EVALUATION AND RESULTS
To evaluate fuzzy filtering against Boolean filtering, we used the Reuters-21578 corpus . We consider the flat topic taxonomy that consists of the 10 most frequently assigned topic categories. A term -document matrix was created after removing the infrequent [Jochims] and the most commonly used English words. Using the labels of the topics, we are able to formulate filters of the form (Earn) AND (Trade), (Acq) OR (Money-Fx), and then use them to find relevant documents in a stream of data.
To specify the exact filters to use, and to measure their effectiveness as regards the logical operators, we considered the "ModApte" split, a standard commonly-used partitioning of the Reuters corpus into training and test sets. A search in the test set of the "ModApte" split yielded 213 documents that belong to two or more of the specified topics. These documents constitute the set F to be filtered and are mapped to 19 multi-category vectors in the table CM , where cm ij = 1 implies that category c j exists in multicategory vector m i .
For every multicategory vector m i , where i =1 19, of the filtering set, the logic operator AND is used to combine trained classifiers of all categories having cm ji = 1, in order to find documents in F that belong to all of them. In the same way, the logic operator OR is used to combine trained classifiers of all categories having cm ji = 1, in order to find documents in F that belong to at least one of them. Finally, the logic operator NOT is used in conjunction with OR to combine trained classifiers of all categories having cm ji = 1, in order to find documents in F that do not belong to any of them. As a result, we form 19 filters and obtain their relevant documents in F for every logical operator.
SVM Training
To reduce dimensionality, we applied Principal Component Analysis (PCA) on the training set leaving the 300 most informative features. We trained and validated one two-class SVM classifier for every topic in the "ModApte" split. We took as positive examples all the samples that belong to the topic. As negative examples we took all the samples that do not belong to the topic.
To obtain the best possible classification accuracy, we optimized the hyperparameters of nonlinear SVM on the filtering set F . In Table 4, we give the classification accuracy of SVM on the test (filtering) set. The output of each SVM was transformed to probability using maximum likelihood , as described in Section 2, using the MATLAB optimization toolbox.
| Topic | SVM | NB |
|---|---|---|
| Earn | 0.9812 |
|
| Acq | 0.9812 | 0.4 |
| Money-fx | 0.9531 | 0.5102 |
| Crude | 0.9624 | 0.4681 |
| Grain | 0.9484 | 0.7739 |
| Trade | 0.9635 | 0.0769 |
| Interest | 0.9108 | 0.5909 |
| Ship | 0.9531 | 0.5870 |
| Wheat | 0.9014 | 0.6197 |
| Corn | 0.9624 | 0.5179 |
| Average | 0.9518 | 0.4537 |
NB Training
We trained and validated one NB classifier for every topic in the "ModApte" split. For the 10 classifiers, we validated each combination of thresholds out of three different threshold values (0.05, 0.1, 0.3) in the filtering set F . The best threshold set was selected based on the F1 measure and macroaveraging (Sebastiani, 2002). In Table 4, we give the classification accuracy of NB on the test (filtering) set.
In the case of Boolean filtering, every document d in F was assigned the crisp value {0,1}, depending on whether it belongs to class c j or not. For every filter, the related decisions were aggregated using Boolean logic. Because no ordering is available, Boolean filtering was evaluated by averaging recall and precision over all filters for both NB and SVM training of a logical operator (see Table 5).
| SVMs | NB | |||
|---|---|---|---|---|
| Operator | Precision | Recall | Precision | Recall |
| AND | 0.36 | 0.39 | 0.21 | 0.15 |
| OR | 0.93 | 0.86 | 0.96 | 0.54 |
| NOT | 0.75 | 0.80 | 0.75 | 0.99 |
In the case of fuzzy filtering, every document d in F was assigned a value indicating the estimated probability Pr(c j d) that it belongs to class c j . For every filter, the related probabilities Pr(c j d) were aggregated using OWA operators to estimate whether d is relevant to the filter. Because fuzzy filtering provides ordering, a standard recall-precision diagram of a logical operator can be constructed (see Figure 1 and Figure 2). Different values of b , in the case of Fuzzy OR and NOT, did not show any difference in performance. On the contrary, the performance of the AND operator was improved for both ± = 0.4 for NB and ± = 0.1 for SVMs. It is worth noting that the improvement produced by OWA aggregation on the less accurate NB classifier was much greater than the improvement on the more accurate SVM classifier.
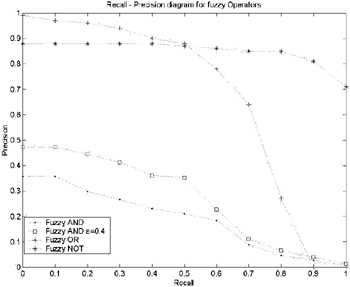
Figure 1: Recall-Precision Diagram of the Logic Operators for NB Training
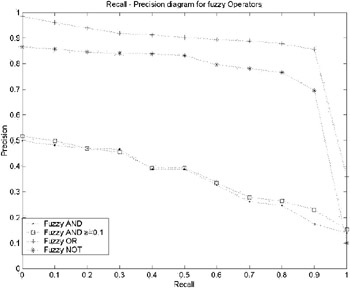
Figure 2: Recall-Precision Diagram of the Logic Operators for SVM Training
In all cases, fuzzy aggregation succeeded in improving retrieval performance. In the case of OR and NOT operators, the improvement was due to higher precision. This means that true positive documents are placed high in the ranked answer set. In the case of AND operators, fuzzy aggregation managed to improve both recall and precision.
EAN: N/A
Pages: 171