marshaling.
Using C++ to Access Managed Heap Memory Directly
We are now going to present some code in C++ that defines and instantiates a couple of simple classes, and uses unmanaged pointers to locate the objects on the managed heap and examine the memory they occupy. I've picked C++ for this example because C++ offers the greatest freedom to manipulate pointers. C# allows some use of pointers, but even in unsafe code blocks it places restrictions on their use, which would be awkward in the context of this example, while VB does not allow any direct pointer manipulation. Apart from illustrating some of the principles we've just been discussing, this code will demonstrate some of the techniques you can use if you want to get at the memory occupied by an object directly.
Bear in mind though that aspects of this code are highly unsafe. The code won't just fail verifiability, but if you use this technique in other code, you risk your code breaking if Microsoft changes the layout of fields. However, if you do want to do some deep digging into the internals of .NET, this code demonstrates a useful technique.
The code is contained in a sample called ObjectDig.
To start off with, we define two classes:
__gc class BigClass { public: int x; // = IL int32 double d; // = IL float64 bool b; // = IL bool short s; // = IL int16 String *sz; // = IL object reference }; __gc class LittleClass { public: int x; int y; };
These classes have no purpose other than to illustrate memory layout. LittleClass contains only two fields of the same size, and so there is no reason for the loader to reorder the fields. BigClass, on the other hand, contains fields of several different sizes, and we would expect the loader to rearrange these to maintain type alignment while keeping BigClass objects as small as possible. Normally, the fields will be arranged in decreasing size order, which means we'd expect the actual order of them to be d (which occupies eight bytes), x and sz (four bytes each), s (two bytes), and b (one byte).
Before we instantiate these classes, we need a helper global method that can display memory contents in a user-friendly format:
void WriteMemoryContents(unsigned char *startAddress, int nBytes) { for (int i=0; i<nBytes; i++) { if (i % 8 == 0) Console::Write("Address {0:x}: ", __box((int)(startAddress) + i)); if (startAddress[i] < 16) Console::Write("0"); Console::Write("{0:x} "'__box(startAddress[i])); if (i % 4 == 3) Console::Write(" "); if (i % 8 == 7) Console::WriteLine(); } Console::WriteLine(); }
This method takes a start address, supplied as unsigned char*, and the number of bytes from this address to write out. The various if statements are simply to format the data in a readable way. It displays each byte of memory in hex format, with eight bytes to a line on the console window, and a bigger space after the fourth byte for readability. Each console line starts off by indicating the address of the first of the eight bytes.
Now for the interesting code:
int _tmain(void) { BigClass __pin *obj1 = new BigClass; obj1->x = 20; obj1->d = 3,455; obj1->b = true; obj1->s = 24; obj1->sz = S"Hello"; LittleClass __pin *obj2 = new LittleClass; obj2->x = 21; obj2->y = 31; Littleclass __pin *obj3 = new LittleClass; obj3->x = 22; obj3->y = 32; unsigned char *x = (unsigned char*)(obj1); Console::WriteLine("Memory starting at &obj1 - 4:"); WriteMemoryContents(x - 4, 60); Console::WriteLine("Memory starting at obj1->s:"); x = (unsigned char*)(&{obj1->s)); WriteMemoryContents(x, 2); Console::WriteLine("Memory starting at obj1->sz:"); x = (unsigned char*)(&(obj1->sz)); WriteMemoryContents(x, 4); return 0; }
We start off by instantiating one BigClass object followed by two LittleClass objects, and initialize the fields to values that we'll be able to identify when we examine the memory. Note that we declare all the objects using the __pin keyword. This does two things. Firstly, it ensures that the garbage collector won't move the object while we are examining its memory. This is unlikely in such a small program, but is a good safety feature, since having objects moved around would make it hard for us to inspect the correct memory contents! More importantly for our purposes, we have to declare obj1 as a pinned reference because otherwise the C++ compiler won't let us cast it to the unmanaged pointer that we will need in order to examine memory. The C++ compiler lets us get away with a lot in terms of trusting us to know what we're doing, but it does have limits to its trust! Note also the objects will be automatically unpinned when the references go out of scope as the object returns.
Having set up the variables, we declare an unsigned char* variable, and initialize it to point to the first object allocated. This line is the key piece of code:
unsigned char *x = (unsigned char*)(objl);
The key point about this line is that obj1 is, in IL terms, an object reference. This means it will point to the actual beginning of the object - its method table, not to its fields. By casting it to an unmanaged pointer, we have a pointer that we can basically do whatever we like with, but which we know currently points to the managed object's method table. Now it's a simple line to call our WriteMemoryContents() helper function to display the memory not only for obj1, but also for obj2 and obj3, which follow it. Notice, though, that we pass WriteMemoryContents() the address four bytes below the method table pointer, to make sure we include the sync block index in our output:
unsigned char *x = (unsigned char*)(obj1); Console::WriteLine("Memory starting at &obj1:"); WriteMemoryContents(x - 4, 60); I've asked for 60 (= 0x3c) bytes of memory to be displayed. I'm cheating here a bit and using the fact that I happen to know this is exactly how much memory the objects are going to occupy. In most cases, asking for a bit too much memory to be displayed won't be a problem - you'll just get some extra bytes of garbage at the end. However, there is a small chance that if we attempt to display unused memory that crosses a page boundary, we'll get a memory access violation due to attempting to access memory that hasn't been committed. The issue of how memory is managed and what it means for memory to be committed is explored further in Chapter 7.
Finally, we call WriteMemoryContents() twice more, but this time we pass it unmanaged pointers that have been set up to point to particular fields in the obj1 instance. This will give us a confirmation of which memory is being used to store which fields, and also illustrates how to get an unmanaged pointer to a field directly in C++.
Running the ObjectDig sample on my computer gives these results:
Memory starting at &obj1-4: Address c71b64: 00 00 00 00 5c 53 94 00 Address c71b6c: a4 70 3d 0a d7 a3 0b 40 Address c71b74: 4c 1b c7 00 14 00 00 00 Address c71b7c: 18 00 01 00 00 00 00 00 Address c71b84: e0 53 94 00 15 00 00 00 Address c71b8c: 1f 00 00 00 00 00 00 00 Address c71b94: e0 53 94 00 16 00 00 00 Address c71b9c: 20 00 00 00 Memory starting at obj1->s: Address c71b7c: 18 00 Memory starting at obj1->sz: Address c71b74: 4c 1b c7 00 Press any key to continue
These results might look at first sight like garbage, but they do show the correct object layout. The first DWORD (I use DWORD as a convenient shorthand for a set of 4 bytes), starting at address 0xc71b64, contains the sync block index. This is zero at present, since there are no locks on this object in operation. The next DWORD (at address 0xc71b68) contains the address of the method table, while the following two DWORDs contain the double, obj1->d - since the double is stored in exponent-mantissa format we're not going to be able to easily relate the bytes there to the represented value of 3.455. The fifth DWORD (at 0xc71b74) is what we are expecting to be the sz pointer to the "Hello" string. It is - that's confirmed by the later display of obj1->sz, which contains the same value, 00c71b4c. (Note that the lowest order byte comes first in memory, little-endian format, so we reverse the order of the bytes in giving the full address.)
Next we get to some data that we can easily identify. The sixth DWORD, starting at address 0xc71b78, contains 0x00000014, which is just 20 in decimal. That's what we set the obj1->x field to. Now we get two even smaller fields, which can be placed in one DWORD between them. The following two bytes contain the short, s, initialized to 24 (0x0018). Then comes the bool, occupying one byte and set to the value unity. The following single byte, which contains zero, is just padding. We can't use it for anything else without breaking byte alignment, since there are no other one-byte fields in the object.
That's the end of the obj1 instance, so the next DWORD will contain the sync block index of the next object allocated - obj2. You won't be surprised to find this sync block index contains zero. This is followed by the address of the LittleObject method table. Reading this DWORD, we see the address of this method table is 0x009453e0. Looking further back in the output, the BigClass method table was indicated to be at 0x0094535c, which confirms that the two method tables are located fairly close together, as you'd expect. You can carry on this analysis to pick out the fields of obj2 and obj3, noting that they have the same method table address.
If you do try any code like this, do bear in mind that the layout of objects may change with future versions of .NET, so don't write code that relies on a certain layout. If you want to access memory in an object directly (which you might want to do so you can pass it to unmanaged code and avoid the marshaling overhead), the recommended way of doing it is by accessing individual fields. In other words, doing it this way:
short *pshort = &(obj1->s); In C#, the restrictions on use of pointers to objects on the managed heap ensure that this is the only way that you can retrieve pointers to data on the heap.
This code will be translated into an IL ldflda command, which will continue to work correctly, no matter how the fields in the object are laid out by the loader. If you want your code to be robust against future implementations of .NET, you should obtain the address of each field separately, and only use each address to examine or manipulate memory within that field. With this proviso, directly accessing memory on the managed heap can be a good way to improve performance in some situations. You can use it to perform direct manipulations on memory, or to pass data to unmanaged code. Having said that, this kind of micro-optimization is only worth doing in a small number of cases. Usually you're better off sticking to robust type-safe code. Also, do make sure that you pin the objects concerned for as short a time as possible, otherwise you risk impairing the performance of the garbage collector, which might more than cancel out any performance gains from the direct memory access. Correct managing of the pinning looks something like this in C++:
MyClass __gc* __pin obj = DoSomethingToGetObjReference(); try { // Do your processing with obj } finally { obj = NULL; }
In C#, correct management of pinning means making sure that the C# fixed block extends over the minimum amount of code:
fixed (MyClass obj = DoSomethingToGetMemberFieldReference()) { // Do your manipulation of fields in obj here }
Incidentally, if you are marshaling isomorphic data via P/Invoke, the CLR will just give the unmanaged code the address of the original data rather than copying it, and will automatically pin this data for the duration of the P/Invoke call.
EAN: 2147483647
Pages: 124