Hack22.Deconstruct Web Server Logfiles
Hack 22. Deconstruct Web Server Logfiles
The history of web site measurement is, for the most part, the history of web server logfiles. Understanding the data logfiles provide and their limitations will help you better plan for their use. Web measurement got its start over 10 years ago with simple log analysis tools. These early tools did little more than scan the logfiles produced by web servers to count hits and visits, report on server errors and page load times, and process other data pertinent to early site administrators. 2.10.1. Anatomy of a Web Server LogfileGenerally speaking, each entry in the logfile will contain the IP address of the requesting client, the requested URL, the number of bytes transferred to the client, the date/time of the request, the URL from the which the request was made (also called the referring URL [Hack #1]), and much more. The log will not only contain each explicitly requested page (commonly a file with an extension of HTM, HTML, ASP, or JSP), but also each image (e.g., GIF and JPG), JavaScript file (JS), and other objects needed to complete the loading of the page. Not surprisingly, logfiles can get excessively large [Hack #19]. Using the following sample line from the author's web server logfile, let's step through the fields captured in the combined log format (see below for more formats). 216.219.177.29 - elvis [15/May/2000:23:03:36 -0800] "GET /index.htm HTTP/1. 0" 200 956 "http://www.webanalyticsdemystified.com/index.asp" "Mozilla/2.0 (compatible; MSIE4.0; SK; Windows 98)" Each element tells us something about the visitor or application making the request.
For more information on the details of web server logfiles, see the W3C document on logging control (www.w3.org/Daemon/User/Config/Logging.html) or Chapter 21 of HTTP: The Definitive Guide (O'Reilly). Requests from clients are interspersed throughout the logfile in the order they are received. The job of the logfile analysis tool is to parse up this large file to stitch together the individual visits from their respective clients. This can be a difficult problem if the only means of identifying the client is the IP address, as IP addresses are apt to change for a given client (especially when the IP address is dynamically assigned by a corporate DHCP server or commercial ISP service, such as AOL [Hack #78]). Fortunately, vastly superior visitor tracking methods are available to site designers, including session parameters [Hack #17] and cookies [Hack #15]. Use of a session parameter or cookie to identify visitors will dramatically improve the accuracy of your analysis results. 2.10.2. Types of Web Server LogfilesLogfiles also come in a variety of formats and types (Table 2-2). While industry standards exist for web servers, there are many other types of servers that can use other logging formats. Streaming media servers are one example of this, dedicated to serving media-only files and using a unique, often proprietary logging format that often requires a special processing engine to prepare for analysis.
2.10.3. The (Occasional) Need for TranslationContent management servers, commerce servers, portal servers, and other "dynamic" application servers also produce special logfiles. In these instances the files themselves are usually easily parsed by a logfile analysis tool, but the resulting reports may contain unintelligible code values in place of the actual page names, document names, product names, or other elements. To solve this problem, some analysis tools provide "look up" capabilities into the underlying database used by the application server to translate the code values into names or titles that are commonly understood. Figure 2-3 illustrates the SKUs before translation. Figure 2-3. Untranslated product SKUs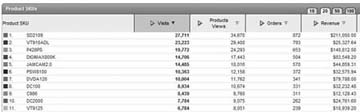 Figure 2-4 illustrates the SKUs after translation. If you are using an application server, such as BEA WebLogic, BroadVision, or Microsoft SharePoint, and client-side data tagging is not a viable data collection technique, make sure your web analysis tool can perform the required database lookups for your reports to be usable. Figure 2-4. Translated product SKUs When all is said and done, web server logfiles remain among the most popular and widely deployed web measurement data sources and will likely continue to be popular for years to come. While there has been a noticeable trend in the last three years towards the use of client-side page tags [Hack #28], many businesses now realize that the decision is not necessarily black and white, and that both sources of data have their intrinsic value. Jeff Seacrist and Eric T. Peterson |
EAN: 2147483647
Pages: 157