Common Gateway Interface (CGI)
| < Day Day Up > |
The oldest and still a very common way to add interactivity to a Web page is through a CGI program. Common Gateway Interface (CGI) is a protocol standard that specifies how information can be passed from a Web page through a Web server, to a program, and back from the program to a browser in the proper format. Unfortunately, many people confuse the actual program that does a particular task with the CGI protocol. In reality, the program is just a program. It just happens to be a CGI program because it was written to pass information back and forth using the CGI specification. Furthermore, CGI programs can be written in any language the server can execute; whereas Perl most commonly is associated with CGI, there is no reason that C, C++, Pascal, Visual Basic, or even FORTRAN couldn't be used to create a CGI program.
It is possible to create anything with CGI. Some common CGI applications include:
-
Form processing
-
Database access
-
Security and authentication systems
-
Browser-specific page delivery
-
Banner ad serving
-
Guest books
-
Threaded discussion
-
Games
Later on in the section, we'll take a look at how such programs can be built from scratch, or even downloaded from various Web sites for little or no cost. Regardless of how we end up obtaining our server-side programs, it is important to understand at least in general how they work.
Browser-Server Interaction Close-up
As an overview of how the browser and server exchange information, consider the various steps that happen when interacting with a user providing data through a form fill-out.
-
The user submits a form.
-
The form is sent to the server using HTTP and eventually to the CGI program using the following steps:
-
The server determines whether the request is a document or program request by examining execution settings and path .
-
The server locates the program (often in the cgi-bin directory on the server) and determines if the program can be executed.
-
The server starts the program and sends the user submitted data and any extra information from the environment to the CGI program.
-
The program runs.
-
The server waits for the program to exit and potentially produce any output (optional).
-
-
The CGI program finishes processing data and responds to the server with a result or error message, although it may also send nothing back at all.
-
The Web server passes any response back to the browser via HTTP.
-
The browser reads the incoming data stream and determines how to render any returned data, usually by examining the MIME type found in the Content-type response header.
| Note | Server launching of the program (Step 2c) is operating system “dependent and may require starting a new process, which could be slow, thus contributing to CGI's reputation for being slow. |
It appears that a key aspect of understanding how server-side programs like CGIs work is understanding how the HTTP protocol works.
Example HTTP Dialog
Web browsers and servers communicate using the Hypertext Transfer Protocol (HTTP), which is described thoroughly in Chapter 16. The protocol is a simple request response protocol in which a browser requests a resource from a server and the server responds with either an error message like a 404 or a success code and some data. To demonstrate this discussion, we can use a telnet program or other utility to manually talk to a Web server. To do this, use a telnet program to access a Web server and set the port number to 80, which is the default TCP port number for a Web server. In UNIX, Linux, or Max OS X “based systems, you can type at a command prompt:
telnet www.democompany.com 80
You could use a graphical telnet application such as the built-in one for Windows. Just make sure to set the port value to 80 in a similar fashion to the dialog shown here:
In some Windows environments, you may have a command prompt instead, which would look something like this:
Once connected to the Web server you will get little feedback, but type in the proper HTTP request. A simple request would be
GET / HTTP/1.1 Host: www.democompany.com
Then press ENTER twice to send a blank line, without which the operation won't work.
Once the server processes the request, the result should look something like the listing shown here:
HTTP/1.1 200 OK Server: Microsoft-IIS/5.0 Date: Sun, 06 Jul 2003 20:28:51 GMT Content-type: text/html Content-length: 1200 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en"> <head > <title> Sample XHTML Document </title> </head > <body > ...content... </body >
If a Web browser were reading this data stream, it would read the Content-type line, and then determine what to do with the data. Browsers have a mapping that takes a MIME type and then determines what to do with it. Figure 13-1 shows the mapping file from Netscape Navigator.
Figure 13-1: Sample MIME mapping dialog box under Netscape
Notice in the preceding code that the content type is text/html . This has the action of a browser, which would render the HTML within the browser window. Remember that Web servers can serve just about any type of data and pass that data to a plug-in or helper, or query the user to save the file.
| Note | MIME stands for Multipurpose Internet Mail Extension and was originally developed to sort out the various multimedia enclosures that could occur in an e-mail message. However, today these content stamps are used for purposes well beyond e-mail and, as you have seen, are used to tell Web browsers what kind of data they are receiving so they can figure out how they might process it. |
CGI Output: MIME Types
Given that you now have seen the manual execution of an HTTP request, what is important to the Web browser? The simple answer is the MIME type and its associated data. In most cases, the pages being delivered are HTML-based, so the MIME type should be text/html. With this idea in mind, it should be easy to write a CGI program that generates an HTML page. To do this, you need to print out the MIME type indication Content-type: text/html , followed by the appropriate page markup and content.
| Note | A significant debate rages about the use of text/html versus the more standards oriented application/xhtml+xml , text/xml or application/xml MIME types, particularly when the content is server-generated. Given the inconsistent support by browsers at the time of this edition's writing, it is still the best idea to stick with MIME types of just text/html. Let's hope this changes soon, but for now better safe than sorry. |
The following small Perl program shows how this might be done; any language, including C, Pascal, or BASIC, could also be used to create such an example:
#!/usr/bin/perl # Note the path to Perl may vary. # print "Content-type: text/html\n\n"; print "<html>\n<head><title>From CGI</title></head>\n"; print "<body>\n<h1>\n"; print "Wow! I was created by a CGI program!!"; print "</h1>\n </body>\n</html>";
Notice in the preceding example that it is very important to note the two line feeds in the first print statement. The blank line after the content-type line indicates the program is done sending headers and without the two returns the example will not work. The Web server itself will take care of sending any appropriate response codes and other headers.
| Note | The other newline characters \n are used primarily for formatting. If you view source on the resulting page generated by the CGI script, you will see many of the newlines are just used to make the markup halfway readable. |
If this example were typed and set to run on a Perl-capable Web server, it could be accessed directly by a user to print out the simple page shown in Figure 13-2. To see the program in action, go to http://www.htmlref.com/examples/chapter13/firstcgi.cgi.
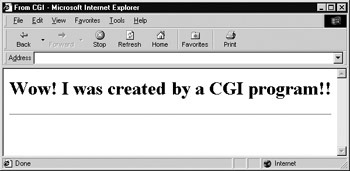
Figure 13-2: Output of simple CGI program
To create a document on the fly, you have to print a group of headers with special focus on the Content-type: header using the correct MIME type and then print out the tags and content that compose the page. This section covered returning information from the server, which is just half of the CGI equation. The following section discusses getting information to your server-side program.
CGI Input: Environment Variables
While the primary way to get information to a server-side program like CGI is to use a form, there is also useful information that can be garnered from the environment in which the transaction took place. An example of this information called environment variables includes the type of browser making the request, the time of day, the language being used, and so on. This information can be particularly useful for a server-side program to decide what kind of pages to prepare for a visitor. A list of the most common environment variables is provided in Table 13-2.
| Variable Name | Description |
|---|---|
| SERVER_NAME | The domain name or IP address of the Web server running the CGI program. |
| SERVER_SOFTWARE | Information about the Web server, typically the name and version number of the software; for example, Netscape-Commerce/1.12. |
| SERVER_PROTOCOL | The version number of the HTTP protocol being used in the request; for example, HTTP/1.1. |
| SERVER_PORT | The port on which the Web server is running, typically 80. |
| REQUEST_METHOD | The method by which the information is being passed, either in GET or POST . |
| CONTENT_TYPE | For queries that have attached information, because they use the POST or PUT method; contains the content type of the passed data in MIME format. |
| CONTENT_LENGTH | The length of any passed content ( POST or PUT ) as given by the client, typically as length in bytes. |
| PATH_INFO | Any extra path information passed in with the file request. This usually would be associated with the GET request. |
| SCRIPT_NAME | The relative path to the script that is running. |
| QUERY_STRING | Query information passed to the program. |
| DOCUMENT_ROOT | The document root of the Web server. |
| REMOTE_USER | If the server supports user authentication and the script is protected, this variable holds the user name that the user has authenticated. |
| AUTH_TYPE | This variable is set to the authentication method used to validate the user if the script being run is protected. |
| REMOTE_IDENT | If the Web server supports RFC 931 “based identification, this variable will be set to the remote user name retrieved from the server. This is rarely used. |
| REMOTE_HOST | The remote host name of the browser passing information to the server; for example, sun1.bigcompany.com. |
| REMOTE_ADDR | The IP address of the browser making the request. |
| HTTP_ACCEPT | A list of MIME types the browser can accept. Modern browsers may send ratings indicating the preferred type of content desired. |
| HTTP_ACCEPT_ENCODING | Indicates the forms of compression the browser can handle, if any. |
| HTTP_ACCEPT_LANGUAGE | Indicates the type of spoken language the browser is set to by default. |
| HTTP_USER_AGENT | A code indicating the type of browser making the request. |
| HTTP_REFERER | The URL of the linking document (the document that is linked to the CGI being run). If the user types in the address of the program directly, the HTTP_REFERER value will be unset. |
Figure 13-3 shows the results of a CGI program that prints out the environment information. Try to execute the program at http://www.htmlref.com/examples/chapter13/printenv.cgi to see if the results are different.
Figure 13-3: CGI environment variables example
The following is the Perl code for the result in Figure 13-3:
#!/usr/bin/perl &print_HTTP_header; &print_head; &print_body; &print_tail; # print the HTTP Content-type header sub print_HTTP_header { print "Content-type: text/html\n\n"; } #Print the start of the HTML file sub print_head { print <<END; <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en"> <head > <title> CGI Environment Variables </title> <meta http-equiv="content-type" content="text/html; charset=ISO-8859-1" /> </head > <body > <h1 align="center" >Environment Variables </h1> <hr /> END } #Loop through the environment variable #associative array and print out its values. sub print_body { foreach $variable (sort keys %ENV) { print " <b> $variable: </b> $ENV{$variable} <br /> \n"; } } #Print the close of the HTML file sub print_tail { print <<END; </body > </html > END } Notice that the code is written to make the printing of the appropriate headers, the start of the HTML file, the results, and the close of the file more straightforward. Fortunately, code libraries, which do much of the work of CGI, are commonly available.
CGI Input: Form Data
Forms are a good way to collect user input such as survey results or comments. They also can start database queries or launch programs. Creating forms was discussed in the previous chapter. For a quick refresher on form syntax, take a look at the following example:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en"> <head> <title> Meet and Greet </title> <meta http-equiv="content-type" content="text/html; charset=ISO-8859-1" /> </head> <body> <h1 align="center"> Welcome to CGI! </h1> <hr /> <form method="post" action="http://www.htmlref.com/cgi-bin/hello.pl"> <b> What's your name? </b> <input type="text" name="username" size="25" /> <input type="submit" value="Hi I am..." /> </form> </body> </html>
The previous example will greet the user by whatever name he or she types in. The example can be found at http://www.htmlref.com/examples/chapter13/postwelcome.html.
The <form > tag is the key to this example because it has an action to perform (as indicated by the action attribute when the form is submitted). The action is to launch a CGI program indicated by the URL value of the action attribute; in this case, www.htmlref.com/cgi-bin/hello.pl. The <form > tag has another attribute, method , which indicates how information will be passed to the receiving CGI program; in this case, post . Recall from the previous chapter that there are two basic methods to pass data in through a form: get and post . To see the preceding example in action using get instead of post , view http://www.htmlref.com/examples/chapter13/getwelcome.html. The get method appends information on the end of the submitting URL, so the URL accessed through getwelcome.html might be something like this:
http://www.htmlref.com/cgi-bin/hello.pl?username=Joe+Smith
The data sent will be encoded; the string might have all spaces turned into + signs, and special characters might be encoded as % nn hex character values. The various form element names will be sent to the CGI program as name/value pairs such as username=Joe separated by ampersands. For example, if the previous example had other fields in the form named age and sex , you might see a get query string like the following:
http://www.htmlref.com/cgi-bin/hello.pl?username=Joe+Smith& age=32&sex=male
Submitting data with the get method does have drawbacks. First, you are limited to the amount of data that can be submitted. A limit of either 1,024 or 2,048 bytes is commonly encountered with query strings in URLs. Also, because request strings from a get method are simply URLs, they are often open to easy manipulation by the curious or malicious user. Finally, they don't look terribly user-friendly.
However, the get method does have its advantages. First, it is easy to understand and experiment with. Second, it provides the possibility for canned queries because the value of fields can be placed in the URL itself. This allows the query to be linked to via a URL. It's also very important to note that because you are storing data in the URL, get queries can be bookmarked, unlike posted data.
In contrast to the data-limited get method is the post method, which sends the form data to the server as a separate data stream following the request. This data stream consists of many lines, such as username=Joe%20Smith , that are the various name value pairs created by the form entry made by the user. If you look at posted data, you'll observe it is encoded in pretty much the same manner as a get request. However, data sent using post can be much larger than what is allowed in a get request, although it is not possible to bookmark a post request. The common "Repost form data?" message from a browser is the result of not being able to easily save posted data.
Regardless of the method used to send data, once received by the server-side program, the information needs to be parsed for later processing. Given the simplicity of how form data is encoded, a skilled programmer easily could determine how to parse data and access the values. However, instead of doing that work ourselves , we might instead rely on a CGI library (like cgi-lib.pl). The following code is a simple example that we have been using to echo back the form data sent in from the user. Notice that the reading and splitting of the data submitted requires only the statement &ReadParse.
#! /usr/bin/perl require ("cgi-lib.pl"); &ReadParse; $name = $in{"username"}; print "Content-type: text/html\n\n"; print " <html><head><title> "; print "Hello from CGI </title></head><body> "; print " <h1> Hello $name! </h1> <br/> "; print " </body></html> "; The preceding examples might seem to suggest that writing CGI programs is trivial. This is true if data is only to be read in and written out. In fact, this part of CGI is so mechanical that page designers are discouraged from attempting to parse the data themselves . There are many scripting libraries available for Perl. These include cgic (http://www.boutell.com/cgic/) for ANSI C programs, cgi++ (http://www.webthing.com/cgiplusplus/) for C++, the CGI module (http://www.python.org/doc/lib/module-cgi.html) for Python, and CGI.pm (http://stein.cshl.org/WWW/software/CGI/cgi_docs.html) for Perl. These libraries, and others available on the Internet, make the reading of environment variables and parsing of encoded form data a simple process. However, you'll see later in the chapter that it is even easier in a server-side scripting language such as PHP.
The difficult part of CGI isn't the input and output of data; it's the logic of the code itself. Given that the CGI program can be written in nearly any language, Web programmers might wonder what language to use. Performance and ease of string handling are important criteria for selecting a language for CGI programming. Performance-wise, compiled CGI programs typically will have better performance than interpreted programs written in a scripting language such as Perl. However, it probably is easier to write a simple CGI program in a scripting language such as Perl and then use a form of compiled Perl or the mod_perl module to get most of the performance gains of compilation with the ease of a scripting language.
Some programming languages might have better interfaces to Web servers and HTTP than others. For example, Perl has a great number of CGI libraries and operating system facilities readily available. Because much of CGI is about reading and writing text data, ease of string handling also might be a big consideration in selecting the language. The bottom line is that the choice of scripting language mainly depends on the server the script must run on and the programmer's preference. It is even possible to use an old version of FORTRAN or some obscure language to write a CGI program, although it would be easier to pick a language that works well with the Web server and use it to access some other program. CGI lives up to its name as a gateway.
Table 13-3 lists the common languages for CGI coding based on the Web server's operating system. Notice that Perl is common to most of the platforms, due to its ease of use and long-standing use on the Web.
| Web Server Operating System | Common CGI Languages |
|---|---|
| UNIX | Perl, C, C++, Java, Shell script languages (csh, ksh, sh), Python |
| Windows | Visual Basic, C, C++, Perl, Python |
| Macintosh | AppleScript, Perl, C, C++, Python |
| Note | Writing CGI programs in a UNIX shell scripting language such as csh, ksh or sh can pose serious security risks and should be avoided. |
Don't rush around getting ready to code your own form handlers. Consider how many other people in the world need to access a database or e-mail a form. Given these common needs, it might be better to borrow or buy a canned CGI solution than to build a new one.
Buying or Borrowing CGI Programs
Most CGI programs are similar to one another. There are many shareware, freeware, and commercial packages available to do most of the common Web tasks . Matt's Script Archive (www.scriptarchive.com) and the CGI Resource Index (www.cgi-resources.com) are good places to start looking for these. There are many scripts for form parsing, bulletin boards , counters, and countless other things available free of charge on the Internet. There are also compiled commercial CGI programs made to perform a particular task. Site developers are urged to consider the cost of developing custom solutions versus buying canned solutions, particularly when time is an important consideration in building the site.
| < Day Day Up > |
EAN: 2147483647
Pages: 252