59.
 | C++ Neural Networks and Fuzzy Logic by Valluru B. Rao M&T Books, IDG Books Worldwide, Inc. ISBN: 1558515526 Pub Date: 06/01/95 |
| Previous | Table of Contents | Next |
Chapter 8
BAM: Bidirectional Associative Memory
Introduction
The Bidirectional Associative Memory (BAM) model has a neural network of two layers and is fully connected from each layer to the other. That is, there are feedback connections from the output layer to the input layer. However, the weights on the connections between any two given neurons from different layers are the same. You may even consider it to be a single bidirectional connection with a single weight. The matrix of weights for the connections from the output layer to the input layer is simply the transpose of the matrix of weights for the connections between the input and output layer. If we denote the matrix for forward connection weights by W, then WT is the matrix of weights for the output layer to input layer connections. As you recall, the transpose of a matrix is obtained simply by interchanging the rows and the columns of the matrix.
There are two layers of neurons, an input layer and an output layer. There are no lateral connections, that is, no two neurons within the same layer are connected. Recurrent connections, which are feedback connections to a neuron from itself, may or may not be present. The architecture is quite simple. Figure 8.1 shows the layout for this neural network model, using only three input neurons and two output neurons. There are feedback connections from Field A to Field B and vice-versa. This figure also indicates the presence of inputs and outputs at each of the two fields for the bidirectional associative memory network. Connection weights are also shown as labels on only a few connections in this figure, to avoid cluttering. The general case is analogous.
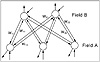
Figure 8.1 Layout of a BAM network
Inputs and Outputs
The input to a BAM network is a vector of real numbers, usually in the set { –1, +1 }. The output is also a vector of real numbers, usually in the set { –1, +1 }, with the same or different dimension from that of the input. These vectors can be considered patterns, and the network makes heteroassociation of patterns. If the output is required to be the same as input, then you are asking the network to make autoassociation, which it does, and it becomes a special case of the general activity of this type of neural network.
For inputs and outputs that are not outside the set containing just –1 and +1, try following this next procedure. You can first make a mapping into binary numbers, and then a mapping of each binary digit into a bipolar digit. For example, if your inputs are first names of people, each character in the name can be replaced by its ASCII code, which in turn can be changed to a binary number, and then each binary digit 0 can be replaced by –1. For example, the ASCII code for the letter R is 82, which is 1010010, as a binary number. This is mapped onto the bipolar string 1 –1 1 –1 –1 1 –1. If a name consists of three characters, their ASCII codes in binary can be concatenated or juxtaposed and the corresponding bipolar string obtained. This bipolar string can also be looked upon as a vector of bipolar characters.
Weights and Training
BAM does not modify weights during its operation, and as mentioned in Chapter 6, like the Hopfield network, uses one-shot training. The adaptive variety of BAM, called the Adaptive Bidirectional Associative Memory, (ABAM) undergoes supervised iterative training. BAM needs some exemplar pairs of vectors. The pairs used as exemplars are those that require heteroassociation. The weight matrix, there are two, but one is just the transpose of the other as already mentioned, is constructed in terms of the exemplar vector pairs.
The use of exemplar vectors is a one-shot learning—to determine what the weights should be. Once weights are so determined, and an input vector is presented, a potentially associated vector is output. It is taken as input in the opposite direction, and its potentially associated vector is obtained back at the input layer. If the last vector found is the same as what is originally input, then there is resonance. Suppose the vector B is obtained at one end, as a result of C being input at the other end. If B in turn is input during the next cycle of operation at the end where it was obtained, and produces C at the opposite end, then you have a pair of heteroassociated vectors. This is what is basically happening in a BAM neural network.
NOTE: The BAM and Hopfield memories are closely related. You can think of the Hopfield memory as a special case of the BAM.
What follow are the equations for the determination of the weight matrix, when the k pairs of exemplar vectors are denoted by ( Xi, Yi), i ranging from 1 to k. Note that T in the superscript of a matrix stands for the transpose of the matrix. While you interchange the rows and columns to get the transpose of a matrix, you write a column vector as a row vector, and vice versa to get the transpose of a vector. The following equations refer to the vector pairs after their components are changed to bipolar values, only for obtaining the weight matrix W. Once W is obtained, further use of these exemplar vectors is made in their original form.
W = X1T Y1 + ... + XkT Yk
and
WT = Y1TX1 + ... + YkT Xk
Example
Suppose you choose two pairs of vectors as possible exemplars. Let them be:
X1 = (1, 0, 0, 1), Y1= (0, 1, 1)
and
X2 = (0, 1, 1, 0), Y2 = (1, 0, 1)
These you change into bipolar components and get, respectively, (1, –1, –1, 1), (–1, 1, 1), (–1, 1, 1, –1), and (1, –1, 1).
1 [-1 1 1] -1 [1 -1 1] -1 1 1 -1 1 -1 -2 2 0 W = -1 + 1 = 1 -1 -1 + 1 -1 1 = 2 -2 0 -1 1 1 -1 -1 1 -1 1 2 -2 0 1 -1 -1 1 1 -1 1 -1 -2 2 0
and
-2 2 2 -2 WT = 2 -2 -2 2 0 0 0 0
| Previous | Table of Contents | Next |
Copyright © IDG Books Worldwide, Inc.
EAN: 2147483647
Pages: 139