RULE EXTRACTION FROM DATABASE WITH GP
In this section, we will show how we can apply GP to extract knowledge from databases. In particular, we will apply it to extract rules to solve the iris problem in two different ways: with one rule that makes the classifications, or with three rules, one each for determining whether a sample belongs to a class or not.
One-Tree Classification
In this part, we will configure and run GP to obtain a single tree that makes a classification of the data points. Here, we will show how we can improve the performance of GP by pre-processing the data and, this way, obtain better results.
Classification with No Pre-Processing
Here, we will solve the problem with the data taken as is, with no modification at all.
Configuration
As explained in earlier, to make it possible to run GP, we need to specify the terminal and function sets.
Since we want to obtain a flower classification, we will need to make trees with a concrete structure. We will use the typing properties of GP to do this. We will ask GP to make trees with a special type: FLOWER_TYPE.
To have the trees as classifier rules, we need three terminals and one function returning that type. These terminals are Setosa , Virginica and Versicolor , one for each type of flower. The function is IF-THEN-ELSE, which accepts, as first input, a Boolean expression and, as second and third inputs, expressions with FLOWER_TYPE type, whether they are one of the three terminals or other IF-THEN-ELSE expressions.
So, the resulting trees will have the shape of a decision rule. For example:
IF <boolean expression> THEN IF <boolean expression> THEN Virginica ELSE Versicolor ELSE IF <boolean expression> THEN Setosa ELSE Versicolor
To build the Boolean expressions, we will use as terminals the variables X 1 , X 2 , X 3 and X 4 , which stand for petal width , petal length , sepal width and sepal length , respectively (all four variables real numbers ); and we will use the random constants, extracted from the real interval between 1 and 80. We chose this interval because it contains the maximum and minimum values those four variables can have.
We also have the traditional arithmetic operators +, -, * and %, standing % for the division-protected operator, which returns a value of 1 if the denominator is equal to 0.
For building Boolean expressions, relational and Boolean operands are required; relational for establishing relations between the real expressions (containing those four variables and constants) and Boolean operators for joining other Boolean expressions, if necessary.
The complete set of terminals and functions, with their types and their children types, in case of being functions, can be seen in Table 1.
| Name | Returning type | Parameter type | |
|---|---|---|---|
| Terminal set | X 1 , X 2 , X 3 , X 4 | REAL | |
| [1, 80] | REAL | ||
| Setosa, Verginica, Versicolor | FLOWER_TYPE | ||
| Function set | IF-THEN-ELSE | FLOWER_TYPE | BOOLEAN, FLOWER_TYPE, FLOWER_TYPE |
| +, -, *, % | REAL | REAL, REAL | |
| <, >,>=,<= | BOOLEAN | REAL, REAL | |
| AND, OR | BOOLEAN | BOOLEAN, BOOLEAN | |
| NOT | BOOLEAN | BOOLEAN | |
Results
For solving this problem, different combinations of parameters were used. The set with which we obtained better results can be seen in Table 2.
| Selection algorithm | Tournament |
| Crossover rate | 95% |
| Mutation rate | 4% |
| Population size | 500 individuals |
| Parsimony level | 0.0001 |
The result is a classification rule with a fitness of 99.33 percent success: it fails in one case out of a possible 150. The rule obtained, after 23 hours of computing in an AMD K7 at 1 GHz and 128 MB of RAM, is the following:
IF (X 2 < 25.370) THEN SetosaELSEIF ((((X 2 -40.959)%X 2 )<(X 2 -(X 3 - (X 1 %(X 1 -(X 4 -23.969)))) AND ((X 2 % (X 2 - 42.760) <(X 2 - (23.969%(X 2 -(X 4 -(X 2 -34.507)))))) AND (((X 1 -10.856)%(X 2 - 40.959))<(X 2 -(X 3 -((X 2 -42.760)% (X 1 - 21.777))))))) AND (((X 2 -X 3 < (X 4 -(X 2 % (X 2 - (X 4 - (X 2 - (X 4 - (X 2 - (X 3 -((X 2 -40.959)%(X 1 - 21.777))))))))))) AND (((X 2 % (X 2 -(X 4 -(X 2 -(X 3 -(X 1 % (X 2 - 40.959))))))) % (X 2 -40.959))<X 2 -(X 3 -(X 1 %(X 1 -21.777))))) AND ((23.969 % (X 1 - 10.856)) < ((X 2 - (23.969 % (X 2 - (X 4 - (X 2 -(X 3 -((X 2 - 40.959) % (X 2 - X 3 - 21.777))))))))-(X 2 % (X 2 -(X 4 -(X 2 -40.959))))))))) AND ((X 3 - ((X 2 -40.959)%(X 1 -21.777)))>21.777)) THEN Virginica ELSE Versicolor
Classification with Pre-Processing
Now we will see how we can improve the performance of GP by preprocessing the data. What we will do is normalize the data to make all four parameters be in the interval [0,1]. We do this to make these four variables be in the same rank. So, for GP, it will be easier to make and combine mathematical expressions including constants, because these will be in similar ranks. We won't be combining expressions with out-of-rank values.
Configuration
Since we still want to obtain one tree with the shape of an IF-THEN-ELSE classifier rule, we will use a terminal set and a function set similar to the ones explained in the previous section and shown in Table 1. The only exception is the use of random constants: now they will not be within the rank [1,80], but in the rank [0,1] because, as we have the data normalized in that rank, we need the constants to be in the same rank, too.
Results
The best set of parameters found for solving this problem is the same as described in the previous section, shown in Table 2. With these parameters, the best expression found, with a fitness of 100 percent, computed with the same machine and after seven hours, is the following:
IF (X 2 < 0.373) THEN Setosa ELSE IF (((0.483>((X 4 -0.799)*(0.483%(X 1 -X 2 )))) AND (X 3 > 0.701) OR (X 4 >(X 1 -(0.182+X3)*(0.483%(X 1 -X 2 )))))) OR (((-0.132) * ((X 1 * X 2 ) % ((0.821 * (0.721-(X 1 - (0.182+X 3 )))) - (0.182+X 3 )))) > (0.483%(X 1 -0.701)))) THEN IF ((((X 4 >(-0.132*((X 1 *X 1 )%(0.721-(0.182+X 3 )))) AND (X 4 > ((- 0.132) * (0.483 % (0.721 - (((X 1 -((0.182+X 3 ) * 0.877))*(0.483%(X 1 - X 2 )))*(0.483 %(0.182+X 3 )))))))) AND (0.821>((-0.132)* (0.483%(X 1 -0.701))))) AND (X 4 >(- 0.132*(X 4 % (0.721-(((X 1 -(0.182+X 3 )) *(0.483%(X 1 -X 2 ))) * (0.483%(0.182+X 3 )))))))) OR ((X 3 >(X 1 -(-0.132))) OR ((X 2 >0.721) AND (X 4 >((-0.132)*(0.483%(X 1 - ((0.182+X 3 )*0.877)))))))) THEN IF (((0.721>(X 2 *X 4 )) AND (X 4 >X 2 )) OR (((X 1 < 0.877) OR (0.799>X 4 )) OR (X 3 >0.799))) THEN Verginica ELSE Versicolor ELSE Versicolor ELSE Versicolor
Note that the second expression (obtained with pre-processing) has better fitness (100%), and has been found in less time. So with a small pre-processing of the data, we improved the performance of GP in both the fitness obtained and in the time taken to develop the desired expression.
Three-Tree Classification
In this section, we will solve the problem from a different point of view. We will use GP, not for making a simple classification into one of the three classes, but to extract three Boolean rules to determine whether a particular data point belongs to each species of flower.
As we have three decision rules, it will have an additional advantage: if, for the same data point, none of the rules determines an output as true, or if more than one makes an output as true, then we can conclude that this point is not well classified by the system. We can detect some errors made by the system.
Configuration
To obtain these Boolean rules, we configure GP to obtaining Boolean expressions. The resulting type will be BOOLEAN. As Boolean elements, we will have the IF-THEN-ELSE classifier rules (accepting three children with BOOLEAN type), the relational operators needed to establish relations between variables and constants, and Boolean operators.
We will also need the four variables and random constants now inside the interval [0,1] because now we are working directly with normalized values. The complete terminal and function sets are shown in Table 3.
| Name | Returning type | Parameter type | |
|---|---|---|---|
| Terminal set | X 1 , X 2 , X 3 , X 4 | REAL | |
| [0, 1] | REAL | ||
| Function set | IF-THEN-ELSE | BOOLEAN | BOOLEAN, BOOLEAN, BOOLEAN |
| +, -, *, % | REAL | REAL, REAL | |
| <, >,>=,<= | BOOLEAN | REAL, REAL | |
| AND, OR | BOOLEAN | BOOLEAN, BOOLEAN | |
| NOT | BOOLEAN | BOOLEAN | |
Results
The set of parameters which gave better results is the same as described in the previous section and shown in Table 2. With these elements, the results obtained, with the inputs already normalized, can be seen in Table 4. Note that the third expression (used for Iris Virginica ) has a fitness of 99.33 percent success, i.e., it fails in one case out of the 150. This case is classified by the system as both Virginica and Versicolor (false, true, true), which is an invalid exit and it is detected . So, we can say that the system doesn't have any failures and gets a fitness of 100 percent success.
| Flower type | Expression obtained | Fitness |
|---|---|---|
| Setosa | (X 1 < 0.3141) | 100% |
| Versicolor | (((0.677>X 3 ) OR (0.526<X 2 <(0.736))) AND (((0.610<X 1 <0.721) OR ((0.3360<X 1 <0.526) OR (0.526<X 2 < 0.721))) AND ((X 3 >X 1 ) OR (0.677>X 1 )))) | 100% |
| Virginica | (((X 1 >X 2 ) OR (X 2 >0.718)) AND ((X 2 >X 4 ) OR (((0.739<X 2 <0.765) OR (X 4 >0.902)) OR (X 1 >X 3 )))) | 99.33% |
The comparison with other techniques can be seen in Table 5.
| Method | Type | Fitness | Reference |
|---|---|---|---|
| Proposed here | Rules | 100% | |
| ReFuNN | Fuzzy | 95.7% | (Kasabov, 1996) |
| C-MLP2LN | Crisp | 98.0% | (Duch et al, 2000) |
| SSV | Crisp | 98.0% | (Duch et al, 2000) |
| ANN | Weigths | 98.67% | (Martinez and Goddard, 2001) |
| Grobian | Rough | 100.0% | (Browne et al, 1998) |
| GA+NN | Weigths | 100.0% | (Jagielska et al, 1996) |
| NEFCLASS | Fuzzy | 96.7% | (Nauck et al, 1996) |
| FuNe-I | Fuzzy | 96.0% | (Halgamuge and Glesner, 1999) |
The distributions obtained from these three rules can be seen in Figure 2. In this graph, and in the one following, the X axis references petal width (X 1 ) and the Y axis references petal length (X 2 ).

Figure 2: Distributions Obtained for the Three Classes
We can put these three distributions together in the same graph and compare them with the training set. This is shown in Figure 3.
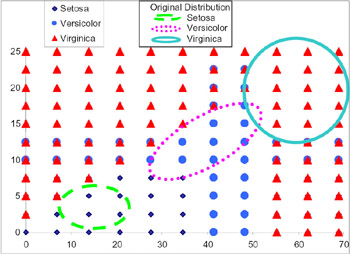
Figure 3: Distributions Obtained from the Rules and from the Training Set
In this figure, we can see that the rule extraction system tries to join those values which depend on each classification and tries to isolate them from those values which are dependent on other classifications. The intersection areas are those in which the system makes incorrect outputs, indicating that the given output is not correct and that an individual analysis is necessary for those values to determine to which class they belong.
EAN: N/A
Pages: 171
- Chapter I e-Search: A Conceptual Framework of Online Consumer Behavior
- Chapter II Information Search on the Internet: A Causal Model
- Chapter IV How Consumers Think About Interactive Aspects of Web Advertising
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior