Threading
 | |||||||||||
| Chapter 5 - C# and the Base Classes | |
| bySimon Robinsonet al. | |
| Wrox Press 2002 | |
In this section, we will look at the support that C# and the .NET base classes offer for developing applications that employ multiple threads. We will briefly examine the Thread class, through which much of the threading support takes place, and develop a couple of examples that illustrate threading principles. From there, we will examine some of the issues that arise when we consider thread synchronization. Due to the complexity of the subject, the emphasis will be on understanding some of the basic principles involved - we won't really go on to develop any real applications.
A thread is a sequence of execution in a program. For all programs that we have written so far in C#, there has been one entry point - the Main() method. Execution has started with the first statement in the Main() method and has continued until that method returns.
This program structure is all very well for programs in which there is one identifiable sequence of tasks , but often a program actually needs to be doing more than one thing at the same time. One familiar situation in which this occurs is when you have started up Internet Explorer and are getting increasingly frustrated as some page takes ages to load. Eventually, you get so fed up (if you're like me, after about 2 seconds!) that you click the Back button or type in some other URL to look at instead. For this to work, Internet Explorer must be doing at least three things:
-
Grabbing the data for the page as it gets returned from the Internet, along with any accompanying files
-
Rendering the page
-
Watching for any user input that might indicate the user wants IE to do something else instead
More generally , the same situation applies to any case where a program is performing some task while at the same time displaying a dialog box that gives you the chance to cancel the task at any time.
Let's look at the example with Internet Explorer in more detail. We will simplify the problem a bit by ignoring the task of storing the data as it arrives from the Internet, and assume that Internet Explorer is simply faced with two tasks:
-
Displaying the page
-
Watching for user input
We will assume for the sake of argument that this is a page that takes a long time to display; it might have some processor- intensive JavaScript in it, or it might contain a marquee element in it that needs to be continually updated. One way that you could approach the situation is to write a method that does a little bit of work in rendering the page. After a short time, let us say a twentieth of a second, the method checks to see if there has been any user input. If there has been, this is processed (which may mean canceling the rendering task). Otherwise, the method carries on rendering the page for another twentieth of the second.
This approach would work, but it is going to be a very complicated method to implement. More seriously, it totally ignores the event-based architecture of Windows . Recall from our coverage of events in the last chapter that if any user input arrives, the system will want to notify the application by raising an event. Let's modify our method to allow Windows to use events:
-
We will write an event handler that responds to user input. The response may include setting some flag to indicate that rendering should stop.
-
We will write a method that handles the rendering. This method is designed to be executed whenever we are not doing anything else.
This solution is better, because it works with the Windows event architecture, but personally I wouldn't like to be the one who has to write this rendering method. Look at what it has to do. For a start, it will have to time itself carefully . While this method is running, the computer cannot respond to any user input. That means this method will have to make a note of the time that it gets called, continue monitoring the time as it works, and as soon as a fairly suitable period of time has elapsed (the absolute maximum to retain user responsiveness would be a bit less than a tenth of a second), should return. Not only that, but before this method returns, it will need to store the exact state of where it had got up to, so that the next time it is called it can carry on from there. It is certainly possible to write a method that would do that, and in the days of Windows 3.1, that's exactly what you would have to do to handle this sort of situation. Luckily, NT3.1 and then Windows 95 brought multi-threaded processes, which are a far more convenient way of solving problems like this.
Applications with Multiple Threads
The above example illustrates the situation in which an application needs to do more than one thing, so the obvious solution is to give the application more than one thread of execution. As we said, a thread represents the sequence of instructions that the computer executes. There is no reason why an application should only have one such sequence. In fact, it can have as many as you want. All that is required is that each time you create a new thread of execution, you indicate a method at which execution should start. The first thread in an application always starts at the Main() method because the first thread is started by the .NET runtime, and Main() is the method that the .NET runtime picks. Subsequent threads will be started internally by your application, which means that your application gets to choose where those threads starts.
How Does This Work?
So far, we have spoken rather loosely about threads happening at the same time. In fact, one processor can only be doing one thing at a time. If you have a multi-processor system, then it is theoretically possible for more than one instruction to be executed simultaneously, one on each processor, but for the majority of us who work on single processor computers, things just don't happen simultaneously . What actually happens is that the Windows operating system gives the appearance of many things taking place at the same time by a procedure known as pre emptive multitasking .
What pre-emptive multitasking means is that Windows picks a thread in some process and allows that thread to run for a short period of time. Microsoft hasn't documented how long this period is, because it is one of those internal operating system parameters that it wants to be free to tweak as Windows evolves in order to maintain optimum performance. In any case, it is not the kind of information you need to know to run the Windows applications. In human terms, this time is very short - certainly no more than milliseconds . It is known as the thread's time slice . When the time slice is finished, Windows takes control back and picks another thread, which will then be allocated a time slice. These time slices are so short that we get the illusion of lots of things happening simultaneously.
Even when your application only has one thread, this process of pre-emptive multitasking is going on because there are many other processes running on the system, and each process needs to be given time slices for each of its threads. That's how, when you have lots of windows on your screen, each one representing a different process, you can still click on any of them and have it appear to respond straight away. The response isn't instantaneous - it happens the next time that the thread in the relevant process that is responsible for handling user input from that window gets a time slice. However, unless the system is very busy, the wait before that happens is so short that you don't notice it.
Manipulating Threads
Threads are manipulated using the class Thread , which can be found in the System.Threading namespace. A thread instance represents one thread - one sequence of execution. You can create another thread by simply instantiating a thread object.
Starting a Thread
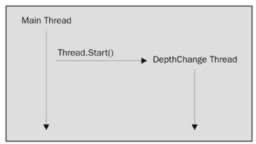
To make the following code snippets more concrete, let's suppose you are writing a graphics image editor, and the user requests to change the color depth of the image. I've picked this example because for a large image this can take a while to perform. It's the sort of situation where you'd probably create a separate thread to do the processing so that you don't tie up the user interface while the color depth change is happening. You'd start by instantiating a thread object like this:
// entryPoint has been declared previously as a delegate // of type ThreadStart Thread depthChangeThread = new Thread(entryPoint);
Here we have given the variable the name depthChangeThread .
Additional threads that are created within an application in order to perform some task are often known as worker threads .
The above code shows that the Thread constructor requires one parameter, which is used to indicate the entry point of the thread - that is, the method at which the thread starts executing. Since we are passing in the details of a method, this is a situation that calls for the use of delegates. In fact, a delegate has already been defined in the System.Threading class. It is called ThreadStart , and its signature looks like this:
public delegate void ThreadStart(); The parameter we pass to the constructor must be a delegate of this type.
After doing this, however, the new thread isn't actually doing anything so far. It is simply sitting there waiting to be started. We start a thread by calling the Thread.Start() method.
Suppose we have a method, ChangeColorDepth() , which does this processing:
void ChangeColorDepth() { // processing to change color depth of image }
You would arrange for this processing to be performed with this code:
ThreadStart entryPoint = new ThreadStart(ChangeColorDepth); Thread depthChangeThread = new Thread(entryPoint); depthChangeThread.Name = "Depth Change Thread"; depthChangeThread.Start();
After this point, both threads will be running simultaneously.
In this code, we have also assigned a user-friendly name to the thread using the Thread.Name property. It's not necessary to do this, but it can be useful.
Note that because the thread entry point ( ChangeColorDepth() in this example) cannot take any parameters, you will have to find some other means of passing in any information that the method needs. The most obvious way would be to use member fields of whatever class this method is a member. Also, the method cannot return anything. (Where would any return value be returned to? As soon as this method returns, the thread that is running it will terminate, so there is nothing around to receive any return value and we can hardly return it to the thread that invoked this thread, since that thread will presumably be busy doing something else.)
Once you have started another thread, you can also suspend, resume, or abort it. Suspending a thread means putting it to sleep - the thread will simply not run for a period, which means it will not take up any processor time. It can later be resumed, which means it will simply carry on from the point at which it was suspended . If a thread is aborted, then it will stop running for good. Windows will permanently destroy all data that it maintains relating to that thread, so the thread cannot subsequently be restarted.
Continuing the image editor example, we will assume that for some reason the user interface thread displays a dialog giving the user a chance to temporarily suspend the conversion process (it is not usual for a user to want to do this, but it is only an example; a more realistic example might be the user pausing the playing of a sound or video file). We would code the response like this in the main thread:
depthChangeThread.Suspend(); And if the user subsequently asked for the processing to resume:
depthChangeThread.Resume(); Finally, if the user (more realistically ) decided that they didn't want to do the conversion after all, and chose to cancel it:
depthChangeThread.Abort(); Note that the Suspend() and Abort() methods do not necessarily work instantly. In the case of Suspend() , .NET may allow the thread being suspended to execute a few more instructions in order to reach a point at which .NET regards the thread as safely suspendable. This is for technical reasons to do with ensuring the correct operation of the garbage collector, and full details are in the MSDN documentation. In the case of aborting a thread, the Abort() method actually works by throwing a ThreadAbortException in the affected thread. ThreadAbortException is a special exception class that is never handled. The point of doing it this way is that it means that if that thread is currently executing code inside try blocks, any associated finally blocks will be executed before the thread is actually killed . This ensures that any appropriate cleaning up of resources can be done, and also gives the thread a chance to make sure that any data it was manipulating (for example, fields of a class instance that will remain around after the thread dies) is left in a valid state.
Prior to .NET, aborting a thread in this way was not recommended except in extreme cases because the affected thread simply got killed immediately, which meant that any data it was manipulating could be left in an invalid state, and any resources the thread was using would be left open . The exception mechanism used by .NET in this situation means that aborting threads is safer and so is acceptable programming practice.
Although this exception mechanism makes aborting a thread safe, it does mean that aborting a thread might actually take some time, since theoretically there is no limit on how long code in a finally block could take to execute. Due to this, after aborting a thread, you might want to wait until the thread has actually been killed before continuing any processing, if any of your subsequent processing relies on the other thread having been killed. You can wait for a thread to terminate by calling the Join() method:
depthChangeThread.Abort(); depthChangeThread.Join();
Join() also has other overloads that allow you to specify a time limit on how long you are prepared to wait. If the time limit is reached, then execution will simply continue anyway. If no time limit is specified, then the thread that is waiting will wait for as long as it needs to.
The above coded snippets will show one thread performing actions on another thread (or at least in the case of Join() , waiting for another thread). However, what happens if the main thread wants to perform some actions on itself? In order to do this it needs a reference to a thread object that represents its own thread. It can get such a reference using a static property, CurrentThread , of the Thread class:
Thread myOwnThread = Thread.CurrentThread; Thread is actually a slightly unusual class to manipulate because there is always one thread present even before you instantiate any others - the thread that you are currently executing. This means that there are two different ways that you can manipulate the class:
-
You can instantiate a thread object, which will then represent a running thread, and whose instance members apply to that running thread.
-
You can call any of a number of static methods. These generally apply to the thread you are actually calling the method from.
One static method you may wish to call is Sleep() . This simply puts the running thread to sleep for a set period of time, after which it will continue.
The ThreadPlayaround Sample
We are going to start by illustrating how to use threads with a small example, called ThreadPlayaround . The aim of this example is to give us a feel for how manipulating threads works, so it is not intended to illustrate any realistic programming situations. We are simply going to kick off a couple of threads and see what happens.
The core of the ThreadPlayaround sample is a short method, DisplayNumbers() , that counts up to a large number, displaying how far it has counted up to every so often. DisplayNumbers() also starts by displaying the name and culture of the thread that it is being run on:
static void DisplayNumbers() { Thread thisThread = Thread.CurrentThread; string name = thisThread.Name; Console.WriteLine("Starting thread: " + name); Console.WriteLine(name + ": Current Culture = " + thisThread.CurrentCulture); for (int i=1 ; i<= 8*interval ; i++) { if (i%interval == 0) Console.WriteLine(name + ": count has reached " + i); } }
How far the count runs up to depends on interval , which is a field whose value is typed in by the user. If the user types in 100 , then we will count up to 800, displaying the values 100 , 200 , 300 , 400 , 500 , 600 , 700 , and 800 . If the user types in 1000 then we will count up to 8000, displaying the values 1000 , 2000 , 3000 , 4000 , 5000 , 6000 , 7000 , and 8000 along the way, and so on. This might all seem like a pointless exercise, but the purpose of it is to tie up the processor for a period while allowing us to see how far the processor is progressing with its task.
What ThreadPlayaround does is to start a second worker thread, which will run DisplayNumbers() , but immediately after starting the worker thread, the main thread begins executing the same method. This means that we should see both counts happening at the same time.
The Main() method for ThreadPlayaround and its containing class looks like this:
class EntryPoint { static int interval; static void Main() { Console.Write("Interval to display results at?> "); interval = int.Parse(Console.ReadLine()); Thread thisThread = Thread.CurrentThread; thisThread.Name = "Main Thread"; ThreadStart workerStart = new ThreadStart(StartMethod); Thread workerThread = new Thread(workerStart); workerThread.Name = "Worker"; workerThread.Start(); DisplayNumbers(); Console.WriteLine("Main Thread Finished"); Console.ReadLine(); }
We have shown the start of the class declaration here so that we can see that interval is a static field of this class. In the Main() method, we first ask the user for the interval. Then, we retrieve a reference to the thread object that represents the main thread - this is done so that we can give this thread a name so that we can see what's going on in the output.
Next, we create the worker thread, set its name, and start it off, passing it a delegate that indicates that the method it must start in is a method called workerStart . Finally, we call the DisplayNumbers() method to start counting. The entry point for the worker thread is this:
static void StartMethod() { DisplayNumbers(); Console.WriteLine("Worker Thread Finished"); }
Note that all these methods are static methods in the same class, EntryPoint . Note also that the two counts will take place entirely separately, since the variable i in the DisplayNumbers() method used to do the counting is a local variable. Local variables are not only scoped to the method they are defined in, but are also visible only to the thread that is executing that method. If another thread starts executing the same method, than that thread will get its own copy of the local variables . We will start by running the code, and selecting a relatively small value of 100 for the interval:
ThreadPlayaround Interval to display results at?> 100 Starting thread: Main Thread Main Thread: Current Culture = en-GB Main Thread: count has reached 100 Main Thread: count has reached 200 Main Thread: count has reached 300 Main Thread: count has reached 400 Main Thread: count has reached 500 Main Thread: count has reached 600 Main Thread: count has reached 700 Main Thread: count has reached 800 Main Thread Finished Starting thread: Worker Worker: Current Culture = en-GB Worker: count has reached 100 Worker: count has reached 200 Worker: count has reached 300 Worker: count has reached 400 Worker: count has reached 500 Worker: count has reached 600 Worker: count has reached 700 Worker: count has reached 800 Worker Thread Finished
As far as threads working in parallel are concerned , this doesn't immediately look like it's working too well! We see that the main thread starts, counts up to 800 and then claims to finish. The worker thread then starts and runs through separately.
The problem here is actually that starting a thread is quite a major process. After instantiating the new thread, the main thread hits this line of code:
workerThread.Start(); This call to Thread.Start() basically informs Windows that the new thread is to be started, then immediately returns. While we are counting up to 800, Windows is busily making the arrangements for the thread to be started. This internally means, among other things, allocating various resources for the thread, and performing various security checks. By the time the new thread is actually starting up, the main thread has finished its work!
We can solve this problem by simply choosing a larger interval, so that both threads spend longer in the DisplayNumbers() method. We'll try 1000000 this time:
ThreadPlayaround Interval to display results at?> 1000000 Starting thread: Main Thread Main Thread: Current Culture = en-GB Main Thread: count has reached 1000000 Starting thread: Worker Worker: Current Culture = en-GB Main Thread: count has reached 2000000 Worker: count has reached 1000000 Main Thread: count has reached 3000000 Worker: count has reached 2000000 Main Thread: count has reached 4000000 Worker: count has reached 3000000 Main Thread: count has reached 5000000 Main Thread: count has reached 6000000 Worker: count has reached 4000000 Main Thread: count has reached 7000000 Worker: count has reached 5000000 Main Thread: count has reached 8000000 Main Thread Finished Worker: count has reached 6000000 Worker: count has reached 7000000 Worker: count has reached 8000000 Worker Thread Finished
Now we can see the threads really working in parallel. The main thread starts and counts up to one million. At some point, while the main thread is counting the next million numbers , the worker thread starts off, and from then on, the two threads progress at the same rate until they both finish.
It is important to understand that unless you are running a multi-processor computer, using two threads in a CPU-intensive task will not have saved any time. On my single-processor machine, having both threads count up to 8 million will have taken just as long as having one thread count up to 16 million. Arguably, it will take slightly longer, since with the extra thread around, the operating system has to do a little bit more thread switching, but this difference will be negligible. The advantage of using more than one thread is two-fold. First, you gain responsiveness, in that one of the threads could be dealing with user input while the other thread does some work behind the scenes. Second, you will save time if one or more threads is doing something that doesn't involve CPU time, such as waiting for data to be retrieved from the Internet, because the other threads can carry out their processing while the inactive thread(s) are waiting.
Thread Priorities
It is possible to assign different priorities to different threads within a process. In general, a thread will not be allocated any time slices if there are any higher priority threads working. The advantage of this is that you can guarantee user responsiveness by assigning a slightly higher priority to a thread that handles receiving user input. For most of the time, such a thread will have nothing to do, and the other threads can carry on their work. However, if the user does anything, this thread will immediately take priority over other threads in your application for the short time that it spends handling the event.
High priority threads can completely block threads of lower priority, so you should be careful about changing thread priorities. The thread priorities are defined as values of the ThreadPriority enumeration. The possible values are Highest , AboveNormal , Normal , BelowNormal , Lowest .
You should note that each process has a base priority, and that these values are relative to the priority of your process. Giving a thread a higher priority may ensure that it gets priority over other threads in that process, but there may still be other processes running on the system whose threads get an even higher priority. Windows tends to give a higher priority to its own operating system threads.
We can see the effect of changing a thread priority by making the following change to the Main() method in the ThreadPlayaround sample:
ThreadStart workerStart = new ThreadStart(StartMethod); Thread workerThread = new Thread(workerStart); workerThread.Name = "Worker"; workerThread.Priority = ThreadPriority.AboveNormal; workerThread.Start(); What we have done is indicate that the worker thread should have a slightly higher priority than the main thread. The result is dramatic:
ThreadPlayaroundWithPriorities Interval to display results at?> 1000000 Starting thread: Main Thread Main Thread: Current Culture = en-GB Starting thread: Worker Worker: Current Culture = en-GB Main Thread: count has reached 1000000 Worker: count has reached 1000000 Worker: count has reached 2000000 Worker: count has reached 3000000 Worker: count has reached 4000000 Worker: count has reached 5000000 Worker: count has reached 6000000 Worker: count has reached 7000000 Worker: count has reached 8000000 Worker Thread Finished Main Thread: count has reached 2000000 Main Thread: count has reached 3000000 Main Thread: count has reached 4000000 Main Thread: count has reached 5000000 Main Thread: count has reached 6000000 Main Thread: count has reached 7000000 Main Thread: count has reached 8000000 Main Thread Finished
This shows that when the worker thread has an AboveNormal priority, the main thread scarcely gets a look-in once the worker thread has started.
Synchronization
One crucial aspect of working with threads is the synchronization of access to any variables which more than one thread has access to. What we mean by synchronization is that only one thread should be able to access the variable at any one time. If we do not ensure that access to variables is synchronized, then subtle bugs can result. In this section, we will briefly review some of the main issues involved.
What is Synchronization?
The issue of synchronization arises because what looks like a single statement in your C# sourcecode in most cases will translate into many statements in the final compiled assembly language machine code. Take for example the statement:
message += ", there"; // message is a string that contains "Hello" This statement looks syntactically in C# like one statement, but it actually involves a large number of operations when the code is being executed. Memory will need to be allocated to store the new longer string, the variable message will need to be set to refer to the new memory, the actual text will need to be copied , and so on.
Obviously, we've exaggerated the case here by picking a string - one of the more complex data types - as our example, but even when performing arithmetic operations on primitive numeric types, there is quite often more going on behind the scenes than you would imagine from looking at the C# code. In particular, many operations cannot be carried out directly on variables stored in memory locations, and their values have to be separately copied into special locations in the processor known as registers .
In any situation where a single C# statement translates into more than one native machine code command, it is quite possible that the thread's time slice might end in the middle of executing that 'statement' process. If this happens, then another thread in the same process may be given a time slice, and, if access to variables involved with that statement (message in the above example) is not synchronized, this other thread may attempt to read or write to the same variables. With our example, was the other thread intended to see the new value of message or the old value?
The problems can get worse than this, too. The statement we used in our example was relatively simple, but in a more complicated statement, some variable might have an undefined value for a brief period, while the statement is being executed. If another thread attempts to read that value in that instant, then it may simply read garbage. More seriously, if two threads simultaneously try to write data to the same variable, then it is almost certain that that variable will contain an incorrect value afterwards.
Synchronization was not an issue that affects the ThreadPlayAround sample, because both threads used mostly local variables. The only variable that both threads had access to was the Interval field, but this field was initialized by the main thread before any other thread started, and subsequently only ever read from either thread, so there was still not a problem. Synchronization issues only arise if at least one thread may be writing to a variable while other threads may be either reading or writing to it.
Fortunately, C# provides an extremely easy way of synchronizing access to variables, and unusually for this chapter, there's a C# language keyword that does it - lock . You use lock like this:
lock (x) { DoSomething(); }
What the lock statement does is wrap an object known as a mutual exclusion lock , or mutex , around the variable in the round brackets. The mutex will remain in place while the compound statement attached to the lock keyword is executed. While the mutex is wrapped around a variable, no other thread is permitted access to that variable. We can see this with the above code; the compound statement will execute, and eventually this thread will lose its time slice. If the next thread to gain the time slice attempts to access the variable x , access to the variable will be denied . Instead, Windows will simply put the thread to sleep until the mutex has been released.
The mutex is the simplest of a number of mechanisms that can be used to control access to variables. We don't have the space to go into the others here, but we will mention that they are all controlled through the .NET bass class System.Threading.Monitor . In fact, the C# lock statement is simply a C# syntax wrapper around a couple of method calls to this class.
In general, you should synchronize variables wherever there is a risk that any thread might try writing to a variable at the same time as other threads are trying to read from or write to the same variable. We don't have space here to cover the details of thread synchronization, but we will point out that it is a fairly big topic in its own right. Here, we will simply confine ourselves to pointing out a couple of the potential pitfalls.
Synchronization Issues
Synchronizing threads is vitally important in multi-threaded applications. However, it's an area in which it is important to work carefully because a number of subtle and hard to detect bugs can easily arise, in particular deadlocks and race conditions .
Don't Overuse Synchronization
While thread synchronization is important, it is important to use it only where it is necessary, because it can hurt performance. This is for two reasons. First, there is some overhead associated with actually putting a lock on an object and taking it off, though this is admittedly minimal. Second, and more importantly, the more thread synchronization you have, the more threads can get held up waiting for objects to be released. Remember that if one thread holds a lock on any object, any other thread that needs to access that object will simply halt execution until the lock is released. It is important, therefore, that you place as little code inside lock blocks as you can without causing thread synchronization bugs. In one sense, you can think of lock statements as temporarily disabling the multi-threading ability of an application, and therefore temporarily removing all the benefits of multi-threading .
On the other hand, it has to be said that the dangers of using synchronization too much (performance and responsiveness go down) are not as great as the dangers associated with not using synchronization when you need it (subtle run-time bugs that are very hard to track down).
Deadlocks
A deadlock (or a deadly embrace) is a bug that can occur when two threads both need to access resources that are locked by each other. Suppose one thread is running the following code, where a and b are two object references that both threads have access to:
lock (a) { // do something lock (b) { // do something } }
At the same time another thread is running this code:
lock (b) { // do something lock (a) { // do something } }
Depending on the times that the threads hit the various statements, the following scenario is quite possible: the first thread acquires a lock on a , while at about the same time the second thread acquires a lock on b . A short time later, thread A hits the lock(b) statement, and immediately goes to sleep, waiting for the lock on b to be released. Soon afterwards, the second thread hits its lock(a) statement and also puts itself to sleep, ready for Windows to wake it up the instant the lock on a gets released. Unfortunately, the lock on a is never going to be released because the first thread, which owns this lock, is sleeping and won't wake up until the lock on b gets released, which won't happen until the second thread wakes up. The result is deadlock. Both threads just permanently sit there doing nothing, each waiting for the other thread to release its lock. This kind of problem can cause an entire application to just hang, so that you can't do anything with it apart from use the Task Manager to just terminate the entire process.
In this situation, it is not possible for another thread to release the locks; a mutual exclusion lock can only be released by the thread that claimed the lock in the first place.
Deadlocks can usually be avoided by having both threads claim locks on objects in the same order. In the above example, if the second thread claimed the locks in the same order as the first thread, a first, then b , then whichever thread got the lock on a first would completely finish its task, then the other thread would start. This way, no deadlock can occur.
You might think that it is easy to avoid coding up deadlocks - after all, in the code shown above, it looks fairly obvious that a deadlock could occur so you probably wouldn't write that code in the first place, but remember that different locks can occur in different method calls. With this example, the first thread might actually be executing this code:
lock (a) { // do bits of processing CallSomeMethod() }
Here, CallSomeMethod() might call other methods, and so on, and buried in there somewhere is a lock(b) statement. In this situation, it might not be nearly so obvious when you write your code that you are allowing a possible deadlock.
Race Conditions
A race condition is somewhat subtler than a deadlock. It rarely halts execution of a process, but it can lead to data corruption. It is hard to give a precise definition of a race, but it generally occurs when several threads attempt to access the same data, and do not adequately take account of what the other threads are doing. Race conditions are best understood using an example.
Suppose we have an array of objects, where each element in the array needs to be processed somehow, and we have a number of threads that are between them doing this processing. We might have an object, let's call it ArrayController , which contains the array of objects as well as an int that indicates how many of them have been processed, and therefore, which one should be processed next. ArrayController might implement this method:
int GetObject(int index) { // returns the object at the given index. }
and this read/write property:
int ObjectsProcessed { // indicates how many of the objects have been processed. }
Now, each thread that is helping to process the objects might execute some code that looks like this:
lock(ArrayController) { int nextIndex = ArrayController.ObjectsProcessed; Console.WriteLine("object to be processed next is " + nextIndex); ++ArrayController.ObjectsProcessed; object next = ArrayController.GetObject(); } ProcessObject(next);
This by itself should work, but suppose that in an attempt to avoid tying up resources for longer than necessary, we decided not to hold the lock on ArrayController while we're displaying the user message. Therefore, we rewrite the above code like this:
lock(ArrayController) { int nextIndex = ArrayController.ObjectsProcessed; } Console.WriteLine("object to be processed next is " + nextIndex); lock(ArrayController) { ++ArrayController.ObjectsProcessed; object next = ArrayController.GetObject(); } ProcessObject(next);
Here, we have a possible problem. What could happen is that one thread gets an object (say the 11th object in the array), and goes to display the message saying that it is about to process this object. Meanwhile, a second thread also starts executing the same code, calls ObjectsProcessed , and determines that the next object to be processed is the 11th object, because the first thread hasn't yet updated ArrayController.ObjectsProcessed . While the second thread is happily writing to the console that it will now process the 11th object, the first thread acquires another lock on the ArrayController and inside this lock increments ObjectsProcessed . Unfortunately, it is too late. Both threads are now committed to processing the same object, and that's the kind of situation that we refer to as a race condition.
For both deadlocks and race conditions, it is not often obvious when the condition can occur, and when it does, it is hard to identify the bug. In general, this is an area where you largely learn from experience. It is, however, important to consider very carefully all the parts of the code where you need synchronization when you are writing multithreaded applications to check whether there is any possibility of deadlocks or a race conditions arising, bearing in mind that it is not possible to predict the exact times that different threads will hit different instructions.
EAN: 2147483647
Pages: 244