Just-in-Time Commitment
| A friend of ours is a commercial pilot from Innsbruck. He recently augmented his pilot's license with an instrument rating at a school in the United States. He told us that the focus of his instrument flying class was on decision making, because research indicated that the cause of most single-pilot plane accidents is faulty pilot decisions. Here is what he learned:
As we guide our product development process, we need to recognize that developing a product is all about learning, and the longer we defer decisions, the more we can learn. But we don't want to crash into a mountain, so the key is in timing. Lean development organizations make decisions Just-in-Time, and they start by deciding exactly what that means. Software is a unique product because it is by its very nature meant to be changed, so typically we can defer decisions for a good long time. Unfortunately, this feature of software encourages some to procrastinate on the front end of development. If we aren't creating focused increments of technical progress, we are probably not making progress at all. If we are not doing experiments and getting feedback, we probably aren't learning much, and in the end, the work of any software development process is to create knowledge that gets embedded in the software. Set-Based DesignTwo different approaches to learning have evolved in the software development world, both based on knowledge generation through iterative experiments. In the first case, the experiments are done by building a system which is change tolerant, so that as we learn we can easily fold the learnings into the system through what we call "refactoring." In the second case, the experiments are constructed as well-formed and thoroughly investigated options, so that at the last possible moment we can choose the option that gives the best overall solution to the puzzle. The second approach is called set-based design, and it is the appropriate approach for making high-impact, irreversible decisions. There are a lot of these kinds of decisions in hardware development, so set-based design is particularly suited for hardware and, quite often, hardware-oriented aspects of embedded software. There are fewer high-impact irreversible decisions in software development, but they are certainly not absent. User interface approaches can be difficult to change once users get used to them. A hosted service is well advised to think through its security and performance strategies before the first release. Single-release products with seasonal release dates, such as games and tax preparation software, make good candidates for an options-based approach to development. Set-based design is the preferred approach for making key architectural decisions that, once made, will be very expensive to reverse. How does set-based design work? Assume that some disaster befalls your company. You must make an immediate response and two things are clear: 1) There is a completely unmovable deadline, and 2) failure to meet it is not an option. What would you do? If you want to be absolutely certain of success, you commission three teams to develop the response: Team A is chartered to develop a very simple response that absolutely will be ready by the deadline. The response will be far from ideal, but at least it will be ready. Team B is chartered to develop a preferred solution that may be ready by the deadline if all goes well. Team C is chartered to develop the ideal solution, but the likelihood that they will make the deadline is slim. Team A develops its suboptimal solution, but the team members hope that Team B makes the deadline because they know Team B's solution is better. Team B works very hard to make the deadline while simultaneously cheering on Team A, because that's their backup, and hoping against hope that Team C comes through on time. Team C tries very hard to meet the deadline, but the team members are very glad that Teams A and B are backing them up. When the deadline arrives, there will be a solution, and it will be the best one possible at the time. Moreover, even if the deadline is moved up, a functional solution can be still available while if the deadline moves back, the optimal solution might be ready. If the process is ongoing, the company can start out using solution A, then as soon as it is ready, switch to solution B, then eventually move on to solution C. When it is absolutely essential to provide the best possible solution in the shortest possible time, set-based design makes a whole lot of sense. But when we apply set-based design to a development environment, it strikes many people as counterintuitive. The people who understand set-based development most readily live in environments that release products on a regular cadence with no tolerance for missing a deadline. Your daily newspaper is a good example; so are most magazines. Plays always open on opening night, news broadcasts happen on schedule every day, and seasonal clothing is always ready to ship when the season arrives. Product development in these environments takes the form of readying various options and then assembling the best combination just before the deadline. When schedule really matters, it is not managed as an independent variable, it is a constant that everyone understands and honors. So it should not be a surprise that Toyota has never missed a product delivery deadline. Nor should it be a surprise that Toyota uses set-based design. Set-based design is more than a method to meet schedules, it is a method to learn as much as possible in order to make the best decisions. So how would this work in software? In Figure 7.2 we see a nine-month schedule with specific high-impact decisions scheduled at synchronization points. Each of these decisions is scheduled for the last possible moment; any later would be too late. For each of these decisions, multiple options are fully developed. When the synchronization point arrives, the system is assembled and tested with each option. The option that gives the best overall system solution is chosen. Note that the best option for each subsystem is not necessarily the choice. The option giving the best overall solution is chosen. This is the reason that each option set must be fully developed for testing at the synchronization point. Figure 7.2. Product release schedule with key decisions scheduled at synchronization points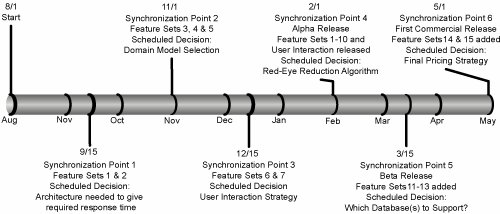 Example 1: Medical Device Interface DesignOne manager we spoke to uses a set-based approach to medical device interface design. His department is responsible for developing screen-based interfaces that technicians use to control medical devices. When a champion comes to him with a new product idea, he realizes that the champion has only a vague idea of what the interface really should do. So the manager assigns three or four teams to develop options during a six-week iteration. At the end of six weeks, the teams show their developments to the champion, who invariably likes some features from one option and other features from another option. The manager then assigns two teams to more fully develop two options over a second six-week iteration. At the end of that iteration, he finds that the champion can choose with certainty exactly which features he wants. "And at that point," the manager tells us, "the software is half done, and I know the champion will be completely happy with the product." Example 2: Red-Eye ReductionAfter a talk, someone who managed software for printers proposed a dilemma to Mary. He said that he had 12 weeks to develop software for a new color printer, and the deadline simply could not be moved. The marketing people told him that they could sell a very large number of additional printers if they had an automatic red-eye reduction capability. At the time, red-eye reduction was a solved problem as long as an operator pointed a red eye out to the computer, but having a computer determine if there were red eyes in the picture and fix them automatically was not quite a solved problem. The dilemma was this: There was a simple algorithm that the manager knew he could have ready on time, but he didn't think it was a very good algorithm. There was a far better algorithm, but he was not sure that it could be ready by the 12-week deadline. So what should he dotake a risk on the better algorithm, or take the safe route and do the simple one? "Quite obviously you should do both." Mary said. "But how am I going to get the resources?" he asked. "You said you could sell a very large number of additional printers if you can provide red-eye reduction," Mary answered, "And you're asking me how you can get the resources?" "You have a point," he said, "But how am I going to explain to my management that I'm doing two things when one will have to be thrown away?" "You tell them," Mary said. "Don't worry, I guarantee you that we will have red-eye reduction ready on time. And better than that, we will have a spectacular algorithm that might make the first release, but if it doesn't it will be ready for the next one." Example 3: Pluggable InterfacesSome decisions simply are not clear until the end of development. Maybe external interfaces are not clear, or in the case of embedded software, the hardware is not built yet. Often the exact role of various users has not been determined by the business, or technologies such as middleware or persistence layer have not been chosen. Some decisions might never be made. For example, a person might type on a keyboard for input in the initial release, but voice recognition will be substituted for some users later on. One solution in these cases is to create pluggable interfaces selected by build-time switches. Mock objects are useful as placeholders for decisions that are being deferred or for options that will be selected later. Embedded software should be developed to run in two environments: a development environment with a simulator and the real environment. Usually the logging and actions upon errors will be different in each environment and will be selected by a flag. Pluggable interfaces to databases, middleware, and user interfaces are common, but building multiple cases of user roles is less common. In one class a developer described her strategy to determine file size: "It was unclear if the file had to be large or small, so I built both cases so I could decide at the last minute which one to use," she said. "Surely you didn't waste time building two when you knew you would have to throw one away?" someone asked. "Surely I did," she replied. "It didn't take much extra effort, and when the time came to deploy the software, it was ready to go." Why Isn't This Waste?What we think of as "waste" is almost entirely dependent on how we frame the problem we are trying to solve. Remember the emergency response Teams A, B, and C. We have been asked: "Why not put people from Team A onto Team B and increase the chances of getting the better solution earlier?" Recall, however, that this was an emergency and failure was not an option. If we had said this was a matter of life and death and failure would mean someone dies, would Team A still seem like a waste? In the examples above, missing market timing would have created far more wasteincluding time on the part of all of the rest of the team membersthan the relatively small incremental effort of creating technical options. Developing technical options to be sure we make optimal decisions results in higher product qualityreducing support and warranty costs many times over the life of a product. If set-based design seems like waste, our frame of reference is probably limited to the immediate development issues rather than the big picture. RefactoringAs we noted in Chapter 2, the point of most software development is to create a change-tolerant code base which allows us to adapt to the world as it changes. As we will see in Chapter 8, we do this by using an iterative process, along with the disciplines that support change tolerance: automated testing, small batches, rapid feedback, and so on. There are two dangers with this strategy. First, we may make some key irreversible decision incorrectly if we make them too early. As we have seen, this danger should be identified and dealt with using set-based design. The second danger of incremental development is that as we make changes, we add complexity, and the code base rapidly becomes unmanageable. This is not a small danger; it is highly probable unless we aggressively mitigate the risk. Refactoring is the fundamental mechanism for mitigating the risk and minimizing the cost of complexity in a code base. Refactoring enables developers to wait to add features until they are needed and then add them just as easily as if they had put them in earlier. The rationale behind refactoring is this:
Probably the biggest mistake we can make is to regard refactoring as a failure to "Do It Right the First Time." In fact, refactoring is the fundamental enabler of limiting code complexity, increasing the change tolerance, value, and longevity of the code. Refactoring is like exercise; it is necessary to sustain healthy code. Even the most time-pressed people in the world, executives and presidents, build in time to exercise to maintain their capacity to effectively respond to their next challenge. Similarly, even the most time-pressed developers in the world build in time for refactoring to maintain the capacity of the code base to accommodate change. Refactoring requires an aggressive approach to automated testing, similar to the one used at Rally, which we described at the beginning of this chapter. As changes are being made to reduce the complexity of the code base, developers must have the tools in place to be certain that they do not introduce any unintended consequences. They need a test harness that catches any defects inadvertently introduced into the code base as its design is being simplified. They also need to use continuous integration and stop-the-line the minute a defect is detected. The time and effort invested in automated testing and continuous improvement of the code base and associated tests is time spent eliminating waste and reducing complexity. The lean strategies of eliminating waste and reducing complexity are the best known way to add new capability at the lowest possible cost. Refactoring is like advertising: it doesn't cost, it pays. Legacy SystemsThere are two kinds of softwarechange tolerant software and legacy software. Some software systems are relatively easy to adapt to business and technology changes, and some software systems are difficult to change. These difficult-to-change systems have been labeled "legacy" systems in the software development world. Change tolerant software is characterized by limited dependencies and a comprehensive test harness that flags unintended consequences of change. So we can define legacy systems as systems that are not protected with a suite of tests. A corollary to this is that you are building legacy code every time you build software without associated tests. Legacy systems are everywhere, and thus a large portion of software development is aimed at legacy code. Brian Marick identifies three approaches to dealing with legacy systems:[13]
Rewriting legacy software is an attractive approach for managers who dream of walking into their office one day and finding that all of their problems have disappeared as if by magic, and the computer now does all of the things that they could never do with the former system. The problem is, this approach has a dismal track record. Attempting to copy obscure logic and convert a massive databasewhich is probably corruptedis very risky. Furthermore, as we have seen, perhaps two thirds of the features and functions in the legacy system are not used and not needed. Yet too many legacy conversions attempt to import the very complexity that caused the legacy system to resist change in the first place. Refactoring legacy software is often a better approach. As we noted above, refactoring requires a test harness, but legacy code by definition does not have one. So the first step is to break dependencies and then place tests around independent sections of code to be able to refactor them. It is impractical, for the most part, to add unit tests to legacy code, so the idea here is to create acceptance tests (also called story tests) that describe by example the business behavior expected of the code. For help here we refer you to Working Effective with Legacy Code,[14] which is pretty much the bible on refactoring legacy code.
The third approach to dealing with legacy code is to strangle it. Martin Fowler[15] uses the metaphor of a strangler vine that grows up around a fig tree, taking on its shape and eventually strangling the tree. Ultimately the tree withers away, and only the vine is left. To strangle legacy code, you add strangler codewith automated testsevery time you have to touch a part of the legacy code. You intercept whatever activity you need to change and send it to a new piece of code that replaces the old code. While you are at it you may have to capture some assets and put them into a new database. Gradually you build the new code and database until you find that the parts of the old system that are actually used have all been replaced. At the beginning of this chapter, we saw how Rally used the strangler approach to replace its UI platform over fourteen months.
ExampleAt Agile 2005, Gerard Meszaros and Ralph Bohnet[16] of ClearStream Consulting in Calgary reported on their successful port of a complex billing system of about 140,000 lines of Smalltalk code, with about 1,000 classes and over a dozen algorithms for charge calculations. Their approach was to create a set of regression tests for the existing system and then port the code until the new system produced the same results as the existing system. The regression tests took the form of tables in Excel spreadsheets. These tables were run against the legacy system and the results it produced were considered the "correct" answer. Then the developers went to the part of the legacy system that produced the results and ported the code to Java. (It was pretty good code, since it was Smalltalk). As the team developed the new system, they used Fitnesse to run the tables against the developing code every day, until the results produced by the legacy system were duplicated. At that point the feature was considered complete. Meszaros and Bohnet report that they ported the system on schedule in six months, with only 20 open defects throughout a month-long user acceptance test. Most importantly, Ralph reports that perhaps 55 percent of the legacy code was left behind because they found that it was not being used.
|
EAN: 2147483647
Pages: 89