11.3 Overview of Redlanda Multilanguage-Based RDF Framework
11.3 Overview of Redland ”a Multilanguage-Based RDF FrameworkThough the majority of RDF/XML APIs are based on Perl, Python, Java, and PHP, several are in other language-based APIs, including ones in C# and CLOS, as discussed in the last section. For instance, if you're interested in working with Tcl, XOTcl ” based on MIT's OTcl ” has RDF/XML-processing capability (http://media.wu-wien.ac.at/). Additionally, Dan Brickley has created an experimental RDF system written in Ruby called RubyRDF (at http://www.w3.org/2001/12/rubyrdf/intro.html). And if you're interested in a system that supports Tcl as well as Ruby, and Perl, and Python, and Java, and so on, then you'll want to check out Redland. One of the older applications supporting RDF and RDF/XML, and one consistently updated to match effort in the RDF specification is Redland”a multilanguage API and data management toolkit. Unlike most of the other APIs discussed in this book, Redland has a core of functionality exposed through the programming language C, functionality that is then wrapped in several other programming languages including Python, Perl, PHP, Java, Ruby, and Tcl. This API capability is then mapped to a scalable architecture supporting data persistence and query. Because of its use of C, Redland is port and platform dependent; it has been successfully tested in the Linux, BSD, and Mac OS X environments. At the time of this writing, Version 0.9.12 of Redland was released and installed cleanly on my Mac OS X. When writing this section, I tested the C objects, as well as the Python and Perl APIs, the most stable language wrappers in Redland.
11.3.1 Working with the Online ToolsTo quickly jump into Redland and its capabilities, there are online demonstrations of several aspects of the framework and its component tools. One online tool is an RSS Validator, which validates any RSS 1.0 (RDF/RSS) file. RSS is described in detail in Chapter 13, but for now, I'll use the validator to validate an RDF/XML file built from several other combined RSS files. Figure 11-1 shows the results of running the RSS Validator against the file. Figure 11-1. Output of Redland RSS Validator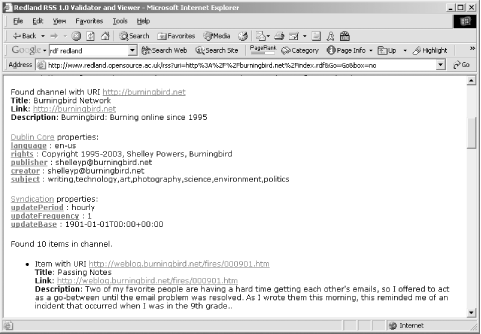 Another validator is an N-Triples Validator, which makes a nice change from RDF/XML validators. There's also a parser test page, as well as an online database that you can actually manipulate as you test Redland's capabilities with a persistent store. I created a new database called shelley and loaded in my test RDF/XML file, monsters1.rdf . I could then query the data using Redland's query triple or by printing out the data and clicking on any one of the triples to access it. The latter is particularly useful because the query that would return the statement is generated and printed out, giving you a model to use for future queries. As an example of a triple query in Redland, the following returns all statements that match on the PostCon reason predicate: ?--[http://burningbird.net/postcon/elements/1.0/reason]-->? The format for the triple pattern is: [subject]--[predicate]-->[object] for resource objects and the following for strings: [subject]--[predicate]-->"object" Use the question mark to denote that the application is supposed to match on any data within that triple component. 11.3.2 Working with the Redland FrameworkThe Redland site contains documentation for the core C API, as well as the primary wrappers: Perl, Python, and Java. The API Reference covers the C API, and each wrapper has a separate page with information specific to that wrapper language. For instance, if you access the Perl page, you'll find a table of application objects; next to each object is a link to the documentation page for the core Redland function (written in C), such as librdf_node , and next to that is a link to the associated language class. Clicking on the C version of the object opens a page with a listing of all the functions that class supports. Clicking on any of those opens a page that describes how the function works and the parameters it accepts. Clicking on the language wrapper object provides a page of documentation about the object, formatted in a manner similar to other documentation for that language. For instance, Figure 11-2 shows the documentation page for the Perl Statement object, including the traditional Synopsis. Figure 11-2. Documentation for the Perl Redland object, Statement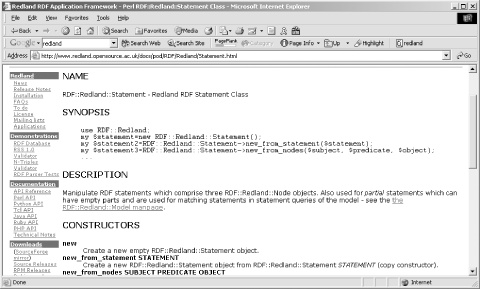 However, the Python documentation was a real eye- opener , following a traditional Python documentation approach ( pydoc ) as shown in Figure 11-3. Figure 11-3. Documentation for the Python Redland object, Statement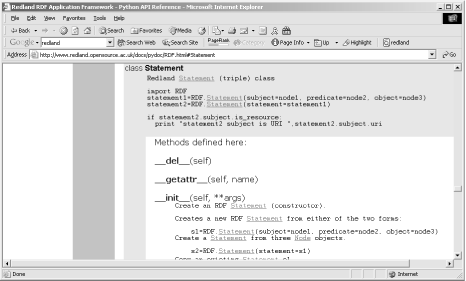 Normally I wouldn't spend space in a book showing documentation, but I was intrigued by Redland's use of language-specific documentation style to document different wrappers. In addition to the style, though, the documentation demonstrates how the object is used in an application, which is critical for learning how to use the API correctly. Redland has persistent database support through the Berkeley DB, if you have access to it, or you can use the memory model. You specify which storage mechanism to use when you create the storage for the RDF model you're working with. In addition, you can also specify what parser you want to use, choosing from several, including Raptor, the parser that comes with Redland, which you can use independent of Redland. Other parsers you can use are SiRPAC, Repat, RDFStore, and so on. To use Redland, program your application using the native API or whichever of the wrappers you're comfortable in, compile it, and run it, in a manner similar to those shown in Chapter 10. The main difference is that the language wrappers are wrappers”behind the scenes, they invoke the functionality through the native API classes. Table 11-1 shows the main Redland classes, focusing on two languages I'm most comfortable with, Perl and Python, in addition to the native API. Table 11-1. Mapping between Perl, Python, and C classes in Redland
There are other classes in each wrapper, but the ones shown in Table 11-1 are the ones of primary interest. 11.3.3 A Quick DemoI created two small applications, one in Perl, one in Python, to demonstrate the interchangeability of languages within the Redland framework. The Perl application, shown in Example 11-2, creates a new Berkeley DB datastore and attaches it to a model. The application then adds a statement, opens the example RDF/XML document located on the filesystem, and parses it into the model using the Redland parser method parse_as_stream . Once loaded, it serializes the model to disk as a test and then flushes the storage to disk. Example 11-2. Perl example loading data into storage !/usr/bin/perl # use RDF::Redland; # create storage and model my $storage=new RDF::Redland::Storage("hashes", "practrdf", "new='yes',hash-type='bdb',dir='/Users/shelleyp'"); die "Failed to create RDF::Redland::Storage\n" unless $storage; my $model=new RDF::Redland::Model($storage, ""); die "Failed to create RDF::Redland::Model for storage\n" unless $model; # add new statement to model my $statement=RDF::Redland::Statement->new_from_nodes(RDF::Redland::Node->new_from_uri_ string("http://burningbird.net/articles/monsters1.htm"), RDF::Redland::Node->new_from_uri_ string("http://burningbird.net/postcon/elements/1.0/relatedTo"), RDF::Redland::Node->new_from_uri_ string("http://burningbird.net/articles/monsters5.htm")); die "Failed to create RDF::Redland::Statement\n" unless $statement; $model->add_statement($statement); $statement=undef; # open file for parsing # RDF/XML parser using Raptor my $uri=new RDF::Redland::URI("file:monsters1.rdf"); my $base=new RDF::Redland::URI("http://burningbird.net/articles/"); my $parser=new RDF::Redland::Parser("raptor", "application/rdf+xml"); die "Failed to find parser\n" if !$parser; # parse file $stream=$parser->parse_as_stream($uri,$base); my $count=0; while(!$stream->end) { $model->add_statement($stream->current); $count++; $stream->next; } $stream=undef; # serialize as rdf/xml my $serializer=new RDF::Redland::Serializer("rdfxml"); die "Failed to find serializer\n" if !$serializer; $serializer->serialize_model_to_file("prac-out.rdf", $base, $model); $serializer=undef; warn "\nDone\n"; # force flush of storage to disk $storage=undef; $model=undef; Once the data is stored in the database from the first application, the second application opens this store and looks for all statements with dc:subject as predicate. Once they are found, the application prints these statements out. When finished, it serializes the entire model to a stream, and then prints out each statement in the stream, as shown in Example 11-3. Example 11-3. Python application that accesses stored RDF/XML and prints out statementsimport RDF storage=RDF.Storage(storage_name="hashes", name="practrdf", options_string="hash-type='bdb',dir='/Users/shelleyp'") if not storage: raise "new RDF.Storage failed" model=RDF.Model(storage) if not model: raise "new RDF.model failed" # find statement print "Printing all matching statements" statement=RDF.Statement(subject=None, predicate=RDF.Node(uri_string="http://purl.org/dc/elements/1.1/subject"), object=None) stream=model.find_statements(statement); # print results while not stream.end(): print "found statement:",stream.current() stream.next(); # print out all statements print "Printing all statements" stream=model.serialise() while not stream.end(): print "Statement:",stream.current() stream.next() When the first application is run, the new database is created. However, the second application just opens the persisted datastore created by the first Perl application.
|
