FRR
| < Day Day Up > |
DefinitionThe FRR is defined as the probability that a user making a true claim about his/her identity will be rejected as him/herself. For example, if Chris types his correct user ID into the biometric login for his PC, Chris has just made a true claim that he is Chris. Chris presents his biometric measurement for verification. If the biometric system does not match Chris to Chris, then there is a false rejection. This could happen because the matching threshold is set too low, or Chris' presented biometric feature is not close enough to the biometric template. Either way, a false rejection has occurred. The Simple MathWhen the FRR is calculated by a biometric vendor, it is generally very straightforward. Again, using our example, it is equal to the number of times that Chris unsuccessfully authenticated as Chris divided by his total number of attempts. In this case, Chris is referred to as the "MatchUser":
This gives us the basis for Chris' FRR. What if we have another user, Matt? We could say that Chris is representative of our user population and just assume that the FRR will be the same for Matt. Statistically, the more times something is done, the greater the confidence in the result. Thus, if we want to ensure a high probability that the FRR we calculate is statistically significant, we would need to do this for every user. We would then need to take all the calculated FRRs for each user's attempt to authenticate as himself/herself, sum them up, and divide by the total number of users. The result is the mean (average) FRR for all users of a system. For example, we would take the above formulas and compute them for each user. We would eventually get something that looks like the following:
If we generalize the formula, we get:
Why Is This Important?The strength of the FRR is the robustness of the algorithm. The more accurate the matching algorithm, the less likely a false rejection will happen. Chris has a lower chance of being falsely rejected as himself at 1:500 than he does at 1:10,000. Again, let's use the example of playing a ring-toss game. In this game, the ring represents Chris' authentication attempt. The distance between the pegs represents the robustness of the biometric algorithm. The gameboard itself represents Chris' biometric enrollment. In the first case, there are 500 pegs on which to throw the ring. The peg that needs to be ringed for a winner is known. Thus, Chris has a 1 in 500 chance of hitting the right peg. Chris also has less of a chance of hitting the wrong peg since there is generous spacing between the pegs. Now, if Chris plays the same game, but this time there are 10,000 pegs in the same area, he has a 1 in 10,000 chance of hitting the right peg. There is now also less spacing between pegs, as the playing area is the same size as it was for 500 pegs. So, Chris has a greater chance of landing on the wrong peg because of the pegs' relative proximity to each other. |
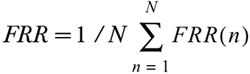
| < Day Day Up > |
EAN: 2147483647
Pages: 123