Credit Scoring System-The Bayesian Network Implementation
|
| < Day Day Up > |
|
Credit Scoring System—The Bayesian Network Implementation
The Bayesian model is a result of formal encoding of the domain expert knowledge, the factors influencing the phenomenon and their mutual interactions. The economic model being the objective of this paper has been created outside the system. Its aim is to analyze the standing of the enterprise from the point of view of its creditworthiness.
At first the primary goal is defining descriptive parameters of the model—the nodes of the Bayesian network. At this stage, the domain expert has crucial work to do. The topology of the network and its detailed nature is then specified. Unspecified parameters and lacking or misdirected connections between nodes result in inconsistencies of the model, ambiguity of causal relationships and finally inaccuracy of expertise.
The process of network structure generation, given nodes, can be boosted using dedicated computer programs. Statistical dependencies between model parameters support the expert to eliminate redundant inter-node connections, preventing non-convergence of propagation algorithms due to overloaded structure. The iterative generation process typically leads to a computationally tractable structure.
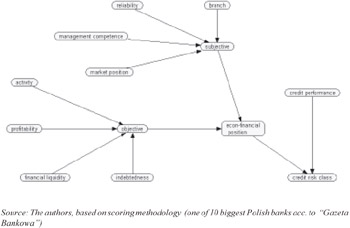
Figure 4: Bayesian network model of credit risk analysis
The next step, quantitative specification of model, requires filling up conditional probability tables. The computer-aided statistical analysis of historical data can reveal the strength of causal dependencies between nodes. During all procedures the domain expert can moderate the generation process.
The aim of the economic model we work with in this article is to analyze standing of an enterprise from crediting banks' perspective. We defined nine groups of factors (i.e., scope of analysis) used to classify customers according to credit risk level.
It should be pointed out that directions of links between nodes are consistent with discovered causal relationships. Figure 5 shows synthetic nodes only. In reality the network is built up with some dozens of nodes setting up a hierarchical structure. Due to its complexity we show only part of the structure related to "creditability of entrepreneur" and "management quality."
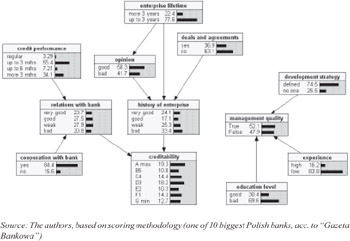
Figure 5: The detail of Bayesian network relating to "creditability of the enterpreneur" and "management quality"
The network shown in Figure 6 has not been initialized, i.e., no data are put into the system, yet. Probability distributions come from statistical analyses of historical records or/and domain expert estimations.
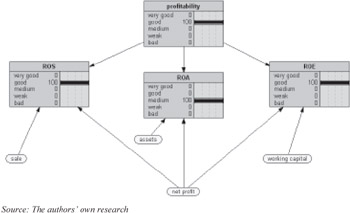
Figure 6: Evaluation of economic-financial condition of the enterprise—"profitability" section
Tables of probability distributions are equivalents of "normative scoring tables," and in both systems value range and discretisation of random variables are identical.
When deterministic dependencies between nodes were declared in Bayesian system (we use for this purpose square-shaped 0/1 probability distributions) we got classification strictly identical with that obtained in scoring tables methodology. As an example, the ROI evaluation given in "Building a Credit Scoring System" is revisited and results are presented in Figure 6.
Finally, a synthetic credit-risk evaluation referring to the example given in "Building a Credit Scoring System" is presented in Figure 7.
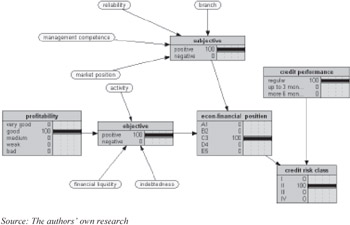
Figure 7: Evaluation of synthesized credit-risk level based on financial and economic analysis of an enterprise
Qualitative subjective factors are modeled with the Bayesian network (structure shown in Figure 8). It can be seen that the network is initialized using factual information regarding "subjective" node.
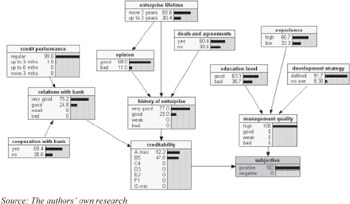
Figure 8: The subnetwork that models influence of subjective factors on credit risk evaluation
After propagation procedure, the network reaches equilibrium state. Then, the readout of probability distributions delivers diagnostic statements about probable cause of subjectively good condition of the enterprise. As it was already stated, the quality of diagnoses is determined by correctness of network structure and conditional probability tables. Table 12 shows an example of tabularized probability distribution, referring to "quality of management" statistically dependent on "education," "experience" and "strategy of development." "Quality of management" can be found (with different probability) in one of the states: "high," "good," "poor," "bad" and, for instance, "strategy" in"defined" or "none."
| Quality of management | ||||||
|---|---|---|---|---|---|---|
| education | experience | strategy of development | high | good | poor | bad |
| good | high | defined | 1 | 0 | 0 | 0 |
| good | high | none | 0,2 | 0,3 | 0,3 | 0,2 |
| good | small | defined | 0,7 | 0,15 | 0,1 | 0,05 |
| good | small | none | 0 | 0,15 | 0,15 | 0,7 |
| poor | high | defined | 0,75 | 0,15 | 0,1 | 0 |
| poor | high | none | 0,05 | 0,1 | 0,15 | 0,7 |
| poor | small | defined | 0,3 | 0,45 | 0,15 | 0,1 |
| poor | small | none | 0 | 0 | 0 | 1 |
| Source: The authors' own research, fictitious data | ||||||
The presented Bayesian network has the property of making coherent inferences and diagnosing also when only incomplete information is available. Its natural feature is being susceptible to iterative refinement made by supplying updated distribution tables, new connections or nodes. Acting in the world, where great repositories of historical data are still growing and becoming easily accessible to the banks, we believe that it is feasible to build a robust system that gives statistically sound expertise and is not confined to bare tabular procedures. Other than quite popular neural networks, Bayesian networks supply explanations to given diagnoses or prognoses.
| Bayesian network | Scoring-table method | |
|---|---|---|
| 1 | Imprecise information is accepted by the use of random variable distributions | Exclusively deterministic evaluation of factors possible |
| 2 | Incomplete data are accepted | Incomplete set of input data is prohibitive for further analysis |
| 3 | Both backward and forward reasoning possible - diagnosing in Bayesian networks reveals „weaknesses" of an applicant and can suggest areas of in-depth analyses | Diagnosing possible causes of an effect is not possible |
| 4 | The model can be verified using real-world data | No empirical verification possible |
| Source: The authors' own research | ||
Their outcomes are not so vastly conditioned by size and completeness of data sets, as in the case of neural networks.
On the other hand symbolical methods of information processing (although of long tradition and sharing 85% of applications market) are bad performers when noisy information is input to the system. Rule-based knowledge representations are hardly modifiable; searching through a rule base is computationally intensive and time-demanding.
For instance, a rulebase with 2,000 records is considered to be huge.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174
- Challenging the Unpredictable: Changeable Order Management Systems
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- Context Management of ERP Processes in Virtual Communities
- Distributed Data Warehouse for Geo-spatial Services
- Development of Interactive Web Sites to Enhance Police/Community Relations