35.5 AUTOMATIC SPEECH RECOGNITION
|
| < Day Day Up > |
|
35.5 AUTOMATIC SPEECH RECOGNITION
To make computers recognize our speech is an extremely difficult task because of the variations in our speech—pronunciation and speech signal characteristics differ according to our mood and health.In addition, a person's accent indicates things such as his educational, geographical, and cultural background. The iceberg model of speech, shown in Figure 35.4, represents the information contained in the speech signal. The information in the lower portion of the iceberg is difficult to capture during the analysis of a speech signal for speech recognition applications.
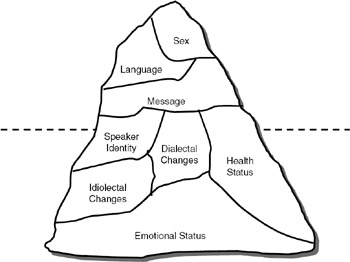
Figure 35.4: Iceberg model of speech.
Research in speech recognition technology is limited mainly to recognizing the message and speaker recognition. Recognizing the other features has not met with much success.
Automatic speech recognition is a very challenging task mainly because speech characteristics vary widely from person to person. Practical speech recognition systems have many limitations and are capable of recognizing only limited vocabulary or a limited number of speakers.
In the present speech recognition systems, the speech signal is analyzed and compared with prestored templates of the words to be recognized. Using this approach, a good recognition rate is obtained if the number of speakers is limited or if the computer is trained to recognize the speakers.
Future speech recognition systems need to incorporate various knowledge sources such as syntax (grammar) and semantics (meaning) knowledge sources to achieve high recognition rates. Though many such research systems are available, commercial systems are still a few years away. The iceberg model indicates the various knowledge components that need to be developed and incorporated for achieving a complete speech recognition system.
| Note | The iceberg model of speech depicts the various characteristics that need to be recognized from speech waveforms. Only those characteristics that are at the top of the iceberg can be recognized at present. |
35.5.1 Speech Recognition Methodology
Automatic speech recognition (ASR) is basically a pattern recognition task, as shown in Figure 35.5. The input test signal is analyzed, and features are extracted. This test pattern is compared with reference patterns using a distance measure. Then a decision is made based on the closest match. Because speaking rates vary considerably, time normalization has to be done before calculating the distance between a reference pattern and the test pattern. The different stages of ASR are described in the following paragraphs.
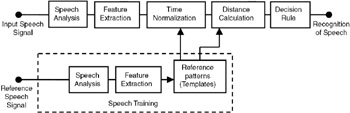
Figure 35.5: Speech recognition methodology.
Automatic speech recognition involves pattern recognition. It consists of three phases: feature extraction, time normalization, and distance calculation.
Feature extraction: The feature set extracted from the speech signal should be such that the salient properties of the signal are reflected in these features. A number of feature sets have been proposed, such as energy, zero crossing rate in selected frequency bands, and LPC coefficients. The most commonly used feature set is LPC coefficients. The speech signal is divided into small units called frames; each frame is of about 10 msec duration. For each frame, LPC parameters are obtained and stored. For example, if a word is of 0.3 second duration, the speech signal is divided into 30 frames and for each frame, the LPC parameters are calculated and stored as the feature set. If the speech recognition system is designed to recognize say 10 words, for each word spoken by the user, the feature set is extracted and stored. This is known as the training phase, in which the user trains the computer to recognize his voice. The feature set stored during the training phase is known as the reference pattern. Later, when the user speaks a word, the features are extracted again, and the feature set obtained is known as the test pattern. The test pattern is compared with all the reference patterns, and the closest match is found to recognize the word.
In the feature extraction stage, the speech waveform is divided into frames of about 10 msec duration, and the parameters such as LPC coefficients are calculated for each frame. The feature set for each word to be recognized is stored in the computer and is called the reference pattern.
Time normalization: Speaking rates vary considerably, so time normalization has to be done to match the test pattern with the reference pattern. For instance, during the training phase, the word spoken by the user might be of 0.350 second duration, but during the recognition phase, the duration may be 0.352 second. To compare the reference pattern with the test pattern, the two patterns have to be normalized in the time scale. This is achieved using dynamic time warping, which can be done either by mapping the test pattern onto the reference pattern or bringing both patterns to a common time scale.
Time normalization is a process wherein the reference pattern is mapped on to the test pattern by normalizing in the time scale. This is required because the duration of the reference pattern and the test pattern may not be the same.
Let T(n) be the feature vector obtained from nth frame of the test utterance and R(m) be the feature vector obtained from mth frame of the reference utterance. So,
![]()
For time normalization, a warping function defined by m = w (n) has to be found, as illustrated in Figure 35.6. The dynamic time warping procedure is used to find the optimal path m = w(n) that minimizes the accumulated distance between the test pattern and the reference pattern, subject to the end point and path constraints. For finding the path, the following recursive solution, proposed by L.R. Rabiner of Bell Laboratories, is used:
![]()
where Da(T(n), R(m)) is the accumulated distance from (T(1), R(1)) to (T(n), R(m)) and d(T(n), R(m)) is the distance between nth test frame and mth reference frame.
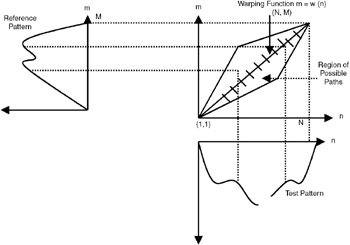
Figure 35.6: Time normalization of test pattern and reference pattern: the warping function.
| Note | Time normalization is done through a dynamic time warping function. This involves minimizing the accumulated distance between the test pattern and the reference pattern. |
Distancistanc calculation: Calculation of distance between test and reference patterns is done along with time normalization. Distance calculation is a computationally burdensome step in speech recognition. From a computational effort point of view, two distance measures, Euclidian and the loglikelihood, have been found to be reasonable choices.
A simple Euclidean distance is defined by
![]()
The two distance measures used for calculating the distance between the reference pattern and the test pattern are Euclidean distance measure and loglikelihood distance measure.
Another distance measure is the loglikelihood measure proposed by Itakura and is defined as
![]()
where aR and aT are the LPC coefficient vectors of the reference and test patterns, and vT is the matrix of autocorrelation coefficients of the test frame.
Decision rule: Using the distance scores obtained form the dynamic time warping algorithm for the V reference patterns (V being the vocabulary size), a decision is made using either the nearest-neighbor (NN) rule or the K nearest-neighbor (KNN) rule. In NN rule, the pattern that gives the minimum distance is chosen as the recognized pattern. The KNN rule is applied when the number of reference patterns for each word in the vocabulary is P, with P > 2. In such a case, the distance scores between the test pattern and each of the reference patterns are calculated and arranged in ascending order. The average of the first K (= 2 or 3) distance score is taken as the final distance score between the test word and the reference word. Minimum distance criterion is applied on such final distance scores obtained for the entire vocabulary.
To develop a speech recognition system, the computer has to be trained by the user. Each word is spoken by the user, and the templates are created. The training methods are divided into (a) casual training; (b) averaging; and (c) statistical clustering.
Training procedure: For template creation, the training procedure is the most crucial step that reflects on the performance of the system. The training methods can be divided into three classes: (i) casual training; (ii) averaging; and (iii) statistical clustering. In the casual training method, a reference pattern is created for each word spoken during the training mode. In averaging method, a word is spoken n times, and the features are averaged to obtain a single reference pattern. In the statistical clustering method, each word in the vocabulary is spoken n times; these n patterns are grouped into clusters using pattern similarity measures, and from each cluster, templates are obtained.
| Note | In the statistical clustering method, each word is spoken a number of times and the patterns are grouped into clusters using pattern similarity measures. Templates are created from each cluster. This method increases the recognition accuracy. |
35.5.2 Categories of Speech Recognition Systems
Automatic speech recognition is a complex task for the following reasons:
-
The characteristics of speakers vary widely, and to store templates for all speakers requires huge memory. Processing is also time consuming and hence speech recognition without considerable delay is not possible, at least not yet.
-
The characteristics of the speech signal vary even for the same individual. For instance, if the speaker is suffering from a cold, the speech recognition system will fail to recognize the speech even if the system has been trained for that user.
-
Pronunciation varies from region to region (known as dialectal changes) and from individual to individual (known as idiolectal changes). As it is said, there is no English—there is American English, British English, Indian English, and so on. Even in a country, every region has peculiarities. To capture all these variations is still an active research area.
-
Every country has many languages, and multilingual speech recognition systems are required to provide practical speech recognition systems.
Because of all these difficulties, practical speech recognition systems, to be commercially useful, can be categorized as follows:
Isolated word recognition systems: Isolated word recognition systems accept each word in isolation: between two successive words, there should be a gap, a silence of about 100 msec. In such systems, the end points of the word can be found easily, making the recognition highly accurate.
Continuous speech recognition systems: These systems accept continuous speech, speech without any gap between words. However, since recognizing word boundaries is difficult in continuous speech, accuracy may not be very high, particularly if the vocabulary is very large.
| Note | The main difficulty in continuous speech recognition is to identify the boundaries of words. Due to this difficulty, recognition accuracy is not very high; only up to 80% accuracy can be obtained. |
Keyword extraction systems: In some applications, the system needs to recognize a certain number of predefined keywords. Continuous speech is given as input to the system, and the system will recognize the presence or absence of any of the keywords in the sentence.
Limited vocabulary speaker-dependent systems: For applications such as data entry and voice dialing, only a limited number of words are required. Such systems can be trained by the speaker for his voice to achieve 100% recognition accuracy. These systems are known as limited vocabulary speaker-dependent systems.
Speaker recognition systems are divided into speaker verification systems and speaker identification systems. Speaker verification involves checking whether a speaker belongs to a set of known speakers. Speaker identification involves finding out the identity of the speaker.
Limited vocabulary speaker-independent systems: For applications such as voice-based interactive voice response systems, the vocabulary will be limited but the speech of any speaker should be accepted. Instead of storing templates for only one individual, representative multiple templates are stored for each word, to take care of variations due to speakers. The processing and storage requirements will be high in this case, but reasonably good accuracy (about 95%) can be achieved for such limited vocabulary speaker-independent systems.
Unlimited vocabulary speaker-dependent systems: For applications such as dictation machines, any word spoken should be accepted, but the system can be trained with about 100 words that capture the phonetic data corresponding to that speaker. Such unlimited vocabulary speaker-dependent systems achieve an accuracy of about 60% to 80%.
Unlimited vocabulary speaker-independent systems: To develop speech recognition systems that will understand any word spoken by any person would lead to a world wherein we can talk to computers the way we talk to fellow human beings. This has remained an elusive goal.
Multilingual speech recognition systems: If we succeed in developing unlimited vocabulary speaker-independent systems for one language, we can extend the system to recognize multiple languages.
Language recognition systems: For a computer to recognize multiple languages, the first module required is the language recognition module. After recognizing which language is spoken, the corresponding language's knowledge source has to be invoked to recognize the words in that language.
Speaker recognition systems: These systems are used to find out who the speaker is. Speaker recognition systems are categorized into (i) speaker verification systems; and (ii) speaker identification systems. Speaker verification is to find out whether a test speaker belongs to a set of known speakers. Speaker identification involves finding out the identity of the speaker after making a binary decision whether the speaker is known or not. Speaker recognition can be one of two types: text-dependent or text-independent. In text-dependent speaker recognition systems, reference patterns are generated from the features extracted from a predetermined utterance spoken by the speaker, and the same utterance is used in the test pattern. For applications in which the restriction that a predetermined text has to be spoken cannot be imposed, text-independent speaker recognition is required. Speaker recognition has two types of errors: false rejection of a truthful speaker and false acceptance of an imposter.
Speech recognition systems are divided into the following categories: isolated word recognition systems, continuous speech recognition systems, keyword extraction systems, limited vocabulary speaker-dependent systems, unlimited vocabulary speaker-dependent systems, limited vocabulary speaker-dependent systems, limited vocabulary speaker-independent systems, language recognition systems, and multilingual speech recognition systems.
Language recognition and multilingual speech recognition systems are still active research areas. It will be a few more years before such systems are successfully demonstrated.
35.5.3 Applications of Speech Recognition Technology
In spite of the present limitations on the type of speech input, speech interaction with computers is of immense practical application. Reaching the goal of completely natural speech communication with computers is still far off, but application-oriented systems in which the task is controlled are being developed. These applications include:
-
Computer data entry and editing with oral commands using isolated word recognition systems.
-
Voice response systems with limited vocabulary and syntax.
-
Retrieval of information from textual databases in speech form through telephones.
-
Aids to the physically handicapped. Reading machines for the blind and speech synthesizers for the speech impaired are of immense use.
-
Computer-aided instruction for teaching foreign languages and pronunciation.
-
Entertainment on personal computers.
-
Military applications such as (a) human-machine interaction in command and control applications; (b) automatic message sorting from radio broadcasts using keyword extraction systems; and (c) secure restricted access using speaker recognition.
Some of the applications of speech recognition are computer data entry through speech, voice response systems, aids to the physically handicapped, and military applications for human-machine interaction through speech.
Hopefully, in the not too distant future, we will be able to communicate with computers the way we communicate with each other, in speech. The graphical user interface (GUI) will be slowly replaced by voice user interface (VUI). Subsequently, automatic language translation may be possible.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 313
- Challenging the Unpredictable: Changeable Order Management Systems
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Context Management of ERP Processes in Virtual Communities
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare