Section 8.4. Choosing What to Search
8.4. Choosing What to SearchLet's assume that you've already chosen a search engine. What content should you index for searching? It's certainly reasonable to point your search engine at your site, tell it to index the full text of every document it finds, and walk away. That's a large part of the value of search systemsthey can be comprehensive and can cover a huge amount of content quickly. But indexing everything doesn't always serve users well. In a large, complex web environment chock-full of heterogeneous subsites and databases, you may want to allow users to search the silo of technical reports or the staff directory without muddying their search results with the latest HR newsletter articles on the addition of fish sticks to the cafeteria menu. The creation of search zonespockets of more homogeneous contentreduces the apples-and-oranges effect and allows users to focus their searches. Choosing what to make searchable isn't limited to selecting the right search zones. Each document or record in a collection has some sort of structure, whether rendered in HTML, XML, or database fields. In turn, that structure stores content components: pieces or "atoms" of content that are typically smaller than a document. Some of that structuresay, an author's namemay be leveraged by a search engine, while other partssuch as the legal disclaimer at the bottom of each pagemight be left out. Finally, if you've conducted an inventory and analysis of your site's content, you already have some sense of what content is "good." You might have identified your valuable content by manually tagging it or through some other mechanism. You might consider making this "good" stuff searchable on its own, in addition to being part of the site-wide search. You might even program your search engine to search this "good" stuff first, and expand to search the rest of the site's content if that first pass doesn't retrieve useful results. For example, if most of an e-commerce site's users are looking for products, those could be searched by default, and the search could then be expanded to cover the whole site as part of a revised search option. In this section, we'll discuss issues of selecting what should be searchable at both a coarse level of granularity (search zones) and at the more atomic level of searching within documents (content components). 8.4.1. Determining Search ZonesSearch zones are subsets of a web site that have been indexed separately from the rest of the site's content. When a user searches a search zone, he has, through interaction with the site, already identified himself as interested in that particular information. Ideally, the search zones in a site correspond to his specific needs, and the result is improved retrieval performance. By eliminating content that is irrelevant to his need, the user should retrieve fewer, more relevant, results. On Dell's site (Figure 8-2), users can select search zones by audience type: home/home office, small business, and so on. (Note that "all" is the default setting.) These divisions quite possibly mirror how the company is organized, and perhaps each is stored in a separate filesystem or on its own server. If that's the case, the search zones are already in place, leveraging the way the files are logically and perhaps physically stored. Figure 8-2. Two types of search zones: audience zones (top) and topical zones (bottom)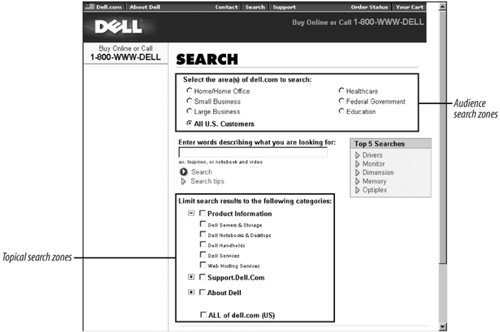 Additionally, users can select one or more of the site's categories or subcategories. It's probable that these pages come from the audience subsites, and that Dell allows its documents to be recombined into new search zones by indexing them by the keywords these zones represent. It's expensive to index specific content, especially manually, but one of the benefits of doing so is flexible search-zone creation: each category can be its own search zone or can be combined into a larger search zone. You can create search zones in as many ways as you can physically segregate documents or logically tag them. Your decisions in selecting your site's organization schemes often help you determine search zones as well. So our old friends from Chapter 6 can also be the basis of search zones:
And so on. Like browsing systems, search zones allow a large body of content to be sliced and diced in useful new ways, providing users with multiple "views" of the site and its content. But, naturally, search zones are a double-edged sword. Narrowing one's search through search zones can improve results, but interacting with them adds a layer of complexity. So be careful: many users will ignore search zones when they begin their search, opting to enter a simple search against the index of the entire site. So users might not bother with your meticulously created search zones until they're taking their second pass at a search, via an Advanced Search interface. Following are a few ways to slice and dice. 8.4.1.1. Navigation versus destinationMost web sites contain, at minimum, two major types of pages: navigation pages and destination pages. Destination pages contain the actual information you want from a web site: sports scores, book reviews, software documentation, and so on. Navigation pages may include main pages, search pages, and pages that help you browse a site. The primary purpose of a site's navigation pages is to get you to the destination pages. When a user searches a site, it's fair to assume that she is looking for destination pages. If navigation pages are included in the retrieval process, they will just clutter up the retrieval results. Let's take a simple example: your company sells computer products via its web site. The destination pages consist of descriptions, pricing, and ordering information, one page for each product. Also, a number of navigation pages help users find products, such as listings of products for different platforms (e.g., Macintosh versus Windows), listings of products for different applications (e.g., word processing, bookkeeping), listings of business versus home products, and listings of hardware versus software products. If the user is searching for Intuit's Quicken, what's likely to happen? Instead of simply retrieving Quicken's product page, she might have to wade through all of these pages:
The user retrieves the right destination page (i.e., the Quicken Product page) but also five more that are purely navigation pages. In other words, 83 percent of the retrieval obstructs the user's ability to find the most useful result. Of course, indexing similar content isn't always easy, because "similar" is a highly relative term. It's not always clear where to draw the line between navigation and destination pagesin some cases, a page can be considered both. That's why it's important to test out navigation/destination distinctions before actually applying them. The weakness of the navigation/destination approach is that it is essentially an exact organization scheme (discussed in Chapter 6) that requires the pages to be either destination or navigation. In the following three approaches, the organization schemes are ambiguous, and therefore more forgiving of pages that fit into multiple categories. 8.4.1.2. Indexing for specific audiencesIf you've already decided to create an architecture that uses an audience-oriented organization scheme, it may make sense to create search zones by audience breakdown as well. We found this a useful approach for the original Library of Michigan web site. The Library of Michigan has three primary audiences: members of the Michigan state legislature and their staffs, Michigan libraries and their librarians, and the citizens of Michigan. The information needed from this site is different for each of these audiences; for example, each has a very different circulation policy. So we created four indexes: one for each of the three audiences, and one unified index of the entire site in case the audience-specific indexes didn't do the trick for a particular search. Here are the results from running a query on the word "circulation" against each of the four indexes:
As with any search zone, less overlap between indexes improves performance. If the retrieval results were reduced by a very small figure, say 10 or 20 percent, it may not be worth the overhead of creating separate audience-oriented indexes. But in this case, much of the site's content is specific to individual audiences. 8.4.1.3. Indexing by topicAmeriprise Financial employs loosely topical search zones with its site. For example, if you're looking for information on investments that will help you achieve a financially secure retirement, you might preselect the "Individual" search zone, as shown in Figure 8-3. Figure 8-3. Executing a search against the "Individual" search zone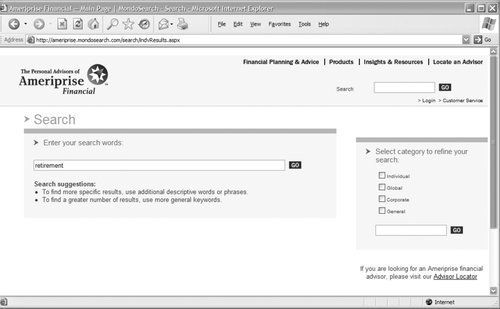 The 85 results retrieved may sound like a lot, but if you'd searched the entire site, the total would have been 580 results, many dealing with topic areas that aren't germaine to personal retirement investing. 8.4.1.4. Indexing recent contentChronologically organized content allows for perhaps the easiest implementation of search zones. (Not surprisingly, it's probably the most common example of search zones.) Because dated materials aren't generally ambiguous and date information is typically easy to come by, creating search zones by dateeven ad hoc zonesis straightforward. The advanced search interface of the New York Times provides a useful illustration of filtering by date range (Figure 8-4). Figure 8-4. There are many ways to narrow your New York Times search by date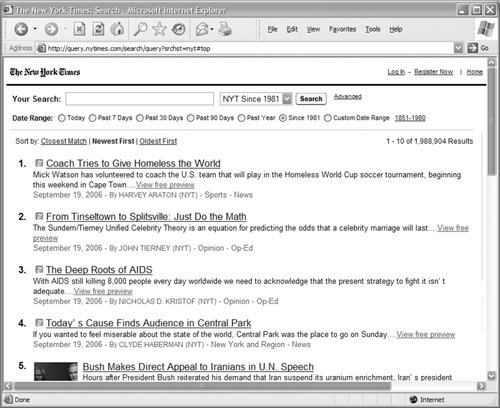 Regular users can return to the site and check up on the news using one of a number of chronological search zones (e.g., today's news, past week, past 30 days, past 90 days, past year, and since 1996). Additionally, users who are looking for news within a particular date range or on a specific date can essentially generate an ad hoc search zone. 8.4.2. Selecting Content Components to IndexJust as it's often useful to provide access to subsets of your site's content, it's valuable to allow users to search specific components of your documents. By doing so, you'll enable users to retrieve more specific, precise results. And if your documents have administrative or other content components that aren't especially meaningful to users, these can be excluded from the search. In the article from Salon shown in Figure 8-5, there are more content components than meet the eye. There is a title, an author name, a description, images, links, and some attributes (such as keywords) that are invisible to users. There are also content components that we don't want to search, such as the full list of categories in the upper left. These could confuse a user's search results; for example, if the full text of the document was indexed for searching, searches for "comics" would retrieve this article about finding a translator in Egypt. (A great by-product of the advent of content management systems and logical markup languages like XML is that it's now much easier to leave out content that shouldn't be indexed, like navigation options, advertisements, disclaimers, and other stuff that might show up in document headers and footers.) Figure 8-5. This article is jam-packed with various content components, some visible and some not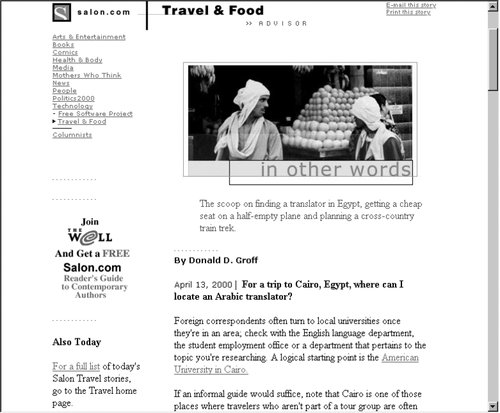 Salon's search system allows users to take advantage of the site's structure, supporting searches by the following content components:
Would users bother to search by any of these components? In Salon's case, we could determine this by reviewing search-query logs. But what about in the case of a search system that hadn't yet been implemented? Prior to designing a search system, could we know that users would take advantage of this specialized functionality? This question leads to a difficult paradox: even if users would benefit from such souped-up search functionality, they likely won't ever ask for it during initial user research. Typically users don't have much understanding of the intricacies and capabilities of search systems. Developing use cases and scenarios might unearth some reasons to support this level of detailed search functionality, but it might be better to instead examine other search interfaces that your site's users find valuable, and determine whether to provide a similar type of functionality. There is another reason to exploit a document's structure. Content components aren't useful only for enabling more precise searches; they can also make the format of search results much more meaningful. In Figure 8-6, Salon's search results include category and document titles ("Salon Travel | In other words"), description ("The scoop on finding a translator in Egypt..."), and URL. Indexing numerous content components for retrieval provides added flexibility in how you design search results. (See the later section "Presenting Results.") Figure 8-6. Title, description, and URL are content components displayed for each result |
EAN: 2147483647
Pages: 194