The IO Stack
| < Day Day Up > |
The I/O StackData is usually structured in a layered fashion, starting with bits, then bytes, blocks, volumes, and finally files. It is encoded on a media as bits a series of 1s and 0s. If the drive only placed a stream of bits on a media, it would be very difficult to find anything on the media. This layered storage architecture is known as the I/O stack (Figure 2-1). The I/O stack is the logical representation of the hardware and software that data must pass through when it is moving back and forth to storage. Figure 2-1. The I/O stack
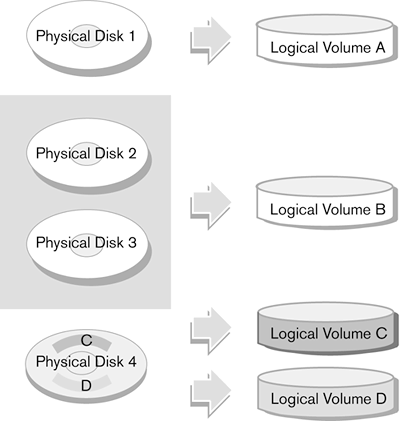
The drive itself creates the first level of structure by organizing data as blocks. A block consists of some number of bytes held at a specific location on the disk. Blocks are further organized into volumes. Volumes (Figure 2-2) are logical, mountable portions of physical storage. A volume may be an entire disk or tape, a portion of a disk, or an aggregated collection of disks or tapes. A volume can be thought of as a virtual set of blocks controlled by software called a volume manager. The operating system and applications access data as blocks, but how those blocks are addressed is up to the volume manager. Figure 2-2. Volumes
File systems then organize data on a volume as files or objects. The manner in which blocks are organized into directories and files is unique to each file system. The file system used by Microsoft Windows NT/2000/XP, for example, is called NTFS (for NT File System) and is different from and incompatible with the system used by Linux. Applications access the file system to create and access files and are responsible for their own files' internal structure. File systems add a lot of overhead to I/O operations. This doesn't affect typical productivity applications, such as word processors. A few extra milliseconds opening or writing a file are hardly noticed by the end-user. The overhead is significant, however, for high-performance applications such as databases. Relational Database Management Systems (RDBMS) often bypass the file system and access the volume directly. There is a serious movement to dispense with the traditional file system in favor of an object-oriented file system (OOFS). Despite the name, data is not organized into files at all. Instead, the OOFS creates and manages data as objects. Objects marry data with application or component behavior. There are advantages to this approach, but it has been feasible only in very specialized circumstances. The theoretical underpinnings of an OOFS were laid down in the early 1970s, though it has proved to be technically difficult to deploy with reasonable performance. Block I/OWhen a protocol accesses data on a disk as blocks, it is referred to as block I/O. Certain types of applications prefer to access data directly as blocks. This is especially true of high-performance system applications such as databases. They maintain their performance levels by defining their own structure separate from the operating system's file system. This allows them to use specialized techniques to search through data quickly and write data efficiently. Backup and retrieval applications also prefer to use block I/O. This allows them to restore the original structure of the data without really knowing what it was. File I/OMost end-user applications need to have data organized in an easy-to-understand format. The most common form is the file. The operating system imposes the file structure on the data through its file system. Accessing data through a file system is called file I/O. It is easier for an application to use the existing mechanisms in a file system for most I/O than to deal with data at a block level. The general structure of a file is defined by the file system and is unique to it. Applications define the internal structure of the file Microsoft Word format documents, for example. Network attached storage and file servers allow for shared file access over the network. RAIDRAID (Redundant Array of Independent Disks) is a schema for using groups of disks to increase performance, protect data, or both. RAID comes in different RAID levels that define its functions (Table 2-2). In all cases, RAID copies data blocks to multiple disks to accomplish its goals. RAID can be accomplished in software, in hardware, or both.
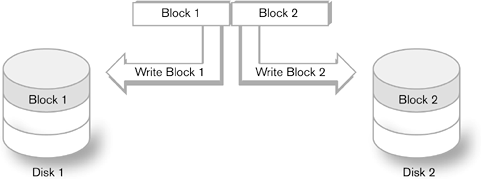
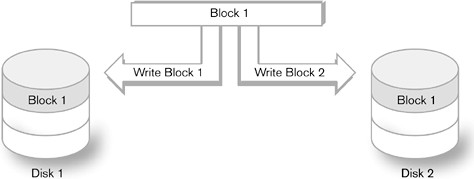
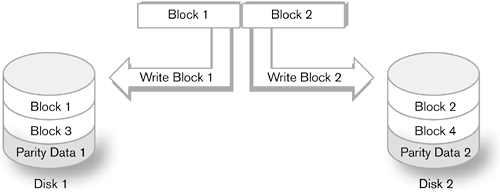
RAID functions are broadly defined as striping and mirroring. Striping occurs when different data is written to or read from multiple disks. This allows for the creation of a disk virtual space larger than an individual physical drive would allow. It also increases performance by spreading I/Os across multiple drives at once. Striping aggregates individual disk spaces into a much larger one while increasing performance. Mirroring is the copying of the same data block to different disks to have a copy of the block available in the event of a failure of a disk. It is sometimes referred to as shadowing. RAID levels are referred to by the term RAID plus the level. For example, RAID level 0 (striping) is described as RAID 0. RAID 0, 1, and 5 are the most common forms of RAID. RAID 0 (Figure 2-3) uses only striping to achieve a larger volume space and better overall performance. RAID 1 (Figure 2-4) uses mirroring to protect data by placing redundant copies of data on two or more disks. RAID 5 (Figure 2-5) uses striping to achieve a larger volume space but employs parity to ensure that data can be re-created quickly if there is loss or damage. RAID 5 spreads the parity data through the disk set rather than to a separate disk. By spreading parity data over many disks, RAID 5 guards against performance degradation when a disk is lost and data must be recovered. Its write performance is less than that of RAID 0 or 1 and is almost always supported with hardware in a RAID controller. RAID 10 provides for high volume space and protection. It is similar to proprietary copy schemes within large disk arrays, so it is less common than RAID 5. Figure 2-3. RAID 0
Figure 2-4. RAID 1
Figure 2-5. RAID 5
There are other RAID levels, including RAID 2, 3, and 4. These are much less common and are not supported by all products. RAID ControllersAlthough RAID can be performed in software, which is common in small systems with internal disks, the predominant method of providing RAID services for external systems is through the use of a RAID controller. This is a specialized version of a disk array controller that marries the disk interface with the RAID software. Often referred to as hardware-assisted RAID or hardware RAID, RAID controllers perform RAID functions very quickly and are the only reasonable way to perform RAID 5. RAID controllers are available as separate add-on devices or are built into disk arrays. |

| < Day Day Up > |
EAN: 2147483647
Pages: 122