FUNDAMENTAL CHARACTERISTICS OF GEOGRAPHIC DATABASES
|
|
Geographic data is characterized mainly by its four components: geographic position or coordinates; attribute values; topological relationships, and time (Aronof, 1991). The modeling of geographic data is based on field-based and object-based approaches.
The field-based approach treats a spatial object as a continuous surface, and data is stored and processed as a collection of regular grid cells with a given measure and area. The object-based approach treats a spatial object as an identifiable entity with which key or object-id are associated. Through this model, data is stored and processed as a list of coordinates.
These different models have their advantages and disadvantages. For a detailed discussion about their trade-offs, see Aronof (1991), Maguire, Goodchild, & Rhind (1991), and Laurini & Thompson (1992). Since data analysis and storing, and data querying are performed on object-based spatial data, the vector format is the most spatial data model used in GIS.
A fundamental requirement for geographic database design which uses the vector format is the ability to model spatial properties, i.e., to associate part of space with an attribute. Parts of space are usually represented by points, lines, and regions and are known as geometric features. Basically, the geographic data models are based on geographic objects and geographic classes (or themes or layers). The geographic objects correspond to the individual data items of the real world. They are defined by a description component, which is a set of descriptive or alphanumeric attributes (e.g., the name and population of a country), and a spatial component representing the object location in the underlying geographic space and shape. The geographic classes correspond to a collection of geographic objects having the same structure or type.
The spatial structure of a geographic object cannot be modeled by any built-in data types, such as integer, string, etc., in a computer environment. In order to overcome this lack of modeling power, abstract data types (ADTs) were introduced. The main idea of this approach is to hide the structure of the data types from users and allow them to access the data types only through a set of operations. The spatial types for representing the geometric features are Type point, Type polyline, and Type region. For each of them a set of operations is defined and the result of spatial operations should be one of the existing data type. They can be either unary or binary operations with Boolean, scalar, or spatial results. Many of these operations concern the spatial topological relationships among objects.
The description of spatial relationships between spatial objects and the definition of an appropriate terminology for these relationships and their semantics has been dealt with by using theoretical models (Egenhofer & Franzosa, 1991, 1995). These studies concern the definition of the fundamental properties of the spatial "regions" and the formalization of a minimal set of spatial topological relationships using point-set theory. This is based upon the intersection of the boundary and interior of two objects, named A and B, to be compared, and distinguishes only "empty" and "non-empty" intersections. A 2×2 matrix, called the 4-intersection, represents these criteria as follows:
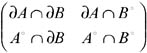
By considering the above-mentioned empty and non-empty values, 16 binary topological relations can be distinguished. Among them, only eight can be realized for two regions with connected boundaries if the objects are embedded in R2. They are called disjoint, meet, equal, inside, contains, covers, covered by, and overlap (see Egenhofer & Herring, 1990). This set of eight relations provides a complete coverage, and they are mutually exclusive so that exactly one of these topological relations holds true between any two regions (Egenhofer & Franzosa, 1991).
Concerning data modeling, there are two classic data models that are mostly used to define and manage GDBs: the relational and object-oriented data models. The relational models aim at distributing the attributes in various relations so that some rules on database design known as normal forms hold. The relation, as the single construct of relational models, is limited to modeling complex spatial entities. Therefore, there have been several proposals to extend the original relational model with spatial abstract data types (ADTs) (Stonebraker, Runestein, & Guttman, 1983; Stonebraker & Rowe, 1986; Stonebraker, 1986, Gardarin et al., 1989; Gargano, Nardelli, & Talamo, 1991). Even though relational data models are powerful because of their theoretical validity and are easy to implement, they are not completely suitable for the manipulation of complex data, such as spatial data. The object-oriented paradigm (see Hughes, 1991; Ullman, 1988;. Kim, 1989), with its well-known common characteristics such as the object identifier, data abstraction, inheritance, and encapsulation, is recognized as the most advanced approach for modeling spatial data. It was promoted originally to overcome the limitations of relational data models.
In an object-oriented (O-O) model, each instance of an entity is modeled as an object which includes a behavior description. Objects comprise both attributes and methods. Methods are also considered as procedure-valued attributes. This model provides the notion of class. Several spatial data models, which benefit the power of such a paradigm, have been proposed (see Worboys, Hearnshaw, & Maguire, 1990; Gunther & Riekert, 1993; Milne, Milton, & Smith, 1993; Leung, Leung, & He, 1999; Rigaux, Scholl, & Voisard, 2001).
Spatial Partition Hierarchies
The best-known metaphor in a GDB is that of a map. A map is a generalized, simplified abstraction of reality. It consists of a set of topographic data displayed in visual form providing a frame of reference (e.g., the location data or position data).
Maps are the most natural way to convey geographical information, and they are excellent support for visualizing analytical data about phenomena that have a geographical extent. They are also as faithful as possible to the real-world location and shape.
A central element of maps is the concept of partition. A partition is a subdivision of the 2-D plane into pairs of disjoint regions where each region is associated with an attribute which can have a simple or complex structure. There are many examples of partitions in the real world, like the subdivision of a given territory into administrative boundaries such as countries, states, and counties, or in the classification of land according to soil type, etc.
Partitions are identified as an important spatial concept, and they are widely used in the generation of many scale-dependent maps from a single database. This is called generalization (Brassel & Weibel, 1988). This process is used to convert spatial data from one scale-dependent representation into another by calculating the geometry of a more abstract object through the union of the geometries of lower level objects. It is referred to as abstract generalization and is concerned basically in changing the object representation according to the level of abstraction at which data is represented. The main goal of abstract generalization is spatial analysis. A given set of geographic objects may have distinct representations depending on the level of abstraction. At a more abstract level, we obtain a more simplified representation of objects. This provides a hierarchy of partitions over geographic objects where each level corresponds to a given representation (Rigaux & Scholl, 1994; Volta & Egenhofer, 1993; Frank, Volta, & McGranaghan, 1997). Therefore, the hierarchy of partitions of a single 2-D space can be sketched as follows (see Rigaux & Scholl, 1995):
Definition 1: Let S be a subset of plane ![]() and G ∊ 2S be a partition of
and G ∊ 2S be a partition of ![]() , such that ∪G = S and ∀g, g′ ∊ G g ∩ g′ = Ø. Let G1,…, Gn be the set of partitions of S and ≼ be the partial order defined as follows:
, such that ∪G = S and ∀g, g′ ∊ G g ∩ g′ = Ø. Let G1,…, Gn be the set of partitions of S and ≼ be the partial order defined as follows:
![]()
Definition 2: Let Ag1 and Ag2 represent the geometric attributes of objects belonging to two distinct classes, the domains of which are defined by D(Ag1) = ![]() ∊ 2S, D(Ag2) = G2 ∊ 2S. The partial order ≼ among spatial partitions induces partial order, renamed Contains relationship, on geographic classes and objects.
∊ 2S, D(Ag2) = G2 ∊ 2S. The partial order ≼ among spatial partitions induces partial order, renamed Contains relationship, on geographic classes and objects.
Contains (or space inclusion) is the most common hierarchical relationship among geographic classes and objects, the inverse of which is the well-known "is-in" relationship. For instance, in the case of administrative subdivision, a country contains several states, and states contain counties. Furthermore, any two spatial entities related by inclusion relationship satisfy some constraints on their common attributes. In other words, the value of some numeric non-spatial or aspatial attributes of an object belonging to a given level is the aggregation of the corresponding attribute values of objects belonging to the lower level. For example, the population of a given state is the sum of the population of its counties. With regard to the geometry, aggregation implies the spatial union of the geometry of objects belonging to the lower level.
|
|
EAN: 2147483647
Pages: 150