Chapter 3: Hard Drive Reliability
|
| < Day Day Up > |
|
Information technology (IT) departments are continually being asked to provide higher levels of uptime and reliability without increasing expenditures. One often overlooked way to fulfill these demands is to keep server, workstation, and laptop disk drives from crashing. This is becoming more difficult, however, as organizations strive to provide 24/7 service while being forced to extend equipment lifespan in the face of budget cuts. This chapter gives a basic rundown of the stats and surveys that exist on hard drive reliability, pointing out that drive failure is a far more serious problem than is commonly realized. It also investigates the consequences of failure these days and the various misconceptions regarding failure, particularly mean time between failures (MTBF). Most users think the MTBF statistic means that you will get 30 years of life out of every hard drive. Far from it. In addition to this misleading metric, the chapter covers the various systems and technologies designed to protect hard drives.
MTBF Explained
Given all the challenges facing IT departments, it is easy to become complacent about the subject of disk drive failure. Reading server spec sheets listing hard disk lifespan ratings in the hundreds of thousands of hours, one might assume that the drive will long outlast any use the organization may have for it. But, in actual fact, the alarming regularity of disk crashes in all organizations indicates a dangerous situation that cannot be ignored.
Many people, it turns out, have a misconception of what manufacturers mean when they provide the MTBF for their disks. MTBF, it turns out, can have two very different meanings. Some users assume it means "mean time before failure." If this definition actually applied, there would be no reason to worry. Most disks come with a 300,000- to 1,000,000-hour MTBF range; many people who see this figure think that a disk with a 300,000-hour rating would run around the clock for the next 34 years before needing replacement. By the same token, a 1,000,000-hour disk would be expected to run for over a century.
Unfortunately, however, mean time before failure is not actually what the manufacturers are estimating. The correct definition of MTBF is mean time between failures, quite a different matter. According to Seagate Technology Paper 338.1, "Estimating Drive Reliability in Desktop Computers and Consumer Electronic Systems," Seagate estimates the mean time between failures for a drive as the number of power-on hours (POH) per year divided by the first-year annualized failure rate (AFR). This is a suitable approximation for small failure rates and is represented as a first-year MTBF. So what does that mean? MTBF relates only to the failure rate in the first year. Beyond that, the manufacturers really are promising nothing more than the usual three- to five-year warranty period that comes with any disk.
Now, of course, manufacturers are much too busy to do a full year of testing on a product before releasing it to market, so they take a batch of components and test them in a laboratory for a certain period, perhaps with a higher ambient temperature to accelerate the aging process. The actual tests themselves last only a few weeks. The aggregate number of hours that all the disks ran is divided by the number of disks that failed during the test, and the resulting numbers are run through certain formulas to estimate the MTBF.
As a comparison, an MTBF rating is similar to the J.D. Powers and Associates Initial Quality Survey to which automobile manufacturers refer in their advertising. The bottom line is that it is not based on real-world quality metrics. Similarly, the MTBF number obtained by manufacturer testing does not predict how long any one piece of hardware will last, but rather how many from a batch of disks are expected to fail within the first year. The higher the MTBF number, the fewer the predicted crashes. If, for example, an enterprise has 5,000 total workstations and server disks combined, with an average MTBF of 300,000 hours per the manufacturer's specs, it can be expected that one disk will fail every 60 hours during the first year — quite different from many people's perception of MTBF. If these boxes are running only 40 hours per week, that translates into a failure every one and a half weeks. But, when all the boxes are left on 24/7, one disk would fail, on average, every two and a half days. Now up the number of machines to 10,000, and about one disk will require fixing every day (Exhibit 1).
Exhibit 1: Mean Time between Failures
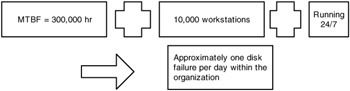
Remember, too, that this rating applies to only the first year. As the equipment gets older, particularly if someone is trying to stretch its usefulness beyond the first two or three years, disk failure rates rise alarmingly. At least the MTBF allows for comparison of the relative reliability between disks. For example, if one vendor offers a 300,000-hour MTBF and another 600,000, generally the disk with the higher rating will last longer and be more reliable.
When I explain the math of MTBF as above, I often hear cries of protest from experienced IT professionals who have been misled by MTBF propaganda over the years and do not accept the conclusions drawn, which perhaps contributes to why so little attention has been paid to disks. If they are going to run for over a century, why worry about them? But, for your own sake and for the sake of the organization, it is definitely advisable to worry about them.
|
| < Day Day Up > |
|
EAN: N/A
Pages: 197