Generic Parsing
|
Handling repetitive documents with wrapper classes solves our most common XML problems in .NET. However, certain classes of applications—for example, XML programming tools such as XSD.exe or the serializer—require us to pick apart an XML document at run time, where we can never have the slightest idea in advance what we will encounter. Therefore, it is necessary to have a generic parser to which we can feed an unknown XML document and discover the document’s contents dynamically at run time.
We still need generic parsing capability.
The .NET Framework provides two separate implementations of an XML parser. The first provides an implementation of the W3C standard called DOM, the Document Object Model. The DOM parser reads an entire document into memory and holds it in a tree-based structure, representing every part of the document (elements, attributes, text, and so on) as a node on the tree. You can add and delete nodes, read and modify their values, and save the entire document. It’s a very convenient way to look at the world provided the file isn’t too large, in which case keeping the entire thing in memory at once can be cumbersome.
Microsoft provides a .NET XML parser that supports DOM, the W3C Document Object Model.
I’ve written a sample program, shown in Figure 7-6, that opens an XML document using Microsoft’s DOM parser and displays it in a tree control. When the user clicks Open, a dialog box pops up and the user selects a file name. The program creates an object of the class System.Xml.XmlDocument and calls its Load method, thereby reading in the specified file. Each node in the document is represented in the form of an object of class System.Xml.XmlNode, containing such properties as Name, Value, and ChildNodes. The ChildNodes property is a potentially empty collection of all the nodes in the next level down in the tree. My enumeration function, shown in Listing 7-13, loops through this collection, reading the names and values and types of the nodes and putting them on the tree control for you to look at. It then calls itself recursively on each child node until it reaches the bottom.
Here’s a sample program demonstrating the .NET version of DOM.
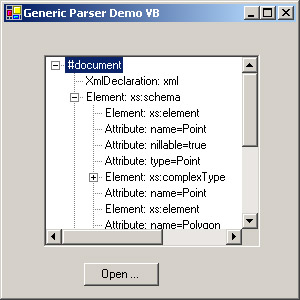
Figure 7-6: Sample program demonstrating DOM parser.
Listing 7-13: Enumeration code using DOM parser.
Private Sub EnumerateNodes(ByVal ThisNode As Xml.XmlNode, _ ByVal TreeNode As System.Windows.Forms.TreeNode) ’ Step through each child in the collection of the supplied XML ’ document node Dim child As Xml.XmlNode For Each child In ThisNode.ChildNodes ’ Create new node and add it to tree Dim NewTreeNode As New Windows.Forms.TreeNode() TreeNode.Nodes.Add(NewTreeNode) ’ If it’s a text element, then put its value there If child.NodeType = Xml.XmlNodeType.Text Or _ child.NodeType = Xml.XmlNodeType.Comment Then NewTreeNode.Text = child.NodeType.ToString + ": " + _ child.Value ’ Otherwise put its name there Else NewTreeNode.Text = child.NodeType.ToString + ": " + _ child.Name End If ’ Enumeration of attributes omitted for space ’ If the child node itself has children, then enumerate ’ them as well If (child.HasChildNodes) Then Call EnumerateNodes(child, NewTreeNode) End If Next child End Sub
The main drawback to DOM is that it requires you to hold the entire XML document in memory, which can be a problem if the document is large. Sometimes you are reading a large document, only a small portion of which you care about or are converting into something different anyway. In this case, you might rather use the second implementation of an XML parser, the class System.Xml.XmlTextReader or its validating relative, System.Xml.XmlValidatingReader. These objects provide forward-only, read-only, non-cached access to an XML document. You can also perform output using their counterpart, System.Xml.XmlTextWriter. This might be a good choice if you have a collection of non-XML data, say, from a database search, that you want to convert into XML. Rather than make a copy in DOM, you’d use this class to do direct output. All of these classes hold only a small portion of the XML document in memory at any one time, reading from or writing to disk on demand. These are lower levels of abstraction and are thus much less used. But again, as with so many things in this chapter, these options are there when you need them.
.NET also supports parsing options that don’t require keeping an entire document in memory.
|
EAN: 2147483647
Pages: 110