Groundwork
| [ LiB ] |
Groundwork
The first thing I want to do is lay the groundwork for the entity classes, which are the classes that represent physical objects within the game, such as players, items, and enemies. Within the game, all these entities will have names and unique ID numbers that identify the entities. The ID is important, because it is used to reference entities throughout the game. Instead of having a huge mess of pointers all over the place, you'll track entity IDs instead. This way, you can easily tell the game, "Hey, I want to access item number 403."
Within this chapter, all the code that I create for SimpleMUD is placed within the Demos\Chapter08\Demo08-01\SimpleMUD directory on the CD. Since I'm building the entire MUD incrementally throughout the next few chapters, I don't want you to look at the full codebase , so I've separated out just the parts that are needed for this chapter. At the end of the chapter, I show you a demo that gets what I've coded up and running for you.
Table 8.1 shows a listing of all the files introduced within this chapter and their purpose.
Table . Chapter 8 Files
| File | Purpose |
|---|---|
| Attributes.h | Stores all the enumerations needed, as well as the Attributes class |
| DatabasePointer.h/.cpp | Special pointers used to access databases |
| Entity.h | Stores the Entity class |
| EntityDatabase.h | Stores both the map- and vector-based database classes |
| Game.h/.cpp | The connection handler that handles game commands from players |
| Item.h | The class that represents items |
| ItemDatabase.h/.cpp | The database that stores items |
| Logon.h/.cpp | The connection handler that handles players trying to log on |
| Player.h/.cpp | The class that represents players |
| PlayerDatabase.h/.cpp | The database that stores players |
| SimpleMUDLogs.h/.cpp | The files that hold the MUD logging classes |
| Train.h/.cpp | The connection handler that handles players editing their stats |
Entities
As I mentioned before, entities in the game are composed of two things: their names and their ID numbers. I could create separate player, item, and monster classes, and give each of these classes those variables individually, but that's unorganized and prone to error.
I prefer to create classes that minimize the amount of coding you need to do. Using this philosophy, I've decided to create an Entity class to take care of this responsibility. This class is located in the Entity.h file. Here's a listing of the class's data and function declarations:
typedef unsigned int entityid; class Entity { public: inline Entity(); // constructor inline string& Name(); // name reference inline entityid& ID(); // ID reference inline string CompName(); // name in lowercase bool FullMatch( const string& p_name ); // full match bool Match( const string& p_name ) ; // partial match protected: string m_name; entityid m_id; }; Look at the data first. The name is a simple std::string (although I removed the std:: from the code just so it looks better), and IDs are just unsigned integers. (The entityid typedef is at the top of the code segment.) I like to use typedefs because they make your code cleaner. In the game, 0 is considered the invalid value, and every other value is valid, giving you about 4 billion valid IDs for each entity type. It is assumed that each entity type is independent of all the rest, so item 1 is a different entity than enemy 1 or player 1. Theoretically, memory considerations aside, SimpleMUD supports up to 4 billion items, 4 billion players, and 4 billion enemies.
Accessors
There are several functions included along with the Entity class. Two of the functions, Name and ID , are just simple accessor functions that return a reference to the variable they point to:
inline entityid& ID() { return m_id; } inline string& Name() { return m_name; } Because these variables return references, you can modify the variables through the functions, like this:
n.Name() = "John";
The constructor (which I do not show) simply initializes the name to "UNDEFINED", and the ID to 0, indicating that the object hasn't been constructed .
Full Matching
The other functions perform useful tasks on the class. For example, the CompName function returns the name of the string in lowercase form (using the BasicLib::LowerCase function from Chapter 4). This is mainly used for name comparisons. The fact that string s don't recognize "ABC" as being equal to "abc" can be annoying. Imagine being in the game and wanting to refer to an inconsiderate person named "JoHn". If you use a plain string comparison, the computer won't recognize who you're talking to unless you exactly match the case of each letter of the string. In other words, the computer will think that "john" is a different player than "JoHn." The CompName function solves this problem by converting both names into lowercase, when making comparisons.
There are two ways of determining if two names match. The first method, called full matching, only returns a positive match if the names are identical (ignoring case as I just mentioned). This functionality is stored within the MatchFull function:
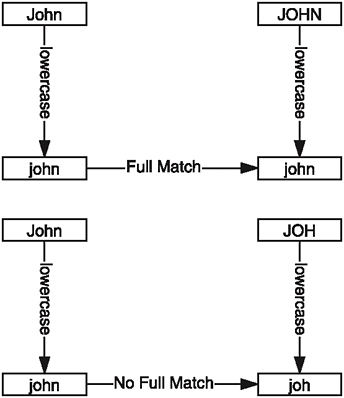
inline bool FullMatch( const string& p_str ) { return CompName() == LowerCase( p_str ); } Figure 8.1 shows two examples of full matching.
Figure 8.1. The full-matching function determines that one name matches and the other doesn't.
Partial Matching
The other method is called partial matching, and it returns a positive match if the search string matches the beginning of an entity's name.
For example, in a game in which partial matching isn't available, if a guy has a really long name, such as "ReallySuperAwesomeDude," whenever you want to refer to him, you'd have to type his full name. With partial matching, however, you can type "reall" or "rea" or any other partial string that matches the front of the entity's name, and the computer returns a match. The partial matching capability is found within the Match function.
Furthermore, after you've played a lot of MUDs, you'll find that the ability to partially match any word within a string is useful. For example, when you see a "Jeweled Sword" sitting in a room, the word "Jeweled" is eye candy , and your mind interprets that simply as a "sword." So you quickly type "get sword" without thinking about it. The partial matching function accommodates your greed and recognizes "get sword" as "Jeweled Sword" by performing partial matching on any word within a string.
Here's the function:
inline bool Match( const string& p_str ) const { if( p_str.size() == 0 ) return true; This first segment of code returns true if the size of the search string is 0. The reason for this is convenience; many times, there's just one enemy or one item in a room, and you can just type attack or get , and the partial matching algorithm will match on that item (or if there are more, it will match on the first one in the room). It's a convenience issue.
string name = CompName(); string search = BasicLib::LowerCase( p_str ); size_t pos = name.find( search ); while( pos != string::npos ) { if( pos == 0 m_name[pos-1] == ' ' ) return true; pos = name.find( search, pos + 1 ); } return false; } The previous code segment performs the partial matching. It first records the lowercased versions of the name and the search string (because they are used more than once).
Then the code performs a search on the name, and records the position into pos . If no match was found, the find function returns std::string::npos , which is a value representing the "invalid" string index. If that happens, there was obviously no partial match, so the function skips the loop, and false is returned.
If the position isn't npos , however, the body of the loop is executed. If pos is 0, that means that a match was found at the beginning of the name. For example, the string "rus" would return 0 when searched for within "rusty stake". The function would then return true , because the beginning of the string matched.
The partial matching function also checks to see if the character before pos is a space. This would happen if you searched for "sta" inside "rusty stake". The find function would return 6 (the index of the substring), and because the previous character is a space, true is returned.
So why is there a loop in the function? Imagine for a moment that you're searching for "st" within "rusty stake". Use Figure 8.2 as a guide for this example.
Figure 8.2. A loop is needed when the partial matching function searches for partial matches within a name.
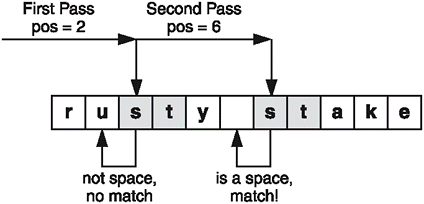
The first match for "st" is in the middle of "rusty", and that obviously doesn't count as a valid partial match. But you haven't searched the entire string yet, so you need to keep looking. Therefore, the find function is called again, this time starting at pos + 1 . Now the function finds another match for "st", this time at position 6. Because this is the beginning of a word, the function matches, and true is returned. The function loops through the entire string looking for any partial match. If no matches are found, when find reaches the end, it returns std::string::npos , the loop terminates, and false is returned.
Entity Function Listing
Table 8.2 shows a listing of all the functions within the Entity class.
Table 8.2. Entity Functions
| Function | Purpose |
|---|---|
| Entity() | Constructs the entity with "invalid" values |
| string Name() | Returns the name of the object |
| string CompName() | Returns a lowercase version of the name, used for comparisons |
| bool Match( string str ) | Determines if str partially matches the name of the entity |
| bool MatchFull( string str ) | Determines if str fully matches the name of the entity |
| entityid& ID() | Returns a reference to the entity's ID |
Entity Functors
Throughout the game, you're going to need to perform searches on groupings of entities, using full or partial matching. Obviously, you can't rely on your grouping classes such as the EntityDatabase , or any STL container to perform searching for you. STL relies on algorithms for searching, so I'll do the same.
STL searching algorithms typically rely on the operator== of a datatype for comparisons, but this is a problem for Entity 's, since there are two ways to compare entities with strings. So that's not going to work. Luckily for us, STL searching algorithms also have some backups that allow you to use functors to check if an object meets a specific criterion.
A functor is somewhat like a function pointer in the guise of a class/struct. The advantages this method has over function pointers are numerous . The most useful benefit is that a functor is allowed to have variables that represent its state. It's true that functions can have static local variables, but everything that calls that function will use the same variables. Using classes allows you to have many different functors in various states. There are other benefits as well, but I won't go over them; it's time to move on.
Functors are usually simple in nature and always overload an operator() . That's a weird operator to overload, but just bear with me for a moment.
NOTE
Functors are really nothing more than the C++ equivalent to function pointersclasses that act like functions. The examples I use here should be pretty simple to under stand, but if they still confuse you, there are many great books on STL that can help (such as The C++ Standard Library, a Tutorial and Reference , by N. Josuttis). I'll try to do my best, though!
I'm going to show you the basic layout of my matchentityfull functor, without function bodies:
struct matchentityfull { string m_str; matchentityfull( const string& p_str ); bool operator() ( const Entity& p_entity ); bool operator() ( Entity* p_entity ); }; You should note that the functor contains a string that you will be searching for within entities. The constructor takes a constant reference to a string, which will copy that into the m_str variable. This means that a string matching functor keeps track of the string that you are searching for. Before I show you the functions, let me show you a simple example of how this functor works:
matchentityfull matcher( "john" ); // functor that searches for "john" Entity a; Entity* b; // assume that 'a' and 'b' are initialized somewhere before the next line: bool t = matcher( a ); // see if 'a' matches "john" t = matcher( b ); // see if 'b' matches "john"
So you can see that this class simply performs a full entity-name match on Entity 's and Entity pointers.
Here's the code for the constructor:
matchentityfull( const string& p_str ) : m_str( p_str ) { /* do nothing */ } All the constructor does is record the string and keep track of it for future use. Note that I use the initializer-list syntax to construct the string, and do nothing within the function body.
Initializing variables in this manner is faster, as described in Appendix C, "C++ Primer," which is on the CD.
Here's the code for the two other functions:
bool operator() ( const Entity& p_entity ) { return p_entity.MatchFull( m_str ); } bool operator() ( Entity* p_entity ) { return p_entity != 0 && p_entity->MatchFull( m_str ); } The first version just calls the Entity::MatchFull function and returns the result. The pointer version first checks to make sure the pointer is nonzero and then calls the matching function. This way, if a NULL pointer is ever passed in, it always returns false . Otherwise, trying to dereference a NULL pointer may end up crashing it.
There is another functor, called matchentity , which is almost identical to matchentityfull ; the only difference is that it calls the Entity::Match function instead of Entity::MatchFull , so there's no need to paste the code here.
So, now that you know what functors are, and what they can do, let me show you a more complicated way to use them. Say, for example, you have a vector of entities, and another vector of entity pointers, and you'd like to search them for a name.
vector<Entity> evec; vector<Entity*> epvec; // pretend we fill up both vectors somewhere before this line: vector<Entity>::iterator itr1 = find_if( evec.begin(), evec.end(), matchentityfull( "john" ) ); vector<Entity*>::iterator itr2 = find_if( epvec.begin(), epvec.end(), matchentity( "john" ) );
See Appendix C on the CD for a short intro to STL if you're not familiar with its inner workings. Essentially , the previous code segment automatically searches a vector of Entity s for the first full match on the name "john", and searches a vector of Entity pointers for the first partial match of the name "john". The cool thing is that you can use this algorithm on any STL container that supports forward iterators. You'll see that the EntityDatabase class I show you next works quite well with STL algorithms.
For future reference, both of these functors are modeled around the concept of predicate functors, which are functors that evaluate a piece of data and return a Boolean, determining if the data satisfies a criterion. In this case, matchentity returns true if a player partially matches a string, and matchentityfull does so with full matches.
Entity Database Classes
Now you need a class to manage all the entities while they are in the game. In larger MUDs and in the bad old days, memory was not cheap, and it was hard to come by. But nowadays you can get memory for almost nothing, so I'm not going to spend any time in the SimpleMUD concentrating on memory optimization.
The game has two kinds of databases: map-based, and vector-based. If you know much about data structures, you know that STL maps have an O(log n) access complexity, which means that the map performs log n comparisons when searching for an item in a database of size n . A database of 255 items would need at most 8 comparisons to find any item, and a database of 65,535 items would require at most 16 comparisons.
Although this seems like a great database to use for everything, it's not optimal for some cases. There will be times when 16 comparisons are too long, so a database with faster access is required. That's where the vector comes in: an STL vector is basically just an array, and because of that, it has O(1) complexity. Accessing any given index with the STL vector takes just one calculation.
For the SimpleMUD, the entity databases will simply be static classes that enclose either std::map 's or std::vector 's, called EntityDatabase and EntityDatabaseVector . The base classes will be stored in the file EntityDatabase.h.
Because the classes are static, you should be able to access a single database within the game globally, without worrying about instantiating it. I'm sure people have told you before that globals are bad, and they're right; but honestly, for database-type stuff, globals really aren't that bad. How many different user /item/enemy databases do you need in a single game? I'm comfortable with having just one.
Map-Based Database
As I mentioned previously, the map-based database simply wraps around an std::map .
Class Definition and Data
First of all, every entity database is a template class. It is assumed that you are going to be storing Entity objects within the database, but each database should store only one type of entity. Therefore, runtime polymorphism (virtual inheritance) is inappropriate to use in this case, and compile-time polymorphism (a fancy term describing templates) will be used instead:
template< class datatype > class EntityDatabase { protected: static std::map<entityid, datatype> m_map; }; I've stripped out all the functions and the iterator class, which I will get to in a bit. For now, all you need to know is that each entity database stores a specific datatype by ID within an std::map . I prefer maps because they are easy to iterate through, and offer relatively quick search times. In an ideal world, if you had completely contiguous IDs for an entity type, you might prefer to store them in a std::vector , but I find maps easier to use. Maps are helpful in case you forget to assign a specific ID to any entity, and they prevent your MUD from unexpectedly crashing when you try accessing an entity that doesn't exist.
Iterator Inner Class
As I explain in Appendix C, which is on the CD, std::map s are awkward to iterate through when compared to the other container iterator types. This is because they don't actually store a single type of data within them, but rather a pair of data. So whenever you access an iterator into a map, the iterator doesn't return a single piece of data, but rather an std::pair structure that holds both the key and the data. This make things a little ugly to use, however. If you make the map-based database return iterators pointing directly into the std::map<entityid, datatype> , you must always use the iterators like this:
// this code assumes you have an EntityDatabase that stores players named // PlayerDatabase PlayerDatabase::iterator itr = PlayerDatabase::begin(); // now access the player that the iterator points to: itr->second.Name() = "Ron";
You'll need to constantly use the second variable of the iterator, which gets plain annoying; wouldn't you rather just code like this:
itr->Name() = "Ron";
With the EntityDatabase class, I've created an inner iterator class, which inherits from std::map::iterator , and redefines the operator* and operator-> functions, so that they return a reference to the second value directly. The code isn't that complex, so I won't be presenting it here. This is what is known as an iterator proxy class.
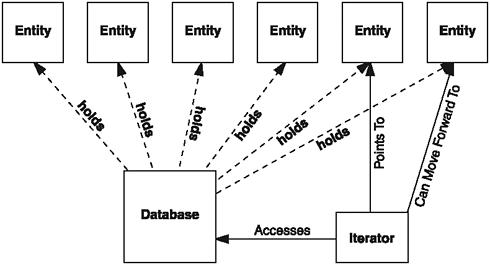
Figure 8.3 shows the basic concept of a database iterator and illustrates its relationship to a database. Iterators point directly to entities; therefore, accessing entities is an instantaneous operation.
Figure 8.3. Iterators can be moved forward to point to the next entity in the database.
Like the PlayerDatabase class from Chapter 6, "Telnet Protocol and a Simple Chat Server," the EntityDatabase class has the standard begin and end iterator functions.
NOTE
You may have noticed the odd change in the way I name functions for this class. I usually like my function names to be named as "Capitalize all important words," making functions like Begin , and FindFull . However, this class ignores that naming convention and makes everything lowercase. I do this for a simple reason: I want the data base class to look more in tune with the STL. Because a database is really just another data structure, it makes sense to use the same nomenclature .
While the PlayerDatabase class from SimpleChat could simply return iterators to its internal list, I can't quite do that here, since I'm using an iterator proxy class. That means that I must construct them first, using the contents of a map iterator:
inline static iterator begin() { return iterator( m_map.begin() ); } inline static iterator end() { return iterator( m_map.end() ); } As you can see, the database class simply mimics the std::map begin and end functions by passing their results into the constructor of the inner iterator class.
Searching the Database
There are numerous ways to search for and retrieve entities from the database, aside from using the iterator class.
ID-Based Lookups
ID-based lookups are the easiest ; they involve looking up an entity based on its ID. There are three of these functions: has , find , and get . The first lookup determines if an ID exists within the database:
inline static bool has( entityid p_id ) { return ( m_map.find( p_id ) != m_map.end() ); } Remember that the map::find function returns the same iterator as the map::end function if the key doesn't exist within the map, so if the two iterators are different, the key does exist, and true is returned.
The EntityDatabase::find function looks for an ID within the database, and returns an iterator pointing to the entity with that ID (or an invalid iterator if not found). This is done mainly for optimization purposes; if you look up an ID first to see if it even exists, and then look it up again to retrieve it, you're doing twice the necessary work. Instead, it's easier to get an iterator to the object, and then see if the iterator is valid. If you use this method, you can immediately use the value you looked up instead of doing it twice. Here's the code:
inline static iterator find( entityid p_id ) { return iterator( m_map.find( p_id ) ); } As you can see, the code simply wraps around the map::find function, because the map already knows how to search by ID.
The final function is the get function, which simply returns a reference to the data attached to the given ID.
inline static datatype& get( entityid p_id ) { return m_map[p_id]; } The function just returns a reference to the item with the ID you were looking for, but beware: If the ID you look up does not exist within the database, it will be created for you automatically. This means that a new entity is inserted into the database with only the default values (since you didn't fill it in). This could produce some interesting side effects.
Name-Based Lookups
You'll also want to look up entities based on their names. This becomes particularly useful when someone types in "attack Joe" in the game, and the game wants to find out who Joe is. In an effort to make the game easier on players, the game can also perform partial name lookups.
There are four name-based lookup functions: has , hasfull , find , and findfull . You'll notice that two of those functions ( has and find ) are also used for ID-based lookups, but I've overloaded the functions to take different parameters.
Because you're doing string-based lookups now, you can't just use a simple lookup in a map. Sure, you could store all the names within a map and have them retrieve the entities, but there's a serious problem with that method: You can't do partial matches using that method.
NOTE
There is a special data structure, called a trie , which is short for retrieval-tree (and there are holy wars fought over whether it's pro nounced "try" or "tree"). The trie data structure is specifically de signed for rapid string-based lookups using a special kind of tree. A special feature of tries is that they can also perform partial-matching quickly. Unfortunately , I don't have the time or space required to go into tries in more detail, so I'll leave that up to you to explore on your own.
To perform a partial name lookup, you need to perform a comparison on every entity in the database. Here's the has function, the simplest of them all:
inline static bool has( std::string p_name ) { return find( p_name ) != end(); } The function simply calls the find function to find a partial match to the given name, and then returns true if the iterator returned is not equal to end (meaning that the player exists), or false if they are equal.
The hasfull function is similar, replacing find with findfull :
inline static bool hasfull( std::string p_name ) { return findfull( p_name ) != end(); } find functions are interesting. Here's the first one, which searches for partial matches:
static iterator find( const std::string& p_name ) { return BasicLib::double_find_if( begin(), end(), matchentityfull( p_name ), matchentity( p_name ) ); } NOTE
To make the database classes more useful, they have been given two different name-based lookup methods . You can search for an exact name match (ignor ing case, of course) using the hasfull and findfull functions. But an Entity also supports partial matching. I considered making the database respond to requests to perform a straight partial match, but this leads to complications. Because of the method for searching the database, if you have two players in your database named "Johnny" and "John" (in that order within the database), whenever you do a partial search for "john", the database would always think you're talking about "Johnny", because that's the first person the database finds that partially matches "John". As simple as this sounds, it can be a nui sance to your users by making the real "John" totally impossible to reference. Therefore, I've decided to make the database's partial matching find and has functions first try to find an exact name match, and if none is found, then perform a partial match. This makes your life much easier. To do this, I've created a new STL-like algorithm function named double_find_if , and you can find that in the Libraries/BasicLib/BasicLibFunctions.h file. I'm not going to show you the code because it's just a simple helper function, but you should be aware that it acts just like std::find_if , except it has a fourth parameter: a functor that is used for a second pass, if nothing was found on the first pass.
The function makes use of my custom double_find_if function to perform a two-pass search on the database. First it tries to find a full match using the matchentityfull functor I showed you earlier; then it uses a partial match using the matchentity functor.
The findfull function is similar, but because it only needs one pass, it uses the standard find_if function:
static iterator findfull( const std::string& p_name ) { return std::find_if( begin(), end(), matchentityfull( p_name ) ); } This function just does a single-pass full match using std::find_if .
EntityDatabase Function Listing
Table 8.3 shows a listing of all the functions within the EntityDatabase class.
Table 8.3. EntityDatabase Functions
| Function | Purpose |
|---|---|
| iterator begin() | Returns an iterator pointing to the beginning of the database |
| iterator end() | Returns the "invalid" iterator, pointing past the previous entity |
| bool has( entityid id ) | Determines if an entity with id exists within the database |
| bool has( string str ) | Determines if an entity with partial name str exists |
| bool hasfull( string str ) | Determines if an entity with the exact name str exists |
| iterator find( entityid id ) | Returns an iterator pointing to the entity with id |
| iterator find( string str ) | Returns iterator pointing to entity with partial name str |
| iterator findfull( string str ) | Returns iterator pointing to entity with exact name str |
| datatype& get( entityid id ) | Returns reference to entity with given id |
| size_t size() | Returns number of items within database |
Vector-Based Database
The vector-based database class is pretty simple compared to the map-based database. Let me show you the class definition and data first.
Class Definition and Data
Here's the class definition for the EntityDatabaseVector class:
template< typename datatype > class EntityDatabaseVector { typedef std::vector<datatype>::iterator iterator; protected: static std::vector<datatype> m_vector; }; As usual, I've removed the function declarations, so you can see the data more easily. As you can see, it simply wraps around a vector.
The other interesting thing to note is that the class typedefs an std::vector<datatype>::iterator as its own iterator class. Remember how map iterators work and that they don't actually return the data stored in the map; instead, they return an std::pair<key,data> , which means that for iterators of maps, you'll have to use itr->second to access the data, and that's really annoying. Because of that, I created my own iterator class that would take care of that for you within the EntityDatabase class.
However, vector s are much easier to use, and because their iterators directly return the data, there's absolutely no need to create my own iterator class. Instead, an iterator for the EntityDatabaseVector class is really just a std::vector<datatype>::iterator . That makes things easier.
Functions
The vector-based database has a different purpose from the map-based database. A map-based database is often used to search for entities with sparse ID numbers (the IDs aren't continuous, and you could have IDs 110 and 91100 defined, but then have nothing defined for 1190), but the vector-based database is used more for storing data that needs to be quickly accessible, and won't change much. This means that things in vector databases are rarely added or deleted. There are just four simple functions in the database:
inline static iterator begin() { return m_vector.begin() + 1; } inline static iterator end() { return m_vector.end(); } inline static size_t size() { return m_vector.size() - 1; } inline static datatype& get( entityid p_id ) { if( p_id >= m_vector.size() p_id == 0 ) throw std::exception(); return m_vector[p_id]; } When introducing entityid s, I mentioned that the value 0 is always considered invalid. Unfortunately, vectors always begin with index 0, so you're going to have one " dummy " index, where there isn't valid data.
NOTE
If you're really concerned about wasting that one index, you could make the get function simply sub tract 1 from the index whenever it is called, thus treating the real index 0 as index 1, and so on.
The first two functions are iterator functions, which return iterators pointing to the first and one-after-last indexes in the array. Because index 0 is assumed to be invalid, the Begin function actually returns an iterator pointing to index 1.
Also, because one index is always invalid, whenever the size function is called, 1 is subtracted from the size.
NOTE
I could have used the vector::at function instead of my own version, but unfortunately, that was a late addition to the STL standard, and not all compilers support it.
The last function is the get function, which returns data at a given index. The function uses bounds checking, so if you try accessing an invalid index, an exception is thrown.
That's pretty much it for the actual database classes.
Database Pointers
Throughout the game, you're going to want to access entities within the databases. One easy way to do this would be to use pointers, but I usually recommend against this method. Many more advanced MUDs keep data on disk as much as possible, and only keep a few entities in memory at any given time. In such systems, when entities haven't been accessed for a while, they are automatically written back to disk and reloaded when they are needed again. As you can imagine, in such a system, entities are constantly at different addresses and are a pain in the butt to keep track of.
So pointers are out of the question. Because each entity has a unique ID number, it would make sense to store those throughout the game. Unfortunately, this is annoying in its own way; whenever you want to use the entity that the ID points you to, you'll have to manually look it up in the database class. Assuming there's an item database named ItemDatabase , this is how you'd do it:
Item& i = ItemDatabase::get( id );
That can tend to get quite tiresome after a while, so I've decided to create a databasepointer class. For all intents and purposes, this class will act just like an entityid , but will also have some overloads to make it act like a pointer to an entity as well. You'll see how this works in just a bit.
The relationship between a database pointer and an entity database is shown in Figure 8.4.
Figure 8.4. Unlike iterators, database pointers do not point directly at the entities, and they must perform database lookups to actually access an entity.
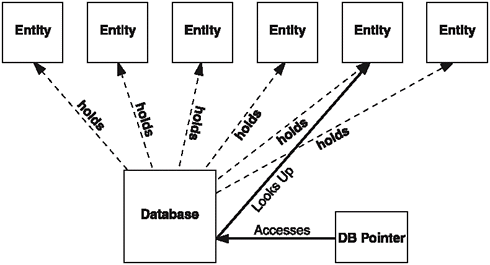
Database pointers are slower than iterators, because you must look up the entity in the database when you want to use it. This may seem like a bad thing at first, but it's very safe this way. Iterators can be invalidated if the database moves around too much (maps rearrange their structure when things are added and deleted), but a database pointer is always valid, as long as the database knows how to get it.
Unfortunately, C++ is a language that has inherited a lot of ancient quirks from C. One problem in particular is circular dependencies . If you are unfamiliar with C++, you can learn the details of the C/C++ compiler in Appendix C, which is on the CD.
The problem is that there are lots of circular dependencies connected with the database classes. Take, for example, players and rooms.
The player database needs access to the Player class. The player database pointer class needs access to the player database. Examine Figure 8.5 for a moment.
Figure 8.5. The player and room classes have complex circular dependencies.
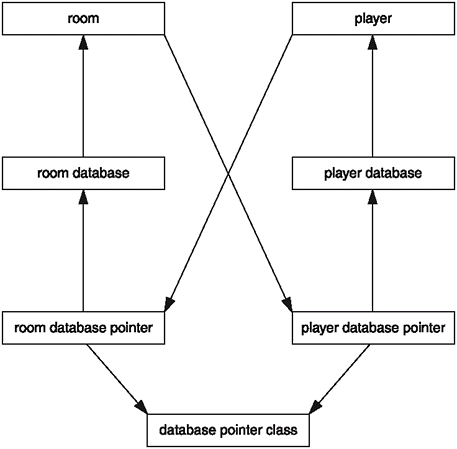
The relationship among rooms, players, their databases, and a database pointer class is quite complicated, and you might not even see the problem at first. Database pointers are extremely generic concepts, and as such, I would really like to implement them as a generic template class. Because of this, I've created the generic databasepointer class, which I will show you in a little bit. First I want to show you how I organized the files so that there are no circular dependencies. These are shown within Figure 8.6.
Figure 8.6. Files are organized so that circular dependencies are avoided. Notice that DatabasePointer.h doesn't point to anything.
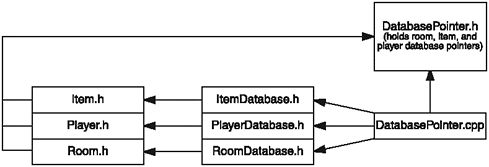
The important thing to note is that the DatabasePointer.h file doesn't have any links to other files; it doesn't include any of the other files shown in Figure 8.6. You'll see how this all works out.
Before Templates, There Were Macros
Unfortunately, despite the best laid plans of mice and men, templates just won't work for database pointers. The problem is that you can't mix cyclic dependencies with templates it's not going to happen in C++. Sure, you may get some compilers to do it for you, but those compilers aren't following the standard, and you really shouldn't count on that behavior.
Before we had templates and all of the great things they added, programmers had to rely on macros. If you've been properly taught C++, you might be feeling some shivers right now, but let me tell you; there is a time for ideals, and there is a time for reality. You could spend weeks and weeks trying to figure out how to get this done "the proper way," or you could put together a quick macro in a few minutes and watch it work immediately. It's up to you to determine which way is more "proper." I would wager that sometimes it's more proper to make a little hack to save yourself tons of wasted effort.
So the MUD has a macro named DATABASEPOINTER , which declares the functions of a database pointer (some of which are inlined), and another macro named DATABASEPOINTERIMPL , which contains the implementations of the functions.
Here is the declaration macro:
#define DATABASEPOINTER( pt, t ) \ class t; \ class pt { \ public: \ pt( entityid p_id = 0 ) \ : m_id( p_id ) {} \ \ pt& operator=( entityid p_id ) { \ m_id = p_id; \ return *this; \ } \ \ operator entityid() { \ return m_id; \ } \ operator t*(); \ \ t& operator*(); \ t* operator->(); \ \ entityid m_id; \ }; \ \ inline ostream& operator<<( ostream& s, const pt& p ) { \ s << p.m_id; \ return s; \ } \ \ inline istream& operator>>( istream& s, pt& p ) { \ s >> p.m_id; \ return s; \ } The declaration macro will take two parameters: the name of the pointer ( pt ) class, and the name of the entity class ( t ). For example, to create a database pointer class named player that retrieves Player entities (note the capitalization of the "p"), you would create it like this:
DATABASEPOINTER( player, Player );
The classes created by the macro are essentially just wrappers around a 32-bit entityid , which makes it lightweight, yet powerful.
You may notice that some functions are inline, yet others are not. There is a good reason for this: The inline functions don't need to access the database in any formthey simply operate on the m_id variable. The functions that aren't inline do access the database. This proves to be a problem, however. Because the database pointer header file can't include the database header files (circular dependency errors!), it can't know about the database classes. Because this file doesn't know about the database classes, you can't make inline functions access database functions; therefore, they must be placed within the .cpp file instead.
The first two functionsthe constructor and the assignment operatorare simple and just assign the parameter to the m_id variable of the classes, so I don't need to show you their code.
Conversion Operators
There are two conversion operators : operator entityid and operator t* . Conversion operators are an interesting feature of C++ that allows the compiler to treat a datatype as another type when needed.
The first conversion operator allows you to use database pointers just as if they were entityid s. Here's an example of using a database pointer as an entityid :
// this code assumes the existence of an "item" database pointer class: item ptr = 10; entityid i = ptr; // i is now 10. ptr = ptr + 10; // ptr.m_id is now 20.
See, isn't that cool? For (almost) all intents and purposes, database pointers are entityid s with added functions.
There's a reason I've included the operator t* function, which is the other conversion operator. This operator would allow you to treat a database pointer like a pointer to the entity you want to access. For example, you can treat an item database pointer as a pointer to the actual entity type, Item* .
I did this because of the two entity functors I showed you earlier: matchentityfull and matchentity . To save you lots of effort, these two functors can operate on containers holding just pointers to entities. But database pointers aren't exactly pointers; they're classes. If you didn't have this conversion operator, and you had a vector of item s, you couldn't use it in conjunction with the matchentity or matchentityfull functors, because they expect an Entity* , and this container holds item s.
NOTE
I said "almost" because there are times when database pointers don't act like entityid s. That's my fault; I'm lazy. You see, database pointers don't support the operators +=, -=, *=, /=, and so forth. To support those operators, you'd need to actually write them into the macro manually. The other option, of course, is to write things such as : ptr = ptr + 10; . The compiler accepts that, because it tries adding ptr with 10, and to do so, it converts ptr into an entityid automatically using the conversion operator, and then assigns the new value to ptr using the assignment opera tor. So just watch out for that.
This is where the conversion operator comes in. (This is actually within the DATABASEPOINTERIMPL macro.)
pt::operator t*() { \ if( m_id == 0 ) \ return 0; \ return &( db::get( m_id ) ); \ } This looks up the ID within the database and returns the address of the Entity that it found. If the ID is 0, the value 0 is returned. This is done because performing lookup on a nonexistent ID can cause the program to crasha bad thing.
Now you can freely use any STL container of database pointers with any of the functors.
NOTE
Remember that database pointers have a hidden overhead that regular pointers don't have. In this case, every call to the pointer conversion operator is an O(log n) algorithm on the map-based databases, as opposed to O(1) for regular point ers, so any O(n) STL algorithm you call on an array of database pointers automatically converts into an O (n log n) algorithm. For this reason, it is advisable to only use STL algorithms on relatively small containers of database pointers.
Dereference Operators
There are two operators within the macro that dereference the database pointer classes the macro creates, and allow you to use them just like pointers to entities (kind of like STL iterators). Sound cool? I think so, too.
The two functions are also declared inside of the DATABASEPOINTERIMPL macro:
t& pt::operator*() { \ return db::get( m_id ); \ } \ \ t* pt::operator->() { \ return &( db::get( m_id ) ); \ } \ These functions perform a lookup of the entity in the database and return references or pointers to that item. You can use these functions just as you would access any iterator within the game:
// this uses the "item" class again; I haven't shown it to you yet // but it's just a regular database pointer item iptr = 10; // make it point to item 10 iptr->Name() = "Sword"; // change item 10's name to "Sword" Item& i = *iptr; // make it a reference to item 10.
This way, you are not required to make your code look really ugly by performing manual database lookups; you let the pointer class take care of it instead.
Stream Operators
This isn't a huge topic, but I just want to mention it. Each of the database pointer classes has two stream operators ( operator<< and operator>> ), which simply stream the ID of the pointer to and from iostreams.
Defining the Macros
I showed you earlier how to declare a DATABASEPOINTER macro, but let me show you an example again:
DATABASEPOINTER( player, Player )
These definitions must be placed within the DatabasePointer.h file.
On the other hand, you declare the DATABASEPOINTERIMPL macros in the .cpp file, like this:
DATABASEPOINTERIMPL( player, Player, PlayerDatabase )
This macro takes three parameters: the name of the database pointer class, the name of the entity class, and the name of the database that holds those items.
| [ LiB ] |
EAN: 2147483647
Pages: 147