11.4 Backups
|
| < Day Day Up > |
|
A very wise person once said that an important difference between email and word processing applications is that the effect of a word processor failure is limited to a single user and perhaps a small quantity of documents. When an email system collapses, everyone is affected. Usually, people at the top of a company notice the problem fastest (and complain quickest). Having a large server go offline because of a hardware problem is a hassle. Not being able to recover the data because no backups exist or you cannot restore the data is a fundamental lapse in system management discipline that can lead to instant dismissal. There is simply no excuse for not taking backups, and there is no excuse for not ensuring that the data on the backup media is valid and restorable.
Email systems depend on many different hardware and software components to keep everything going. If any element fails to operate in the required manner, data corruption can occur. If the hardware suffers a catastrophic failure, or a disaster such as an electric outage afflicts the location where the computers are, you will need to know the steps necessary to get your users back online as quickly as possible. In all these instances, system backups are a prerequisite.
In their purest sense, backups are snapshots of a system's state at a certain point in time. All of the data available to the system should exist in the backup and should be restorable to exactly the same state if required. You can write backups to many different forms of magnetic or other media, although the most common medium is some form of high-density magnetic tape. DLT drives are the best option for Exchange.
Exchange has always supported online backups, which generally proceed without causing any discomfort or impact to clients connected to the server. There is no reason to take Exchange offline just to perform a backup. In fact, taking Exchange offline is not a good thing to do. First, it reduces overall system availability, because users cannot connect to their mailboxes.
Second, each time you bring the Store service online, the Store generates public folder replication messages to request updates from replication partners. Finally, the Store calculates checksums for each page before streaming them out to media during online backups, and if a checksum does not match, the Store will halt the backup operation. Best practice is always to perform online backups and to perform daily full online backups if possible, mainly because it is much easier to restore from a single tape than have to mess around with incremental backups.
When you install Exchange, the installation procedure enhances NTBACKUP.EXE, the standard Windows backup utility. These enhancements are as follows:
-
Support for the transactional nature of the Exchange Store: in particular, the capacity to deal with the fact that the totality of the Store is in Mailbox Stores, transaction logs, and transactions that might still be queued in memory.
-
Support for both the EDB and streaming file.
-
Ability to perform online backups: in other words, to copy online databases to tape without having to shut down Exchange services. Users continue to work during backups.
-
Extension of the NTBACKUP.EXE user interface to allow system administrators to select which servers and databases they wish to back up or restore.
-
Microsoft has scheduled NTBACKUP from Windows 2003 SP1 to support hot backups of Exchange 2003 databases. Remember that you also need VSS-capable hardware to use VSS to take hot backups.
11.4.1 Creating a backup strategy
All hardware systems can expect hardware failures to occur over time. When it is your turn to experience a failed server, you will be glad that backups exist. System failures come in three broad categories.
-
Disk or controller failure
-
Other noncritical system component failure: for example, the video monitor for the server develops a fault
-
Critical system component failure: for example, the motherboard or other associated component experiences a fault that you cannot quickly rectify
Any failure situation requires some fast but calm thinking in order to make the correct decisions to get everything online again. If you cannot bring the system back online, can you substitute another similar system and restore application data? If it is a particular system component, is a replacement available, or can you change the system configuration to work around the problem? Having backups around will not replace making the right decision, but they are a great safety net.
The Mean Time between Failures (MTBF) rate for disks improves all the time. This does not mean that you will never experience a disk failure, but it does mean that you are less likely to have one over any particular period. A high MTBF is no guarantee that the disk will not fail tomorrow, so the challenge for system administrators is to have a plan to handle the problem when it occurs. Without a RAID array, if something does go wrong with a disk you will have to stop and fix the problem or swap in a new drive. Once the hardware problem is fixed, you will have to restore the data, and, of course, this simple statement assumes that you have copies of all the application files that were stored on the faulty drive and that you possess the capability to move the data onto the new drive. The value of good backups is instantly obvious at this point! Of course, none of the protection afforded by disk technology is viable if you do not deploy the right hardware, such as hot-swappable drives and the best controller you can buy.
Having the capability to take online backups is one thing. Making sure that administrators take backups is quite another. Nightly backups of the databases, taken in tandem with full monthly backups of the server as a whole (i.e., including the Windows operating system, other applications, and all the Exchange files), must be taken if any guarantee as to the integrity of the messaging system is to be given to users.
The database-centric nature of Exchange poses a particular challenge for restore operations. There is no getting away from the fact that if a restore is necessary, it is going to take much longer than you may realize. The length of time that it takes an administrator to back up or restore databases from a large production Exchange server may come as a surprise to some. It is easy to forget just how long it takes to move data to backup media. Mailbox and Public Stores both have the capacity to expand quickly, so your backup times will grow in proportion. After a server has been in production for a number of months, you might find that it is time to consider looking for faster or higher-capacity media to help reduce backup times.
Remember, too, that it is not just the Exchange databases that you have to back up to ensure that you can recover a system. The AD, other Windows data, the IIS metabase, Exchange binaries, user data, and other application data all contribute to the amount of data and length of backup operations. In line with best practice, most Exchange servers are not DCs or GCs, so you may not have to restore the AD after a failure on an Exchange server. However, the IIS metabase is an important component that is easy to overlook. Exchange 2000 and 2003 depend on IIS for protocol access for Internet clients. The IIS metabase stores configuration data about protocols and virtual servers, including information about the SMTP, IMAP, and HTTP virtual servers used by Exchange. Since IIS is now such an integral part of Exchange, you must incorporate metabase recovery into any disaster recovery plan. Remember that clustered systems are different from standard servers, and securing data such as quorum resources, disk signatures, and so on is important for recovery operations.
It is also important to apply the correct levels of service packs to Windows and Exchange on the recovery server before commencing any restore operation. The internal database schema has changed a number of times in Exchange's history. In general, you cannot restore a database from a backup taken with a higher software revision level. In other words, do not expect to be able to restore a backup taken with Exchange 2000 or 2003 to a server running Exchange 5.5. This rule does not hold true for all combinations of service packs and versions, but there is enough truth in it to make a strong recommendation that you should maintain servers at the same software levels in order to ensure that you can always restore backups.
You must account for all of the factors discussed here in the operational procedures you employ at your installation. Restores are equally as important as backups, but all the attention goes to backup procedures and backup products. Administrators usually only look into the detail of restores when a disaster happens, which is exactly the wrong time to begin thinking about the issue. Consider this question: How long will it take to restore one gigabyte of data from your backup media using the backup software you employ? Now, how long will it take to restore 3 GB, or maybe 10 GB, or how about a full-blown 100-GB Mailbox Store? And what about a Public Store? Do you have procedures in place to handle the restore of the different permutations of the AD on a DC, GC, or Operations Master, as well as the data for all the other applications you may want to run on a server, such as the IIS metabase?
In most circumstances, even when suitable hardware is waiting to be hot-swapped into your production environment, the answer is in hours. Even when the restore is complete, you may have other work to do before Exchange is available for use again. For instance, the Store must replay transaction logs to roll forward messages and other items that are not fully committed to the database. The Store does this automatically, but applying masses of transactions at one time delays the startup operation (depending on processor speed and other load, 90 logs might take between 20 and 30 minutes to process on a slow server). Users will be yelling at you to get the system back online as quickly as possible, so it's going to be a time when stress levels are rising, which just adds to the piquant nature of the task. These are the facts of system management life. You must be prepared and able to conduct a well-planned restore of essential data in order to be successful. No one wants to explain to a CIO why the messaging system was unavailable for one or two days while staff fumbled their way through a restore. Knowing how to properly use and safeguard backup media is an important part of a backup strategy. Think of the following questions: After you perform backups, who will move the media to a secure location? Is the secure location somewhere local or remote? When will you use the tapes or other media for backup purposes again? How can you recover the backup media quickly if a disaster occurs?
11.4.2 Backups and storage groups
Store partitioning enables Exchange to take a granular approach to backup and restore operations. It is possible to back up or restore a single database instead of the entire Store. Figure 11.13 shows how you can select individual databases within a storage group for backup using the Windows Backup Wizard. When one or more databases from a storage group are processed, all of the transaction logs belonging to the storage group are also included in the backup media to ensure that the backup includes all transactions, including those that are not yet fully committed to the database. Therefore, it does not make sense to back up individual databases unless you have good reason to do so: Always process backups on a storage group level whenever possible. Note that NTBACKUP lists all of the servers in the organization, and you can perform a remote backup across the network, if you choose to do so. However, this is not a good option unless you have a very capable high-speed link between the source database and the target backup device.
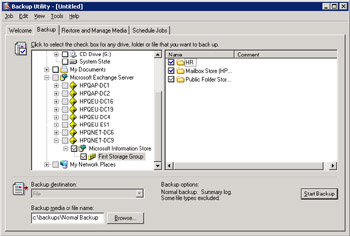
Figure 11.13: Using the Windows Backup Wizard to select databases.
Exchange reserves an additional special storage group for restore operations. When you restore a database, the Store overwrites the failed database with the database from the backup set and moves the transaction logs from the backup set into the temporary directory. The Store can then replay transactions from the logs, commit changes to the database, and make the database consistent and up-to-date. When the database is ready, the restore storage group turns over control to the normal storage group and operations recommence. This technique ensures that the other databases on a server continue to be operational when you have to restore a failed database.
11.4.3 Backup operations
A full backup of an Exchange storage group follows these steps:
-
The backup agent (NTBACKUP or a third-party utility) performs its own processing to prepare for the backup. This includes establishing the type of backup (incremental, full, or differential) and the target medium (tape or disk).
-
The backup agent makes a function call to ESE to inform the storage engine that it wishes to begin a backup. ESE logs event 210 to indicate that a full backup is starting.
-
Up to Exchange 2000 SP2, the Store then creates a patch file for each database. For example, PRIV1.PAT is the patch file for the default Mailbox Store. See the discussion about patch files later in this chapter for more information.
-
The current transaction log is closed and the Store opens a new transaction log. The Store then directs all transactions that occur during the backup to a new set of logs that will remain on the server after the backup completes.
-
The backup process begins. The backup agent requests data and the Store streams the data out in 64-KB chunks. ESE writes event 220 to the application event log (Figure 11.14) as it begins the backup of each database, noting the size of the file. On Exchange 2003 servers, the ESE backup API writes event 4028 to indicate the data transfer mechanism in use. For example, a backup to a disk file uses shared memory. Figure 11.15 illustrates a backup in progress.
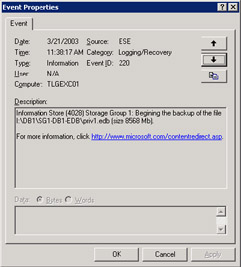
Figure 11.14: A full backup is about to start.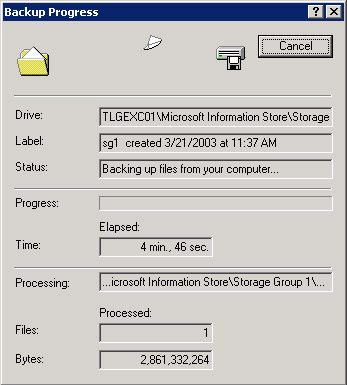
Figure 11.15: A backup in progress. -
As the Store processes each 4-KB page, it reads the page to verify that the page number and CRC checksum are correct to ensure that the page contains valid data. The page number and checksum are stored in the first four bytes of each page, and if either is incorrect, the Store flags a –1018 error to the Application Event Log. The backup API will then stop processing data to prevent you from taking a corrupt backup. This may seem excessive, but it stops administrators from blithely taking backups of databases that potentially contain internal errors. There is no point in taking a backup if you cannot restore the data, and restoring a corrupt database is of little use to anyone.
-
ESE logs event 221 as the backup of each database completes.
-
After all the pages from the target databases (a complete storage group or individually selected databases) are written to the backup media, the backup agent requests ESE to provide the transaction logs, which are then written to the backup media. ESE then logs event 223.
-
ESE only writes the set of transaction logs present when the backup starts to the backup media. If this is a full backup, ESE then deletes these logs (and notes the fact in event 224) to release disk space back to the system. It is quite safe to do this, since the transactions are committed to the database and are available in the logs in the backup set. Of course, if a situation occurs where a backup copy of a database is corrupted in any way (perhaps due to a tape defect), then you will need copies of every log created since the last good full backup to be able to perform a successful restore. For this reason, some administrators take copies of transaction logs to another disk location before a backup starts. Some may regard this behavior as a touch paranoid; others point to the failure rate for tapes and consider it a prudent step to ensure full recoverability.
-
The backup set is closed and normal operations resume. Successful completion is marked in event 213.
Exchange 2003 reports more detailed information in the event log. For example, you will see the size of the database files to back up plus details of the log files that the backup operation copies and then deletes. Windows 2003 servers report VSS events even though you do not use VSS backups. You can ignore these events and treat them as noise. When it completes processing, the backup utility usually reports the details of its work. For example, an NTBACKUP report of the successful backup of an Exchange storage group is as follows:
Backup Status Operation: Backup Active backup destination: File Media name: "Storage Group 1 created 3/21/2003 at 11:37 AM" Backup of "TLGEXC01\Microsoft Information Store\Storage Group 1" Backup set #1 on media #1 Backup description: "Set created 3/21/2003 at 11:37 AM" Media name: "Storage Group 1 created 3/21/2003 at 11:37 AM" Backup Type: Normal Backup started on 3/21/2003 at 11:38 AM. Backup completed on 3/21/2003 at 11:53 AM. Directories: 3 Files: 6 Bytes: 9,221,460,426 Time: 15 minutes and 22 seconds
Incremental and differential backups only copy transaction logs to backup sets. Incremental backups copy the set of logs created since the last backup, while a differential backup copies the complete set of logs created since the last full backup. Thus, to restore Exchange databases you need:
-
The last full backup
-
The last full backup plus all incremental backups taken since then
-
The last full backup set plus the last differential backup
Obviously, a full backup is the easiest way to restore, because there are fewer tapes to handle and less opportunity to make mistakes. However, if you rely exclusively on full backups, it is possible that you will miss some log files if you need to recover back to a time before the last full backup. For this reason, it is best practice to take incremental backups between full backups, leading to a backup schedule where you might take a daily full backup at 6:00 P.M., with an incremental backup at lunchtime when system load is often lower.
Exchange 2003 places a timestamp on Stores after successful backups. You can view the timestamp by selecting a Store and viewing its properties through ESM. Exchange records times for the last full and last incremental backups, as shown in Figure 11.16. Apart from anything else, the existence of the timestamp gives you confidence that a successful backup exists, as well as telling you how old it is.
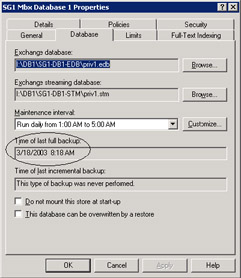
Figure 11.16: Last good backup timestamp.
11.4.4 Backup patch file
Traditionally, Exchange servers generated patch files (*.pat) during backup operations. The function of the patch file is to record details of page splits that occur while a backup is in progress. ESE maintains a separate patch file for each database. During backups, ESE streams pages from the databases to the backup media. Since users continue to create and send messages while the backup is proceeding, the chances are that transactions will occur in a page that is already committed into the database. Because the logs capture these transactions, they do not affect the backup unless the transaction results in a page split. Page splits occur when ESE finds that it cannot fit all of the data for a transaction into a single page. Message headers that contain more than 20 (approximately) recipients often need two or three 4-KB pages to fit all the header information. If a page split occurs, ESE notes details of the page in the patch file. Patch files only apply to operations to the EDB databases. Changes made to the streaming file do not cause page splits, so the data recorded in the set of transaction logs is enough to assure that ESE can reapply any changes.
ESE writes the patch files to the backup media at the very end of the backup to make them available in a restore situation. The first step in a restore is to apply the changes noted in the patch file to the database to make them consistent before rolling forward the transactions in the logs.
The patch file was a hangover from the original versions of Exchange and, to some degree, it complicated matters because administrators were never quite sure what its purpose was and how they should handle it. Microsoft solved the problem in Exchange 2000 SP2 by eliminating the patch file from backup processing. To remove the need for the patch file, ESE no longer advances the checkpoint and does not flush the Store buffers during full backup operations, which means that data can be recovered from the transaction logs, should the need occur. You no longer have to worry about the patch file, but its removal does mean that you cannot take a backup from an Exchange 2000 SP2 server (or later) and apply it to a server running an earlier version. This is both logical and correct, because all servers in an organization should run the same software level.
11.4.5 Checkpoint file
The checkpoint file (E00.CHK is the file used by the default storage group) maintains a note of the current log file position so that ESE knows the last committed transaction written to the databases in a storage group. ESE maintains a separate checkpoint file for each storage group.
The primary role played by the checkpoint file is during "soft" recoveries, when databases have closed down in an inconsistent manner through some system failure that has not resulted in a corrupt database. When the Information Store service restarts, ESE opens the checkpoint file and retrieves the location of the last committed transaction; it then begins to replay transactions from the logs from that point. While this is convenient, the checkpoint file is not mandatory for replays to occur, since ESE is able to scan the complete set of transaction logs to determine the point from which replays should commence. ESE does not write the checkpoint file to a backup set, because it serves no purpose during a "hard" recovery. In this scenario, you restore databases and transaction logs to different locations, so the ESE instance that controls the restore depends on the log information contained in the database header to work out what logs it should replay. In addition, ESE checks that all necessary log generations are present and available before beginning to replay transactions; it will not proceed if gaps exist. Other Windows components such as DHCP, WINS, and the AD that use ESE also maintain checkpoint files.
11.4.6 Restoring a database
Exchange 5.5 and earlier versions only support offline restores, meaning that the server can do no other work until the Information Store service is back online. Exchange now simply requires you to start the Information Store service before the restore can proceed; the Store can mount all of the unaffected databases, and users can connect to the mailboxes in those databases.
The Store is responsible for restore operations, and ESE uses a reserved storage group to enable online restores. The following steps occur:
-
The database or storage group affected by the failure is dismounted by the administrator or is rendered unavailable by a hardware problem, such as a disk failure. In this case, you must fix the hardware problem before a restore can proceed. The Information Store service must be running.
-
If you have a corrupt database in place, you probably want to overwrite the file on disk. Alternatively, you may prefer to take a copy of the corrupt database (EDB, STM, and associated transaction logs) before the restore overwrites the file and move it somewhere safe for later investigation. A database property controls whether the Store will allow the backup agent to overwrite a database. Either access the Store's properties and set the necessary checkbox, or simply delete the corrupt file before beginning the restore.
-
The backup agent initializes and displays details of the backup sets that you can restore from the available media. Figure 11.17 shows NTBACKUP in operation. In this case, we have experienced a failure of the default Mailbox Store, so we need to restore the database plus the transaction logs copied to the backup set during the last backup. The backup set is from a full backup operation, because both databases and transaction logs are available. Incremental and differential backup sets only hold transaction logs.
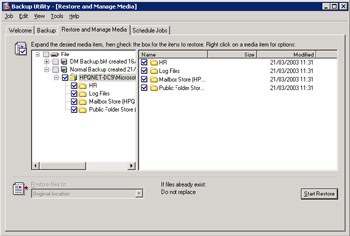
Figure 11.17: Selecting a database for restore. -
The backup agent notifies ESE that it wishes to begin a restore operation. The Store then launches an ESE recovery instance to manage the special recovery storage group. The recovery storage group only exists during restore operations.
-
The backup agent begins to stream data out of the backup set into the necessary databases, using direct Win32 file system calls to copy the files into the appropriate locations. This operation proceeds under the control of the Store, which uses the special reserved storage group for this purpose. You restore differential and incremental sets first, followed by the most recent full backup. If you follow best practice, and always take full backups whenever possible, restore operations are much simpler. Figure 11.18 shows how you direct the backup set to the target restore server. Note that because this is the last backup set that must be restored, we can set the "Last Backup Set" checkbox to tell the backup agent that it does not have to look for any other backup sets and can complete the recovery operation once the databases have been restored. For NTBACKUP, this check- box is a critical part of the restore operation, because ESE will perform none of the fix-up processing to make the database consistent until you tell ESE that it is OK to proceed by checking this box. However, if a database proves to be inconsistent after a restore, you can use the ESEUTIL utility to try to correct any errors.[1] Note that the user interface of some third-party backup utilities does not include the "Last Backup Set" checkbox, because the utility controls the entire restore operation, including the decision when to begin postrestore fix-up processing. You can also check the "Mount Database After Restore" checkbox to get the restored Mailbox Store into operation as quickly as possible after the restore is complete.
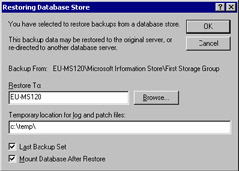
Figure 11.18: Setting parameters for the restore. -
ESE restores the EDB and streaming files to the production directory, but not the transaction logs, since they might overwrite logs that contain transactions that ESE later needs to replay. You must, therefore, provide a temporary location to hold the transaction logs from the backup set for the duration of the restore. Make sure that the temporary location (e.g., C:\TEMP\BACKUP) has enough disk space to accommodate all of the log files in the backup set. (See Figure 11.19.)

Figure 11.19: A restore operation in progress. -
ESE creates a file called restore.env in the temporary location to control the processing of transaction logs during the restore. The restore.env file contains information about the databases, paths, signatures, and other information used by the restore and replaces the older registry key used by previous versions of Exchange to signal that a restore operation was in progress. ESE creates a separate file for each restore operation. You can dump the contents of restore.env with the ESEUTIL utility. Figure 11.20 illustrates a set of files used in a typical restore operation.
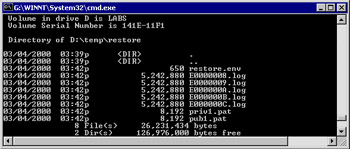
Figure 11.20: Files used by a restore operation in the temporary directory. -
Prior to Exchange 2000 SP2, after ESE restores the databases and transaction logs, it begins to apply any page splits to the respective databases. The application of page splits is not required after SP2. Next, the transaction logs are processed. During this process, ESE validates the log signature and generation sequence to ensure that the correct transaction logs are present and are available to recover transactions. If a log signature does not match the database signature, ESE returns error –610, and if it discovers a gap in the log generations, ESE signals error –611. If either of these errors is encountered, the recovery process is stopped. ESE has not yet replayed any transactions into the database, so you have a chance to fix the problem and start the restore again. Fixing the problem may require that you check the signatures on the databases and logs to ensure that they match, or discover why a gap exists in the log generations.
ESE actually reads two sets of logs during the restore. First, it processes the logs held in the temporary location, and then it processes the logs in the normal location that have accumulated since the backup. Transaction logs contain data for all of the databases in a storage group, so if you are restoring a single database, ESE must scan all the data in the logs to isolate the transactions for the specific database and then proceed to apply them. ESE ignores all of the other data in the logs. This phase of the operation may be the longest of all, depending on the number of transaction logs that have to be processed.
Once the data in the transaction logs has been applied, the recovery storage group performs some clean-up operations, exits, and returns control to the primary storage group (the storage group that is being restored), which is then able to bring the newly restored databases back online. ESE also deletes the files in the temporary location. ESE notes details of all of the recovery operations in the Application Event Log.
In the case of differential or incremental restores, only the transaction logs are loaded into the temporary location and processed there. At the end of a successful restore, ESE writes event 902 into the application event log. ESE also records the details of the restore operation in a text file (the file is named after the backup set). To be certain that everything is OK before you allow any users to connect to the store, check that ESE logs event 902 and that ESE has recorded no errors in the text file.
11.4.7 Third-party backup utilities
NTBACKUP is a basic backup engine and while you certainly can use NTBACKUP to perform backups of Exchange data, its interface and features lack functionality, especially when you are dealing with high-end servers. The same situation existed for Windows before Exchange came along, and for that reason, there are many highly functional and feature-rich backup third-party backup utilities available for Windows today. Most of these products have created add-on modules or new version releases to support Exchange, so NTBACKUP is not the only option.
Exchange provides two DLLs for use by backup utilities to access Exchange data. These are ESEBACK2.DLL, which interfaces with the service (Store, SRS, etc.) that the application wishes to connect to in order to take a backup or restore files, and ESEBCLI2.DLL, which provides the interface to the backup client. A system registry entry makes backup utilities aware of the client interface, and Exchange-enabled utilities such as NTBACKUP look for the registry entry when they start up to determine whether they need to dynamically load and display Exchange resources.
The DLLs include the API necessary for backup utilities to process Exchange data. The following functions illustrate the flow of a backup operation:
-
HrESEBackupPrepare: Establishes an RPC connection to Exchange and returns a list of the available databases available for backup.
-
HrESEBackupSetup: Used by the backup utility to tell Exchange which storage group it wishes to back up. Each storage group uses its own backup set. You can perform a restore operation of a single database by selecting it from the list held in a backup set.
-
HrESEBackupOpenFile: Opens the selected database for read access. Both EDB and streaming file are included.
-
HrESEBackupReadFile: Reads the database in 64-KB chunks. This function also performs checksum calculation and verification.
-
HrESEBackupCloseFile: Closes the database.
-
HrESEBackupGetLogAndPatchFiles: Gets a list of all the log file names to include in the backup set. ESE backs up these files using the HrESEBackupOpenFile, HrESEBackupReadFile, and HrESEBackupCloseFile functions.
-
HrESEBackupTruncateLog: Delete any obsolete transaction logs after a full backup. Truncation only happens after ESE successfully backs up all selected databases. If you do not back up all of the databases in a storage group for any reason, ESE cannot delete the logs.
-
HrESEBackupInstanceEnd: End the backup for the instance (storage group or selected database).
-
HrESEBackupEnd: Disconnect from the RPC connection to Exchange.
It is possible to run concurrent backup processes, with each process taking care of a storage group. Interestingly, Windows has a "FilesNot- ToBackup" registry key, which is used to record information about files that NTBACKUP should not include in a normal file-level backup (e.g., \exchsrvr\*data\*.*"—don't back up anything in the Exchange server data directories). The Exchange databases are a good example of such files, since the Store always has these files locked against access by other processes, and file- level backup utilities cannot, therefore, read these files.
Exchange provides a similar set of functions to restore databases from backup sets, including HrESERestoreOpen, HrESERestoreAddDatabase, and HrESERestoreOpenFile to support the restore of a single database or a complete storage group. While it is technically possible to run multiple concurrent restore operations, best practice suggests that it is safer to concentrate on a single restore at a time, just to reduce the potential for error. Taken together, the Exchange backup API is comprehensive and open to third-party vendors to exploit. Table 11.3 lists some of the major third- party backup products that support Exchange. Use the Web address to get information about the latest product features to help you decide which product best meets your needs.
| Company | Product | Web Address |
|---|---|---|
| CommVault | CommVault | http://www.commvault.com |
| Veritas | Backup Exec | http://www.veritas.com |
| Legato Systems, Inc. | Networker for Windows NT | http://www.legato.com |
| HP | Omniback | http://www.hp.com |
| Computer Associates | ArcServe | http://www.ca.com |
| BEI Corporation | Ultrabac | http://www.ultrabac.com |
It is always difficult to justify the additional expense of buying a package to replace a standard utility, especially when there is a standard utility that appears to do the job in an adequate manner. The cost of deploying, managing, and supporting the new utility across multiple servers also has to be taken into account. It is a mistake to run different backup products within an organization, since this makes it much more difficult to move data between servers. Due to the different ways that software can stream data out to tapes, it is highly unlikely that one backup software package will be able to read a tape created by another. Once you allow diversity, you create a potential situation where you cannot restore a backup for one reason or another. Moreover, Murphy's Law dictates that this situation occurs just after a server hosting thousands of users has crashed and you cannot bring it back online quickly.
For this reason, try to standardize on a single backup product and use the same backup media (tapes and drives) to gain maximum flexibility. You never know when you will need to move data onto a different server and it is embarrassing to discover that you cannot, because the target server is not equipped with a drive that can read the backup media.
A specialized package often provides very useful features that are missing in the standard utility. In practice, third-party backup products usually provide three major enhancements over the NTBACKUP program:
-
Scheduling
-
Speed
-
Control
Specialized backup products tend to support high-end features, such as unattended backups, automated loading and unloading via tape libraries, and network backup to very large storage silos (CD-equipped juke boxes or similar). Such features are not critical to small or medium servers, but you need to consider them for any server that hosts large databases.
Microsoft designed the architecture of Exchange with online backups in mind. In other words, there is no requirement to stop the different services (Information Store, MTA, System Attendant, and so on) while the backup is proceeding. It might, therefore, appear that speed is of little concern. After all, you can start a backup each morning and have it running alongside users as the day proceeds. This is true, but it is only a partial picture. Backups can proceed online, but you can only perform restores by halting access to the database that you want to restore. If backup software processes data quickly, it is normal that restores are quick too. However, restores normally proceed at half the speed of a backup. Best practice is to plan for backups to take four hours or less to keep any subsequent restore operation to less than the length of an eight-hour working day.
A combination of software and hardware improvements has increased performance and backup over the years. It is now possible to pump data out to devices faster than they can accept it. The Exchange developers know that the backup API can stream data out of the Store at very high rates to a null device. Hardware slows things down, but, even so, equipped with a dual-striped tape, developers were able to achieve real backup rates of more than 40 GB/hour. Some installations have exceeded this rate in production environments equipped with quad-DLT devices working in a RAID array, which can process data at nearly 45 GB/hour. Some have reported that they can achieve consistent rates of nearly 40 GB/hour. It is important that you keep an eye on the quantity of data that you must back up over time. It is likely that the amount of data will grow, and if you do not increase the capacity of the backup hardware to handle increased amounts of data, your backups will take longer and longer.
Increased speed and reduced backup times make it more feasible to take full backups every day rather than the traditional cycle of full backups every week with incremental backups taken on the days in between. The advantage gained here will only accrue if you have to restore the server. You will be glad to find that it is much easier and faster to restore from a single full backup than to go through the hoops and loops of restoring from the last full backup followed by all the incremental backups since. With large servers that have multiple Stores, each of which might hold up to 50 GB, the backup times may be a touch too long to take full backups every day, but with smaller servers, it is certainly the best way to perform backups.
Better control over backup operations is the final advantage provided by third-party utilities. NTBACKUP is quite content to overwrite the same tape with a new backup every day if you leave the tape in the tape drive, as some people have discovered to their loss. Commands such as "eject tape after backup is complete" prevent accidents from happening and contribute to data security. This type of problem is unlikely to occur in datacenters where skilled operations staff work, but it is entirely possible in places where people only know how to insert tapes into drives. Effective tape handling is critically important for installations dealing with large stores that span more than one tape. You do not want to get into a situation where a backup never actually completes because someone forgot to take out the first tape and insert a new tape at the appropriate time. A number of the third-party backup utilities also allow you to back up the system registry, disks, and the Exchange databases in a single operation—much easier than having to make (and restore) three separate backup tapes.
It is important to understand that while third-party backup software can provide some valuable advantages, it is another piece to fit into your system configuration matrix. New releases of the backup software must be qualified against existing versions of Exchange and then against new versions of Exchange. You should also check the backup software against service packs of both Exchange and Windows. The Exchange development team cannot check its product against every third-party product or extension, so it is entirely possible that the installation of a service pack will introduce a problem that only becomes apparent when a backup operation is attempted. On the other hand, even worse, is a problem that suddenly appears during a restore. The complex interaction between Exchange, Windows, and any third-party product adds weight to the argument that you should test all combinations of software products (including patches) before they are introduced to production servers.
Good backups provide a parachute to administrators when problems occur, and if the backups do not work when you need them, then anyone involved may soon be looking for a new job, so it is reasonable to regard backup software as a very important part of the Exchange administrator's armory.
11.4.8 Backing up individual mailboxes
Some third-party backup utilities support a feature that allows administrators to back up one or more selected mailboxes instead of a complete Store, a feature known as a brick-level backup. NTBACKUP does not support this feature. Third-party products accomplish this feat by performing a privileged logon through MAPI to the user's mailbox and then reading out all of the items in the mailbox to the backup set. The application also records the necessary contextual (mailbox and folder structure) information to allow the items to be restored in the same order that they were retrieved.
This is an arrangement very different from a normal backup, where ESE provides data in a continuous stream based on low-level internal database structures rather than the structure of mailboxes. Microsoft never designed MAPI for use as a backup interface, and the combination of MAPI and item-level retrieval does not result in fast performance. Backing up an individual mailbox can take between four and eight times as long as backing up the raw data using the Backup API, and there's no guarantee that you'll be able to restore an exact replica of a mailbox in terms of either content or format if the need occurs.
Some administrators believe that being able to take a mailbox-level backup is a useful feature, because it allows them to quickly restore a mailbox if the complete mailbox is deleted in error, or to restore specific items if a user happens to delete a number of important items by mistake. The usefulness of the feature was unquestioned with early versions of Exchange, since the loss of items by mistake or error required a complete restore of a database (normally on a test server) to retrieve the information. However, the provision of the Deleted Items Recovery feature in Exchange 5.5, the Deleted Mailbox Recovery feature introduced in Exchange 2000, and Exchange 2003's Mailbox Recovery Center have largely removed the requirement to restore databases to fix problems caused by user or administrator error. Some argue, including me, that brick-level backups are now an anachronism of the past and that they are not worth the bother. Others, possibly those who have been forced to restore databases to retrieve large collections of messages, believe that these backups are valuable. It all depends on your operating environment, but, given the options, I think it best to set an extended deleted item retention period on Stores where users are likely to want to recover items (such as Stores used by executives) and avoid brick-level backups if at all possible.
11.4.9 Restoring an Exchange server
Coming in to find that your Exchange server is down and will not boot or has experienced a catastrophic disk failure is an experience that few system administrators relish. True, you can view the situation as a chance to demonstrate your calm, analytical skills in problem solving and deep knowledge of the hardware and software components that make up an Exchange server, but most of us react like human beings and panic.
As with most challenges, the people who have a well-thought-out plan usually do better than those who plunge in to try to get things working without putting their brains into gear. The history of Exchange is littered with examples where administrators caused further damage by failing to carry out procedures correctly, such as attempting to restore using an invalid set of transaction logs. Among the basic questions that you should ask at this time are:
-
Is the basic server still working? Check whether Windows can boot and load applications. Note which applications are unable to start and check to see if any reasons are in the Event Log.
-
Does any obvious sign exist that some hardware is unavailable to the server? Are multiple components affected by a single failure such as a controller problem that blocks access to multiple disks?
-
Are all of the items required to perform a recovery available? These include replacement hardware (anything from a complete server to an individual disk). Can the server still connect to the network and access kits and other useful items on file shares? Do you have access to service packs, hot fixes, and third-party applications? Can you restore the backup tapes on the server?
-
After you have sketched out the overall shape of the problem, you will find that the correct course of action is either:
-
Replace hardware components and restore any software and data affected by the failure. For example, replace a failed disk and restore an Exchange database and transaction logs.
-
Replace a complete server with similar hardware and rebuild the operating environment as quickly as possible.
-
Clearly, the second option is far more difficult to execute if only because more replacement components are usually necessary. You may have a server on stand-by and be able to take the disks from the failed server and insert them into the stand-by and restart. However, it is more likely that you will have to assemble hardware to form a server that is as close as possible in terms of processing power, memory, and storage to the original server, perhaps by cannibalizing the original hardware.
Once the server hardware is ready, you can begin to:
-
Reinstall the same version of Windows, including any service packs and hot fixes.
-
Restore the last full good backup of any applications and data for all disk drives. Obviously, you can leave some of the restores until you get Exchange back on the air and users are happily connected to their mailboxes.
-
Restore the system state. This includes the system startup files, the all-important system registry, the IIS metabase, SYSVOL, and so on. The registry and the IIS metabase are critical to Exchange. If the system configuration is different, you may have to reboot a number of times in safe mode to get everything working properly.
-
Ensure that the server can connect to the AD. If the server was a DC or GC, you will have to restore the last good backup of the AD from the server and wait for replication to backfill updates that have occurred since. The alternative is to perform an "authoritative restore" to wind back to a particular point in time. You can also demote the server from DC status using NTDSUTIL and then make it a DC again with DCPROMO. This will force a complete replication cycle to begin again. Many dangers lurk in these options, and the right answer varies from situation to situation and environment to environment. Either make sure that you know the best way to restore a server with AD or avoid problems by never running Exchange on a DC (normal best practice in large enterprises). The critical points here are to ensure that Exchange can connect to a DC and GC to access configuration data and that DNS is available.
-
Run the Exchange setup program in /disasterrecovery mode. Microsoft designed this mode to read configuration data about the Exchange server from the AD and use the information to rebuild the configuration. This is the reason why you need AD connectivity, and the object for the server that you are restoring must exist in the AD before you attempt to rebuild Exchange. Remember to restore any optional component.
-
Apply any service packs and hot fixes to Exchange. The Store is sensitive to version updates and may not be able to restore a backup taken with an earlier or later version of Exchange, so it is always safest to run exactly the same version as you had on the failed server.
-
It is a good idea to set the Exchange MTA to start manually rather than automatically and also disable the SMTP virtual servers until you have completed all restore operations and the server works normally. This step will prevent email traffic from flowing into the server while you work. You do not want to get into a situation where you lose email because it arrives at a server that you then have to scrub because some problem occurs in the restore.
-
Restart the server.
-
Restore all of the storage groups that were on the failed server. Restore the last full good backup first, and then apply any transaction logs taken by copy backups since. Remember to check the Last Backup Set option for the last backup to force the Store to roll forward transactions from the logs. Hopefully, the transaction log disk will be intact and all of the logs taken since the last backup will be available.
-
After each restore, check that the Store can mount the restored databases and that you can connect to mailboxes. Consider blocking client access to the server until all restores are complete and you are happy that the server is ready for use.
-
Check that any connectors work and that you can send mail to people on other servers and outside the organization.
-
If the server hosted the Site Replication Service, restore the component and the SRS database (only required in mixed-mode organizations).
-
If the server hosted the Key Management Server, restore the component and then the KMS database (not required for Exchange 2003).
-
Take a full backup.
-
Announce another triumph of system administration and let users get back to their mailboxes.
Depending on whether you can put your hand on the items necessary to perform the restore, the whole operation may take from four hours (every- thing ready and immediately accessible) to as long as it takes to find replacement hardware. Be sure that you know how you are going to perform the steps before you commit to a Service-Level Agreement that calls for a server to be back online in a stated time. A number of critical points occur from this discussion. You need to:
-
Have access to hardware or know how to get replacement hardware
-
Have access to software, including service packs, hot fixes, and third- party applications. It is a good idea to create a disaster recovery CD that holds all of the necessary software to recover a server, but make sure that this is kept up-to-date and that you know where it is stored.
Unbelievably, it is now easier to rebuild an Exchange server than ever before. The reason is simple: Administrators have had a lot of practical experience in restoring servers over the years, and the Exchange development team has captured the knowledge gained in these situations regarding the way the software performs restores.
11.4.10 Recovery servers
Medium to large Exchange installations often maintain a dedicated server for recovery operations. You can use a recovery server as replacement hardware to get users back to work quickly after a catastrophic hardware failure (the need for this capability is reduced in Exchange 2003 with the introduction of the Recovery Storage Group), but the most common use of recovery servers is to retrieve specific information from an Exchange database taken from another server—for example:
-
A mailbox that has been deleted in error and the deleted mailbox retention period is past
-
A mailbox or items that you need to recover for legal or other reasons
-
A public folder deleted when it is the only replica in the organization
-
A specific item or items deleted by a user that he or she is unable to retrieve through the normal deleted items recovery option
-
Recovery of mailboxes from a failed server to PSTs followed by subsequent reload of mailboxes to a server using new hardware
Given the increased frequency of discovery actions, which seek copies of email to prove points in legal arguments, lawyers have also used recovery servers to retrieve all the messages from several mailboxes. Sometimes, you have to recover messages sent over an extended period, which necessitates the restore of multiple backups to ensure that you do not omit a specific message. Recovery operations such as this are not pleasant to work on, so they are to be avoided at all costs. Unfortunately, lawyers usually make the decision when a recovery is required.
You can also use a recovery server to run database maintenance utilities against a backup copy of a database to check it for any lurking corruption or to test that you are taking reliable backups. For example, let us assume that you have noticed some –1018 events recorded in the application event log. Normally, these errors indicate that the drive where the database is located has a hardware problem. To check things out, you can restore a backup of the database to the recovery server and run the ESEUTIL utility to verify whether the database is in good health. If the database checks out (in other words, ESEUTIL reports no checksum or other errors), you can then arrange to verify the hardware to discover the root cause of the –1018 errors. If ESEUTIL fails, you know that a serious problem is in the database and that it will soon fail, even if you replace the hardware. Even so, you can arrange to transfer mailbox data to another server before the database fails, using the Move Mailbox option or the ExMerge utility.
Recovery servers are also useful if you want to test an add-on product against real-life data, especially backup and antivirus utilities. Far too many products work wonderfully in demo environments when they only have to process limited amounts of data only to encounter problems in production. Testing against a server loaded with real data allows you to determine whether the product will work when you put it into production.
You must allocate suitable hardware to the recovery server. This is not a production system, so you do not need the same type of multi-CPU, highly redundant disk subsystem configuration deployed in production. However, there are some prerequisites:
-
Enough disk space must be available to restore the largest database that you might need to recover. Alternatively, the system should be capable of adding additional disks quickly should the need occur.
-
The server should use the same backup software as used in production, and must be able to read the tapes created on the production servers.
-
The server should be running the same version (including service packs and hot fixes) of Windows and Exchange.
-
If you do not want to assign dedicated hardware to recovery servers, virtual servers can make excellent recovery servers providing they can connect to the various devices used in recovery operations.
Delivery of email to personal stores (PST files) poses another problem. Instead of recovering a single database, you now must recover all of the individual PSTs that are located on a failed disk. Not only will this operation require a surprising amount of disk (Exchange does not force users to delete email from their personal stores to stay within quotas, so they tend to keep more), the number of individual files makes this a tricky operation. While you might not think that it is the responsibility of an administrator to look after personal data, all bets are off when a server crashes, and you will probably find that you have to recover PST files as well. It is a good idea to factor in all aspects of email recovery in your disaster recovery plans. You can also use a recovery server to check how long it will take ESEUTIL to rebuild a database and whether you will save a significant amount of disk space after you have rebuilt the database. This is useful if you want to know how long you need to take a server offline to run the rebuild.
Having a recovery server available is only part of the equation. Knowing how to restore data quickly and effectively is the other. You cannot treat the two in isolation from each other, so make sure that you perform some trial runs and check that data can be recovered using production backups on the recovery hardware.
11.4.11 Recovering a Mailbox Store
Because Exchange depends so heavily on AD for mailbox and configuration data, you must take some specific steps to ensure that you can access mailboxes after you restore databases onto a recovery server. The basic requirements are that the recovery server is in a different AD forest than the original server. The forest name can be different and the two forests can share a network. However, you must install the recovery server into a different Exchange organization—but one with the same name. Remember that there can only be one Exchange organization in a forest, so by installing the recovery server into a different forest you prevent the recovery server from interfering with other servers in the "production" Exchange organization. You should also stop users from attempting to log on or otherwise access the recovery server while you are working.
Once you install Exchange on the recovery server, you can restore the databases using the normal restore procedure. Before proceeding with the restore, you must use ESM to rename the logical names of the storage group and the database to match the names of the storage group and database from the original server. The names should match exactly—including the name of the original server if specified—but it does not matter if the underlying file names (e.g., MAILBOX.EDB) are different. You can either create the storage group and databases with the correct names or rename them to the appropriate values. It is best practice to use the same storage group names and to follow a convention for database names throughout an organization to reduce the room for error during a recovery operation. Figure 11.21 illustrates the difference between the logical names of a Store as viewed through ESM and the underlying physical file names.

Figure 11.21: Database logical and file names.
You are going to overwrite the database on the recovery server with the database from the original server, so you must use ESM to amend the target database's properties to allow the backup to overwrite the files. If you use an offline backup for the restore, you are copying data taken at a specific point in time, and there is no need for the Store to replay data in transaction logs to make the database consistent. Thus, you can delete the existing database and logs and overwrite them with the data from the backup set. However, you must set the properties of the database to allow the restore to overwrite the files, even when you use an offline backup.
Before restoring any data, check that the LegacyExchangeDN values for the administrative group and organization for original and recovery servers match. The LegacyExchangeDN AD attribute is used extensively by Exchange to identify objects, as well as ensuring backward compatibility with earlier versions. In this case, a successful restore depends on the Store being able to verify with the AD that a database it wishes to mount is registered with the AD. When you create a new database on an Exchange server, the Store stamps the database with the names of the organization and administrative group that it belongs to, and only a server that matches these names can mount the database thereafter.
The simplest approach to the problem is to specify the same values for the organization and administrative group as the server that you wish to retrieve data for when you install Exchange on the recovery server. If you have installed Exchange and used different values for the organization or administrative group, you can adjust the LegacyExchangeDN values before attempting to recover data by using the LegacyDN utility from the \utils\ tools\i386 folder on the server CD. Essentially, you create a replica of the original environment for the restore to proceed correctly. You can make the necessary changes with other LDAP tools such as ADSIEDIT or LDIFDE, but it is much easier and quicker to use LegacyDN.
| Warning | Do not run LegacyDN in a production environment, since it is very easy to make a mistake that will severely affect the Exchange organization. At worst, if you change LegacyExchangeDN values within an organization, you may have to restore the Active Directory and all Exchange servers. |
Figure 11.22 shows the LegacyDN utility in action. In this case, the recovery server is "RESTORESERVER" and it is in the "RESTOREDOMAIN.COM" domain. We want to restore a database from the "NSIS European Messaging Team" administrative group in the Compaq organization. When you run the LegacyDN utility on a server, it scans the AD to find what administrative groups exist. You can then select an administrative group and change its base details (or LegacyExchangeDN stem) to reflect the values in the database that you want to restore. If you proceed with the recovery without changing these values, you will be able to restore the database from tape (or other media), but the Store will not be able to mount the restored database because the LegacyExchangeDN values do not match. To fix the values, we insert the names of the original administrative group and organization and click on the "Change Leg" button, then stop and restart the Information Store service to make the change effective. In this case, the net effect is to change the existing LegacyExchangeDN stem of:
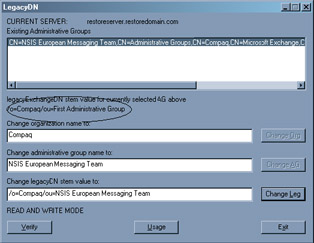
Figure 11.22: The LegacyDN utility.
/O=Compaq/OU=First Administrative Group
to:
/O=Compaq/OU=NSIS European Messaging Team
If you are unsure about the value of the LegacyExchangeDN attribute for the administrative group that the database comes from, you can use the ADSIEDIT utility to read the information about the administrative group from the Microsoft Exchange configuration container.
Figure 11.23 shows the result of using ADSIEDIT to drill down through the AD configuration naming context to the Services container and then the Microsoft Exchange container, followed by the organization container. Each administrative group is a subcontainer under the organization. Select the administrative group that the database came from and view its properties. Select the LegacyExchangeDN attribute from the drop-down list and note the value reported. In this instance, the value is:
/O=Compaq/OU=NSIS European Messaging Team
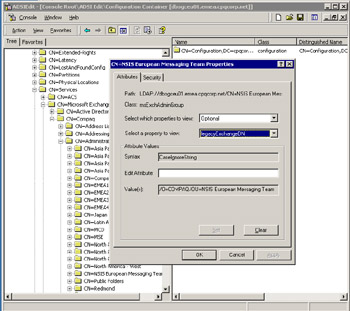
Figure 11.23: Checking the LegacyExchangeDN value for an administrative group.
In Exchange 5.5 terminology, this equates to the name of the organization followed by the name of the site, so you can see how the "legacy" of the Exchange 5.5 naming convention is preserved in the attribute for use by Exchange. With all of the LegacyExchangeDN values adjusted, you can then:
-
Dismount the target database on the recovery server.
-
Restore the backup set from the original server to overwrite the database files on disk.
-
Check the Application Event Log to ensure that the backup utility or ESE has reported a problem and that the Store has been able to mount the restored database.
The most common reason why the restore will not work is that the name of the database in the backup set does not match the name of the target database as shown in ESM. The most common reason why the Store fails to mount the database after the restore successfully creates the database is that the LegacyExchangeDN values do not match. In either case, the Store signals the errors in the Application Event Log. Look for event 1088 for details of a distinguished name mismatch—this will tell you that you need to adjust the LegacyExchangeDN values.
At this point, we have mounted a database that contains the mailboxes that we want to access, but we still need to associate them with AD accounts before we can use a client to open the mailbox and retrieve information. Remember that mailboxes are attributes of AD accounts rather than entities in their own right. Without an association with AD accounts, mailboxes are repositories that you can see through ESM but cannot access with a client or other program.
In section 11.5.1, about the Mailbox Recovery Center, we will review how to link accounts with mailboxes. Some small differences exist when you use a recovery server. First, you must create the AD accounts (the names that you use do not have to match the original accounts). Second, you link the new accounts to mailboxes in the restored database. The easiest way to associate mailboxes with accounts is to use the Mailbox Cleanup Agent option in ESM. To invoke the agent, open the Mailbox Store and select "Mailboxes," use right-click to view the context-sensitive menu, and select "Run Cleanup Agent" from the menu. The Mailbox Cleanup Agent works by scanning a Mailbox Store to look for mailboxes that do not have a link to an AD account. Any mailbox that cannot be resolved is marked with a red circle with a white X in the center. Figure 11.24 illustrates what you might see after running the agent. All of the mailboxes are visible, but apart from the system mailboxes, a valid account is not shown in the "Last Logged on By" column. This implies that the Mailbox Cleanup Agent was unable to resolve the SID of the account last used to access a mailbox against the AD, so you know that a link does not exist between the mailboxes and AD accounts.
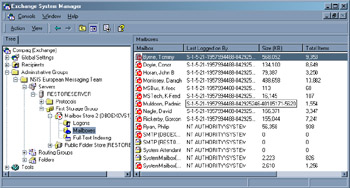
Figure 11.24: Unassociated mailboxes after a restore.
After the Mailbox Cleanup Agent finishes processing, you can select the mailboxes that you want to work with and use the Reconnect option (from the right-click menu) to link them to an AD account. This is a satisfactory approach for a small number of mailboxes, but it quickly becomes tiresome if you want to connect hundreds of mailboxes. In this situation, you can use the MBCONN utility from the tools folder on the Exchange 2000 CD. Apart from being able to identify a complete list of mailboxes in the Store that do not have an associated AD account, MBCONN generates an LDF load file with details of the missing accounts. You can then use the LDIFDE utility to process the LDF file to recreate the accounts and run MBCONN again to reconnect the accounts with the mailboxes.
Once you connect accounts to mailboxes, you can use a client to log on to the mailbox and access the content. Default Exchange permissions block administrator access to mailboxes, so if you want to use your account to access the mailboxes, you must first change the permissions on each mailbox to allow access to that account. If you want to recover information for a user, you can select it from the mailbox and copy it to a PST, or use the EXMERGE utility to recover data for multiple mailboxes at one time. Remember that prior to Outlook 2003, you are restricted to a 1.8-GB maximum for PSTs, so you may not be able to export all of the contents from large mailboxes to a single PST.
The exact amount of time needed to perform the different steps to restore and access a Mailbox Store on a recovery server depends on the size of the database, the backup technology you use, and the amount of data you need to retrieve after the restore is complete. Use the figures listed in Table 11.4 as a guideline, but remember that you should verify the estimates in your own environment.
| Task | Estimated Time | Notes |
|---|---|---|
| Prepare recovery server by installing Windows 2000/2003, Exchange 2000/ 2003, all service packs and hot fixes, backup software, configuring DNS, and verifying all steps. | 4–6 hours | Availability of suitable hardware (including correct tape drives), software kits, and licenses |
| Preparation of Exchange 2000/2003 environment prerestore | 1 hour | — |
| Restore Mailbox Store | 1 hour | Depends on size of database. In one hour, you should be able to restore 16–30 GB depending on the hardware and software combination. |
| Set up Active Directory accounts | 30 minutes | Depends on the number of accounts to be used |
| Run Mailbox Cleanup Agent | 10 minutes | The agent normally completes faster than this. |
| Reconnect mailboxes to AD accounts | 1 minute per mailbox | — |
| Access mailbox and recover data | 30 minutes per mailbox | You need to configure a client to access the mailbox, decide what data you want to recover, and then export to a PST. The actual time could be a lot longer if the mailbox is large. |
| Clean up server after recovery | 1 hour | Delete files and prepare server for next recovery operation. |
Clean-up operations are always the most popular work for system administrators. In this case, the recovery servers hold sensitive information in the recovered databases, so it is critical that you secure the data for as long as you need it and then delete it.
11.4.12 Rapid online, phased recovery
Rapid online and phased recovery (ROPR) is a technique used in conjunction with recovery servers to restore service very quickly to users. The idea is straightforward. Recover a failed server as quickly as possible with new hardware and reinstall Exchange, but then do not attempt to restore the databases on the newly installed server. Instead, Exchange will notice that the databases it expects are missing when the Store attempts to mount the files. This prompts Exchange to ask you whether it should recreate the databases. If you answer affirmatively, the Store recreates and mounts the databases and you can then proceed to reconnect user accounts to their mailboxes. Of course, the mailboxes are completely empty, but users will be able to start to send and receive email immediately to complete the "rapid online" part of the exercise.
As soon as you restore service to users, you can recover the original databases to a recovery server and use ExMerge to export mailbox data to PSTs. Then, as ExMerge finishes processing each mailbox, you can provide the PST to its owner and tell him or her how to move messages from the PST back into the mailbox, which is what we mean by "phased recovery."
This technique is not perfect and there are many flaws. For example, ExMerge will not recover rules and other settings such as custom views, which Outlook holds in the mailboxes that you destroy when you force Exchange to recreate the database. The biggest plus point is that users get online quickly, so the technique is far more applicable to situations such as an ISP rather than corporate environments where users expect a fully restored mailbox as soon as the server is available.
[1] . Usually, you end up with a restored database and a set of transaction logs accumulated since the time of the last backup, so you need to replay the transactions from the logs into the restored database. This is done with the ESEUTIL /CC /T<storage group instance> command.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 188