One-to-One Relationships
Perhaps the simplest type of relationship is the one-to-one relationship. If it's true that any instance of entity X can be associated with only one instance of entity Y, then the relationship is one-to-one. Most IsA relationships will be one-to-one, but otherwise, examples of one-to-one relationships are fairly rare in the problem domain. When choosing a one-to-one relationship between entities, you need to be sure that the relationship is either true for all time or, if it does change, that you don't care about past values. For example, say you're modeling the office space in a building. Assuming that there is one person to an office, there's a one-to-one relationship, as shown in Figure 3-6.
![]()
Figure 3-6. There is a one-to-one relationship between Office and Employee.
But the relationship between an employee and an office is true only at a specific moment in time. Over time, different employees will be assigned to the office. (The arrangement of offices in the building might change as well, but that's a different problem.) If you use the one-to-one relationship shown in Figure 3-6, you will have a simple, clean model of the building, but you'll have no way of determining the history of occupancy. You might not care. If you're building a system for a mail room, you need to know where to send Jane Doe's mail today, not where it would have been sent three months ago. But if you're designing a system for a property manager, you can't lose this historical information—the system will be asked to determine, for example, how often tenants change.
Although one-to-one relationships are rare in the real world, they're very common and useful abstract concepts. They're most often used to either reduce the number of attributes in a relation or model subclasses of entities. There is a physical limitation of 255 fields per table if you're using the Jet database engine, and 250 fields per table if you're using SQL Server. I'm suspicious—very suspicious—of any data model that exceeds these limitations. But I have occasionally seen systems, usually in science and medicine, where the entities had more than 255 genuine attributes. In these cases, you have no choice but to create a new relation with some arbitrary subset of attributes and to create a one-to-one relationship between it and the original, controlling relation.
Another problem domain that often appears to require that the physical limitations on table size be exceeded is the modeling of tests and questionnaires. Given a test with an arbitrary number of questions, you might be tempted to model an individual's responses as shown in Figure 3-7.
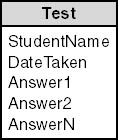
Figure 3-7. This structure is sometimes used to model tests and questionnaires, but it is not ideal.
This structure is easy to implement, but it is not generally the best solution. The answer attributes are a repeating group, and the relationship is therefore not in first normal form. A better model is shown in Figure 3-8.
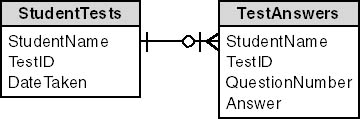
Figure 3-8. Although more difficult to implement, this structure is preferable for modeling tests and questionnaires.
Subclassing Entities
A more interesting use of one-to-one relationships is for entity subclassing, a concept borrowed from object-oriented programming. To see some of the benefits of subclassing entities, let's first look at a more traditional implementation. In the Microsoft Access Northwind sample database, each product is assigned to a product category, as shown in Figure 3-9.
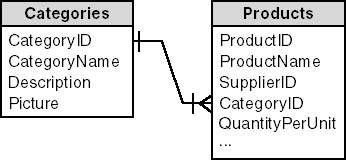
Figure 3-9. Each product in the Northwind database is assigned to a product category.
Having a Categories relation allows the products to be grouped for reporting purposes and might be all that is required by your problem space. But with this design, you can treat a product only as a product, not as an instance of its specific category. Any attributes defined for Products are stored for all products, whatever their type. This isn't a very close match to the problem domain—Beverages intrinsically have different attributes than Condiments.
You might be tempted to model the Northwind product list as shown in Figure 3-10. This model allows us to store all the specific information for each product type, one type per relation, but makes it difficult to treat a product as a product.
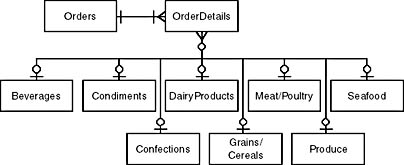
Figure 3-10. This model allows category-specific attributes to be captured.
Imagine, for example, the process of checking that a product code entered by a user is correct: "if the code exists in the x relation, or the y relation, or…". This is as ugly as the repeating group query in Chapter 2. Also, you might run into integrity problems with this structure if you have certain attributes that apply only to one product category (UnitsPerPackage, for example, which might pertain to Beverages but not DairyProducts) and the category of a particular product changes. What do you do in these circumstances? Throw away the old values? But what if the change was accidental, and the user immediately changes it back?
Subclassing the product entity provides the best of both worlds. You can capture information specific to certain product categories without losing the ability to treat the products as the generic type when that's appropriate, and you can defer the deletion of the no-longer-applicable information until you're certain it really is no longer applicable. Figure 3-11 shows a model developed using entity subclasses.
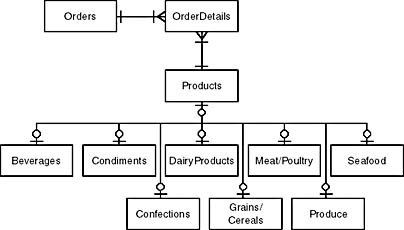
Figure 3-11. This model uses subclassing to provide the capabilities of both previous figures.
It must be said that while entity subclassing is an elegant solution to certain types of data modeling problems, it can be an awkward beast to implement. To take just one example, a report containing Product details would need to include conditional processing to display only the fields appropriate to the current subclass. This isn't an insurmountable task by any means, but it is a consideration. Under most circumstances, I wouldn't recommend that you compromise the data model to make life easier for the programmers. But there's certainly no point in adding the complexity of subclassing to the model if all you need is the ability to group or categorize entities for reporting purposes; in this situation, the structure shown in Figure 3-9 is perfectly adequate and far more sensible.
Identifying the primary and foreign relations in a one-to-one relationship can sometimes be tricky, as you must base the decision on the semantics of the data model. If you've chosen this structure in order to subclass the entity, the generic entity becomes the primary relation and each of the subclasses becomes a foreign relation.
NOTE
In this situation, the foreign key that the subclasses acquire is often also the candidate key of the subclasses. There is rarely a reason for subclasses to have their own identifiers.
If, on the other hand, you're using one-to-one relationships to avoid field limitations, or the entities have a genuine one-to-one relationship in the problem space, the choice must be somewhat arbitrary. You must choose the primary relation based on your understanding of the problem space.
One thing that can help in this situation is the optionality of the relationship. If the relationship is optional on one side only (and I've never seen a model where it was optional on both sides), the relation on the optional side is the foreign relation. In other words, if only one of the entities is weak and the other regular, the regular entity is the primary relation and the weak entity is the foreign relation.
EAN: 2147483647
Pages: 124